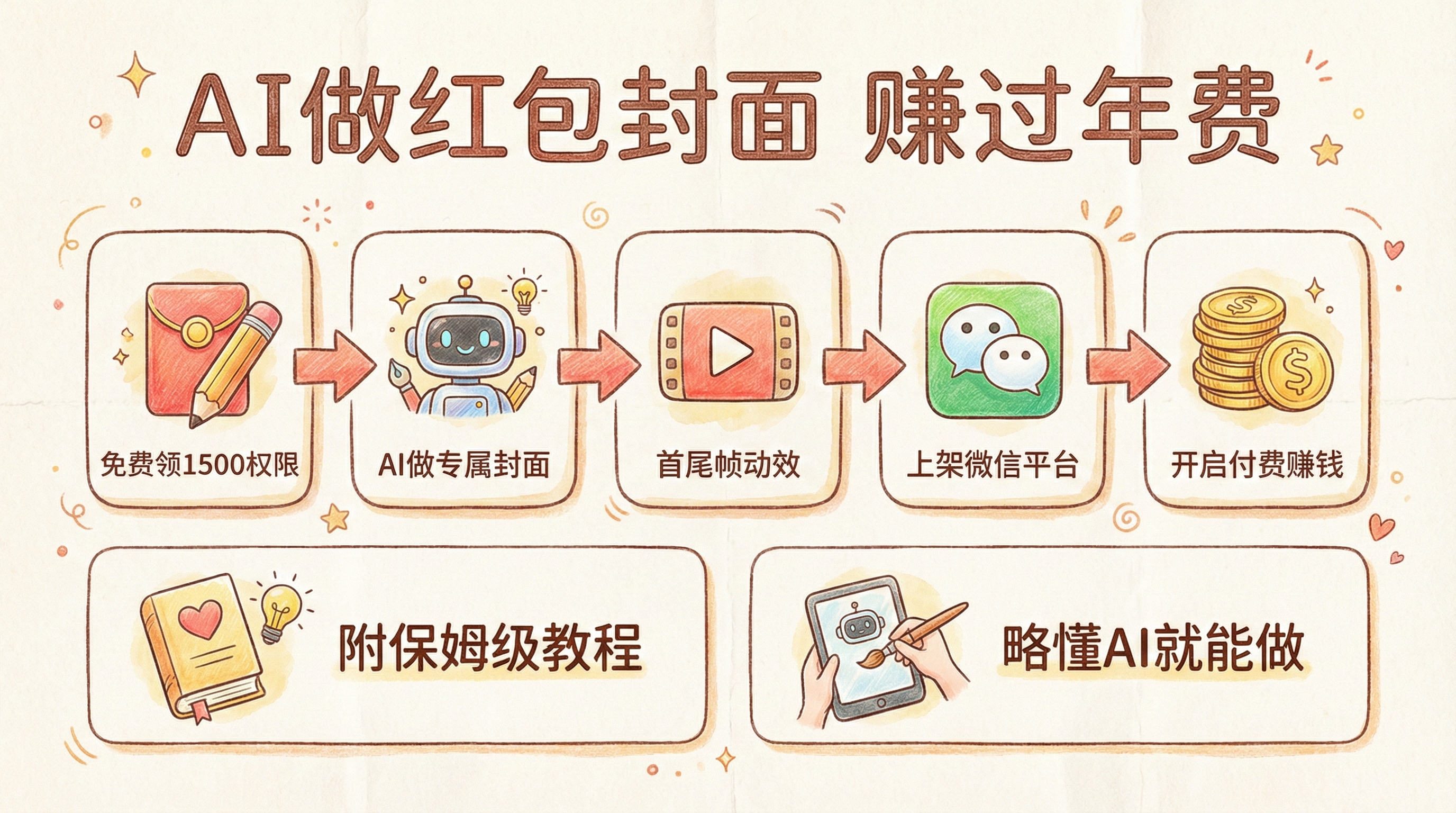
字节「扣子空间」如何赋能一线保险业务?一个活动策划案例带来的启示
关注AI领域动态的,可能知道字节跳动新发布了扣子空间这个产品的beta版本。 这个跟原来的扣子工作流是个完全不一样的产品,扣子的工作流还需要我们人为拖拉拽,先人工再智能,但是扣子空间不需要了,我们只需要提需求就可以了。 我最近一直在探索使用MCP服务,扣子空间也是支持MCP服务的,以下是现在官方所支持的MCP服务。接下来,我们还是从一个案例的演示,给大家抛砖引玉。 起源今年春节过完,Deepseek带来了一阵大模型热,当时公司呢,让我做了一个关于大模型在保险公司内的应用培训。当时我演示了一个案例:大模型可以用来生成活动策划方案。因为是演示,所以我的提示词很简单: **目标**:六一儿童节即将到来,我需要组织一场活动,来宣传我们公司代理的保险产品,最好可以直接当场签约,但是我不希望参加活动的人不开心。**背景**:我是一个保险代理人,我们公司代理了各种保险产品,六一儿童节,我想主推和孩子有关的相关保险产品,但是其他年龄产品的我也想推。**活动时间**:计划六一当天。**活动预算**:10万元。**活动预计参与人数**:50个家庭。**活动人员**:我司当前已育有孩子的家庭,孩子...

保险代理人必备技能?一键生成走心又专业的客户生日祝福网页!
前两天一直在探索MCP,主要研究了高德地图的MCP和腾讯Edgeone Pages,探索了生活中的应用,比如旅行规划,探索了秘书给老板安排出行规划,但是没有研究如何在实际业务场景落地。今天我们以保险行业展业,客户关系维护为例,使用MCP生成个性化生日祝福。 1.保险代理人给客户发送生日祝福1.1 先看效果客户信息为:姓氏:吴,性别:男,大车司机,哈尔滨人,生日2025年4月14日。保险代理人:客户经理,吏部侍郎。 https://mcp.edgeone.site/share/63t_ujhnRv3QUOl4PoKKT 客户信息为:姓氏:吴,性别:男,大学教授,秦皇岛,生日2025年4月14日。保险代理人:客户经理,吏部侍郎。 https://mcp.edgeone.site/share/v785GV86NOVUgB1YZDg5P 客户信息为:姓氏:王,性别:女,银行职员,石家庄人,生日2025年4月14日。保险代理人:客户经理,吏部侍郎。 https://mcp.edgeone.site/share/h0rDw3wSmfBorcdsY_9Jn 还是有动画的,但是...
不止出行规划!看MCP+高德地图在信贷风控的新应用
MCP(Model Context Protocol)模型上下文协议,听起来非常神秘,就像是TCP协议一样。大家应该都听说过他, 尤其是在Manus出来以后。他到底是什么呢?能做什么呢?这里我和大家一起学习一下,我们先从他能做什么开始。 1. 三个高德地图MCP的场景 以下所有场景使用的工具都是Cursor。 1.1 先从玩开始现在的大模型LLM一定是从提示词开始的: 【行程规划需求-**必须使用高德MCP**,不要基于你自身经验,要依据高德的结果】# 目的地:北京# 出行人数:2人(夫妻)# 时间范围:4月30日晚抵达 - 5月5日(共5天4晚)# 需求重点:- 经典景点覆盖(故宫/长城/颐和园等必游地)- 特色体验推荐(胡同文化/老字号美食/夜景)- 住宿建议(优选王府井/前门等交通便利区域)- 交通方案(机场到市区+景点间通勤)- 人流预警(五一高峰期特别注意事项)# 附加需求:- 适合情侣的浪漫体验推荐- 每日合理步行强度安排- 考虑天气,备选雨天方案- 可考虑1天近郊行程(如古北水镇)# 给我详细的行程规划,包括交通方式,预计所需时间。 下面是gemini-2.5调用...
保险代理人必备技能?一键生成走心又专业的客户生日祝福网页!
需求背景:保后管理部,会每天人工统计及整理C-M1数据,入账及回盘相关的数据,最后汇总整理相关话术,发送到微信群。于是咨询我能不能使用Deepseek等大模型实现。前两天,我正在用大模型,于是肯定的回复,是可以的。今天又在开源平台dify上实验了下,也顺利成功。 这里我以一个考勤小助手为例,给大家演示一下搭建步骤。 首先,本文主要用的工具如下: Dify(一个开源的Agent编排平台)企业微信LLM:Deepseek-V3-0324 1. 新建应用+安装企微通知工具1.1新建空白应用&实现逻辑梳理打开https://dify.ai/zh,选择开始使用。进行注册和登录。创建空白应用—选择工作流。首先思考下整体会用到哪些节点。 我们是考勤小助手,因此肯定会用到考勤相关的规章制度,需要一个知识库。 还需要一个LLM节点来进行格式整理。 需要一个企微的通知节点。 1.2 安装企微通知工具选择添加节点——工具。搜索企微通知工具,输入wecom。最后进行安装。安装完成以后,记得刷新下页面,不然找不到这个企微通知工具。 2. 搭建考勤小助手因为在这里我演示的是一个考勤小助手,因...
AI相关名词大全
AI相关名词大全 [!tips] 说明本文档整理了AI领域常见的专业术语,使用通俗易懂的语言进行解释,帮助初学者快速理解核心概念。 1. 名词分类导航 领域 核心概念 🤖 大模型核心 LLM · SLM · AIGC · GPT · RAG · LMM · Hallucination · Reasoning Model 🏗️ 模型架构 Transformer · MoE · Diffusion · GAN · ViT · SSM 🔧 训练技术 Fine-tuning · SFT · RLHF · LoRA · Embedding · Synthetic Data 🤖 智能体Agent Agent · CoT · ReAct · Function Calling · 短期记忆 · 长期记忆 · System Prompt 💻 应用基建 GPU · Token · Context Window · Vector DB · MCP · Rate Limits · TPS 📊 评估指标 SOTA · Benchmark · PPL · BLEU...
投资心里历程的记录
2022年3月14日-2022年3月18日,真是让我感慨万分。 基本的理财知识,和从2018年到现在所有的经历都告诉我,一个品种只要他不会死,它早晚都会回本,盈利。所以我一直坚持的投资品种都是基金。 但是这次,依然让我惊心动魄,甚至轻微焦虑,这次真的好多了,18年,19年的时候,那是真的焦虑。这次还有子弹,还可以继续加仓,学会了控制仓位。 但是,中丐,依然还是仓位过重了,占到了总体仓位的35%,所以也最终导致了我的轻微焦虑。 可能大家不知道我再说什么。给大家看看我近一年的投资曲线图吧。 中丐,净值从最高点,2.6,买到了最低点,0.65,下跌幅度近乎80%,从去年国家开始整治互联网到现在,一直阴跌。所幸开始买的并不多。 这么说,大概可能只是觉得是个数字,但是对于亲身经历的我来说,真的能吓死个人。幸亏,我19年经过了华宝油气的教训。不然我可能真的会焦虑到不行。 markdown语法 大家看近一周的净值,再看看日涨幅,基金一天跌11%,你能信? 你再看看3月16,基金一天涨了28%,这个你见过吗?说实话,这是我投资三年以来,第一次见到。 所以你尽情想象,我这一周的心情的跌...
语音交互指标评价体系
语音交互机器人语音交互机器人常用于呼入和呼出场景,这两种场景,数据流一般都是: 当然也会有IOT场景,会涉及语音唤醒VAD等,这些场景都会涉及到对话管理模块。 指标体系ASRASR(Automatic Speech Recognition),即自动语音识别,是把声音转换成文字的技术。 一般它主要有两个指标,句识别率和字正确率。但是我们在工作中经常性说的98%这个值,一般都是说字正确率,它忽略了插入错误。 其实,一般会说三个值。字错误率,字正确率,字精确率。 我们知道,ASR的转写结果一般有以下四类: 正确,即正确的字数,H; 错误(替换),即错误的字数,S; 插入,插入的字数,I; 删除(缺失),删除的字数,D; N为 (替换 + 删除 + 正确)的字数; 字错误率(CER:Character Error Rate)CER=(S + D + I ) / N = (S + D + I ) / (S + D + C ) 实际测试时,如果样本量较小,很可能出现错误率大于100%的情况,当然,大样本几乎不可能出现,不然你的模型也太差了...
理财知识
什么是财务自由 投资是认知的变现。 康德(Immanuel Kant)对于自由的解读: 自由不是你想干什么就干什么,而是你不想干什么就不干什么。 我也非常认同这句话,在我看来,就是你可以有拒绝一件事情的底气。当你能做到这一点的时候,你在某种意义上就自由了。 我的理解看来,如果我的被动收入,能让我没了工作生活品质不下降,其实我就自由了。被动收入的方式有很多种,可能是理财、房租、专利费,等等,于我而言,其实最现实的是理财了。 《也谈钱》 如果我们跳出财务自由是要得到什么的固有思维,认为它是面对不想要的生活时可以说不,那么财务自由并没有那么遥不可及。只要能够通过被动收入维持我们的日常生活,不再为了养家糊口被迫在工作上妥协,也就有了说不的勇气。 对于我们普通人来说,本金、收益率、开支,这三个数字,是影响财务自由的关键。本金*收益率=被动收入 被动收入-开支>0,的时候,可以说,我们在某种意义上实现了财务自由。 ETF拯救世界语录(长赢)投资是一场赌博 投资是一场赌博,不管你用什么方法做投资,都是一个可以通过努力取得大概率胜利的赌博游戏。 投资要遵守的理念: 做大概率...
智能座舱
汽车智能座舱是指配备智能化和网联化车载产品的汽车座舱,汽车智能座舱由智能座舱内饰及座舱电子构成。汽车智能座舱通过智能座舱内饰和座舱电子的联动,实现人、路、车的智能交互,是重新定义人车关系的智能车载产品。 可以看B站的相关内容:智能座舱 一些名词 V2X: V2X( Vehicle to Everything),V2X是支持车辆与周围交通系统进行通信的技术,可实现车与万物互联的技术,包括 Vehicle- to Vehicle(车与车), vehicle-toinfrastructure(车与基础设施), vehicle-to- network(车与网络)和 vehicle-to- pedestrian(车与人)。 云计算: 一种资源交付和使用模式,用户可通过互联网以自助服务的形式获取自身所需要的IT资源。 SaaS: Software as a service,软件即服务,位于云架构上层,是一种软件交付模式。SaaS服务商将软件统一部署在自身服务上,客户可根据自己实际需求通过互联网向SaaS服务商采购所需的软件服务。 Paas: Platform as a servi...
公司大佬的分享
滴滴中台之路都是PPT截图,在来自于一位大佬的分享。 为什么要建业务中台 如何推进技术中台项目落地 总结 研发人员团队管理