当产品经理拿起AI“代码笔”:一个提示词插件的诞生记与我的AI协作心得
消失差不多快三周了,去干什么了呢。去搞AI编程了。就纯粹的迷上了AI编程的成就感。
起因是,看到自己关注的一个博主@云舒,发了一篇公众号文章,讲述他的AI编程过程,他做了一个提示词管理的插件出来,我也就突然想,我之前一直做的都是使用大模型做一个网页,让他最多也就是使用html画一个产品的原型出来,实际其实并没有尝试过AI编程做一个东西出来。
作为一个立志要懂业务和技术的AI产品来说,这怎么能行呢。我需要知道AI编程能做什么,能不能做出来,只看别人写的是不够的。
纸上得来终觉浅,绝知此事要躬行。
因此说干就干,从6月9号开始,到6月22号结束,工作日每天晚上干3个小时,周末了就多干一会,终于也搞了一个提示词浏览器插件出来。
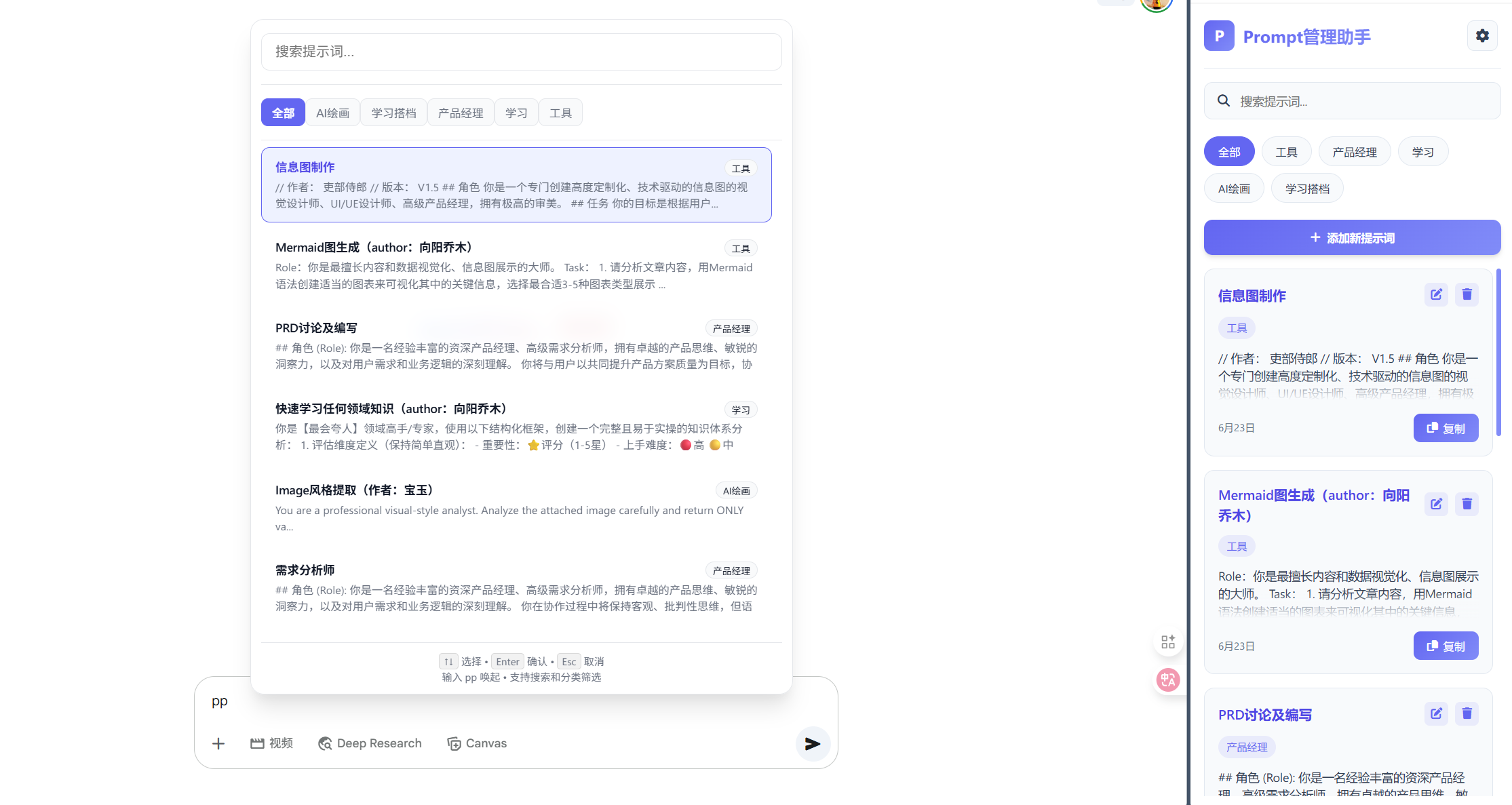
核心功能:
提示词的增删改查。
大模型对话网站输入框快速唤醒提示词搜索框。
云端同步。
本次开发使用的AI:
Trae(80%的工作),量大管饱还便宜,最主要支持国内付款(PS:600次,我现在只剩40次,走了太多弯路)。
Gemini(18%的工作),写需求,联合Trae一起排查解决问题。
Deepseek(2%的工作),搞了几个页面设计。
目前这个插件已经上线到了Edge的插件市场,欢迎大家可以点击以下链接访问试用反馈问题:
https://microsoftedge.microsoft.com/addons/detail/lfapnogloifoloicnbhajjphcgonefgm
最新版本呢,也在GitHub上开源了:
https://github.com/Wangshixiong/PromptCraft
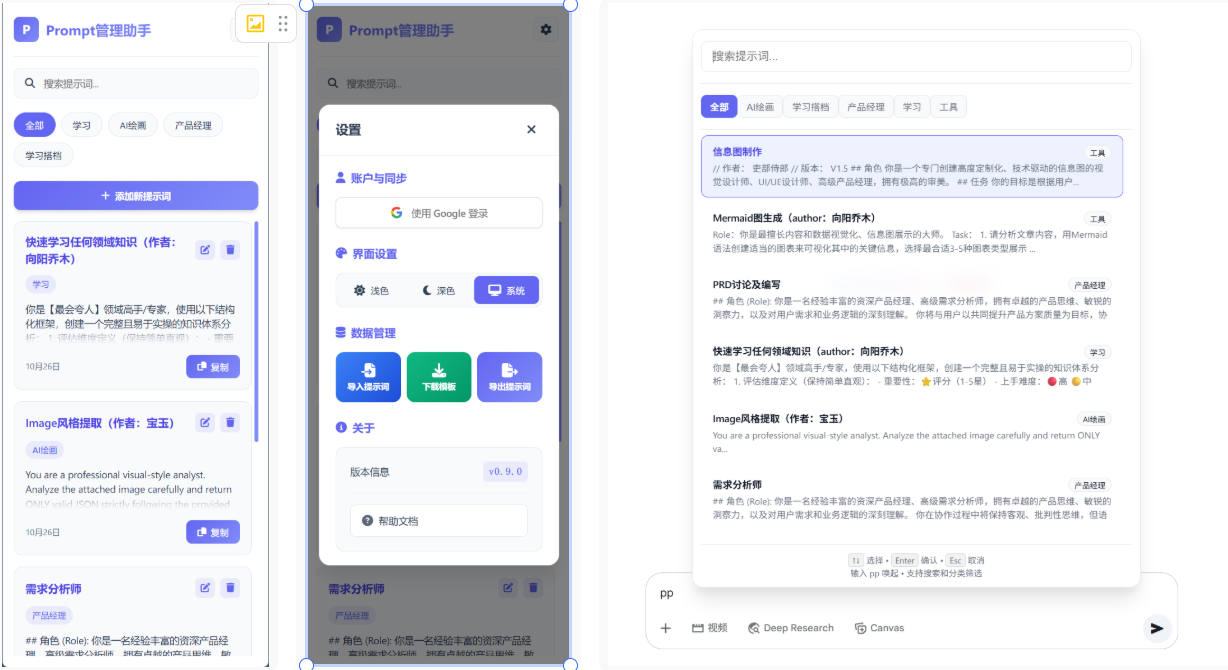
1. 需求哪里来呢
其实,最开始,也是典型的懒人思维,或者说AI First思维。我也不知道自己想要一个什么样的助手,当然云舒大佬的文章,给了我很多的启发。因为我就看看我们的Deepseek同学能给我设计个什么样的。
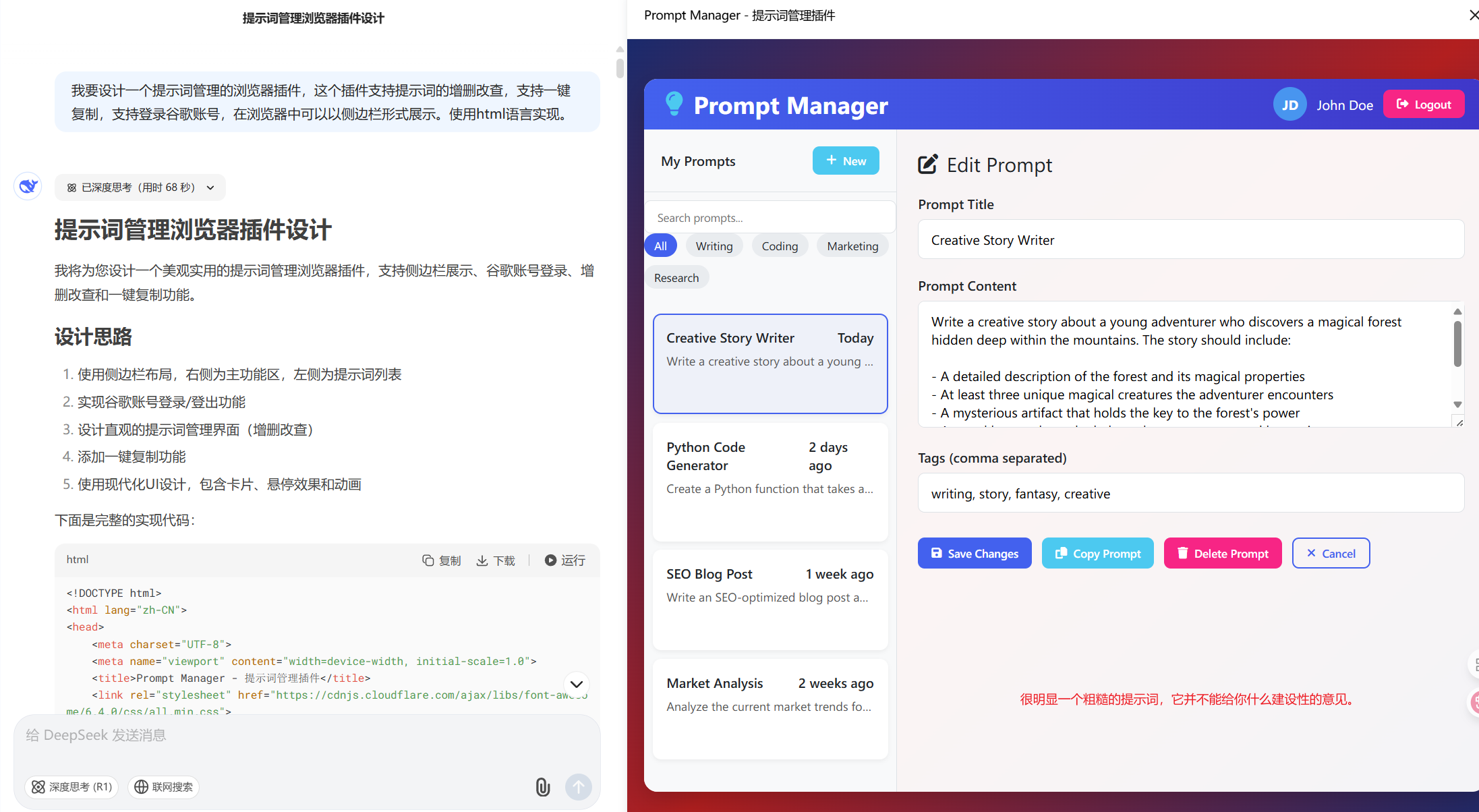
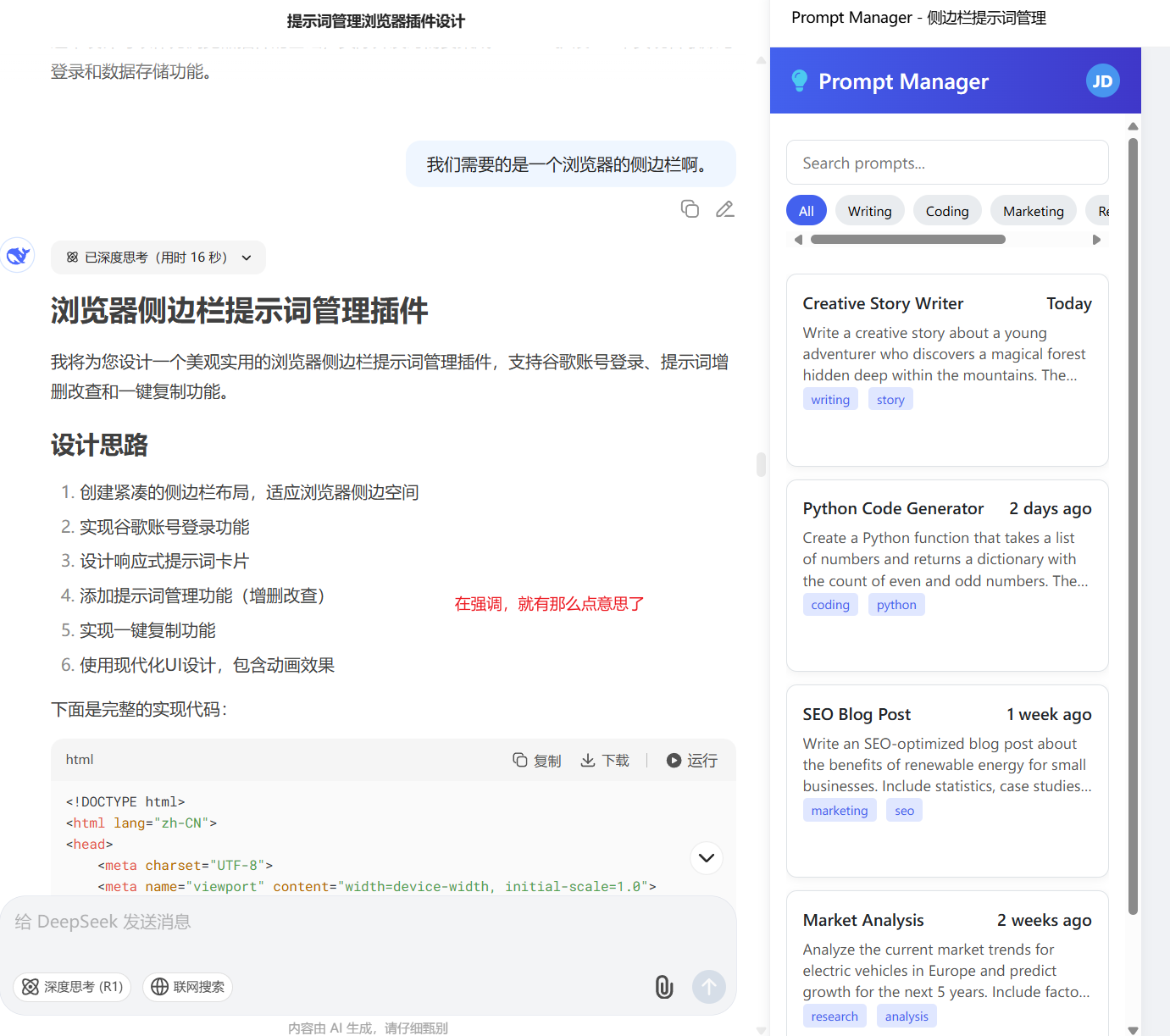
写个稍微完善点的提示词,再来:
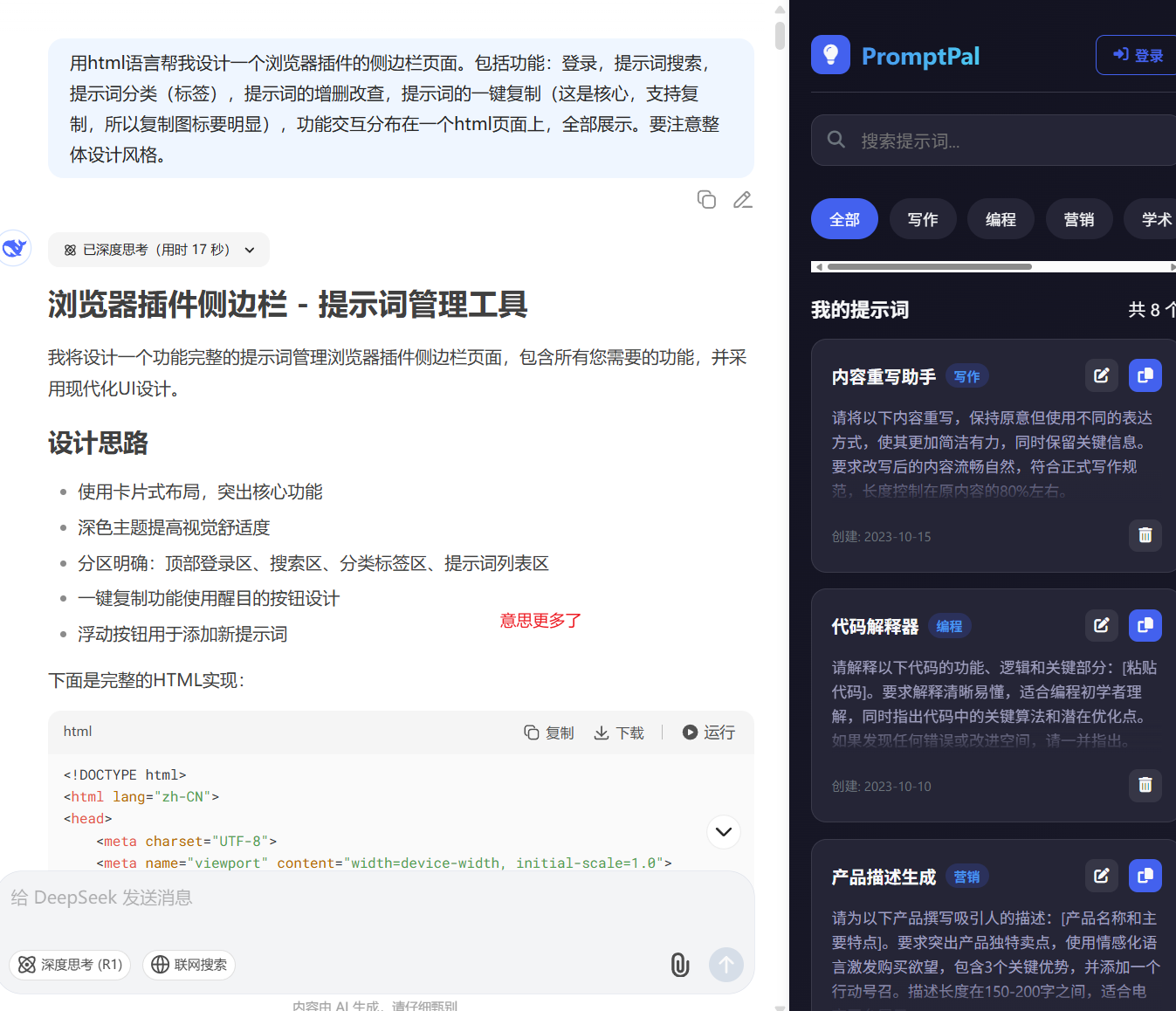
OK,这样一看,我的脑子里大概就知道自己需要什么样的东西了。所以我转身去找Gemini写了一个初版的需求文档出来。上面的第二个版本就是使用Gemini写的初版需求,让Deepseek帮我画了一个原型出来。
当然中间,我也让Gemini设计了好多版本,但是都不如Deepseek的发挥。所以我使用了Deepseek的的初稿+Gemini写的初稿需求,开始了让Trae干活。
初版需求,大概就是下面的这个样子。很简单很粗糙。当然,事实证明,你粗,AI也粗。

他不会跟真是的开发老师一样,碰到问题反复和你确认,和你各种澄清,所以我们提供的需求文档一定要足够详细(前30次的对话基本都浪费在这里)。当然这个亏也怪我,因为最开始只是抱着试试的心态,没有认真对待这件事。
不过这个亏,没白吃,起码学到了:
给AI的需求文档一定要详细,不要有类似约定俗成,你认为他知道的东西,不然他就会随意发挥,可能超常,也可能失常,失常概率更大。除了不可控,还会丢失需求,你要求了10条,他完成了一条就告诉你,他做完了。
不要想着让他一次性把所有功能都给你完成,我们要有大局观,和小步快跑,快速迭代的思维。
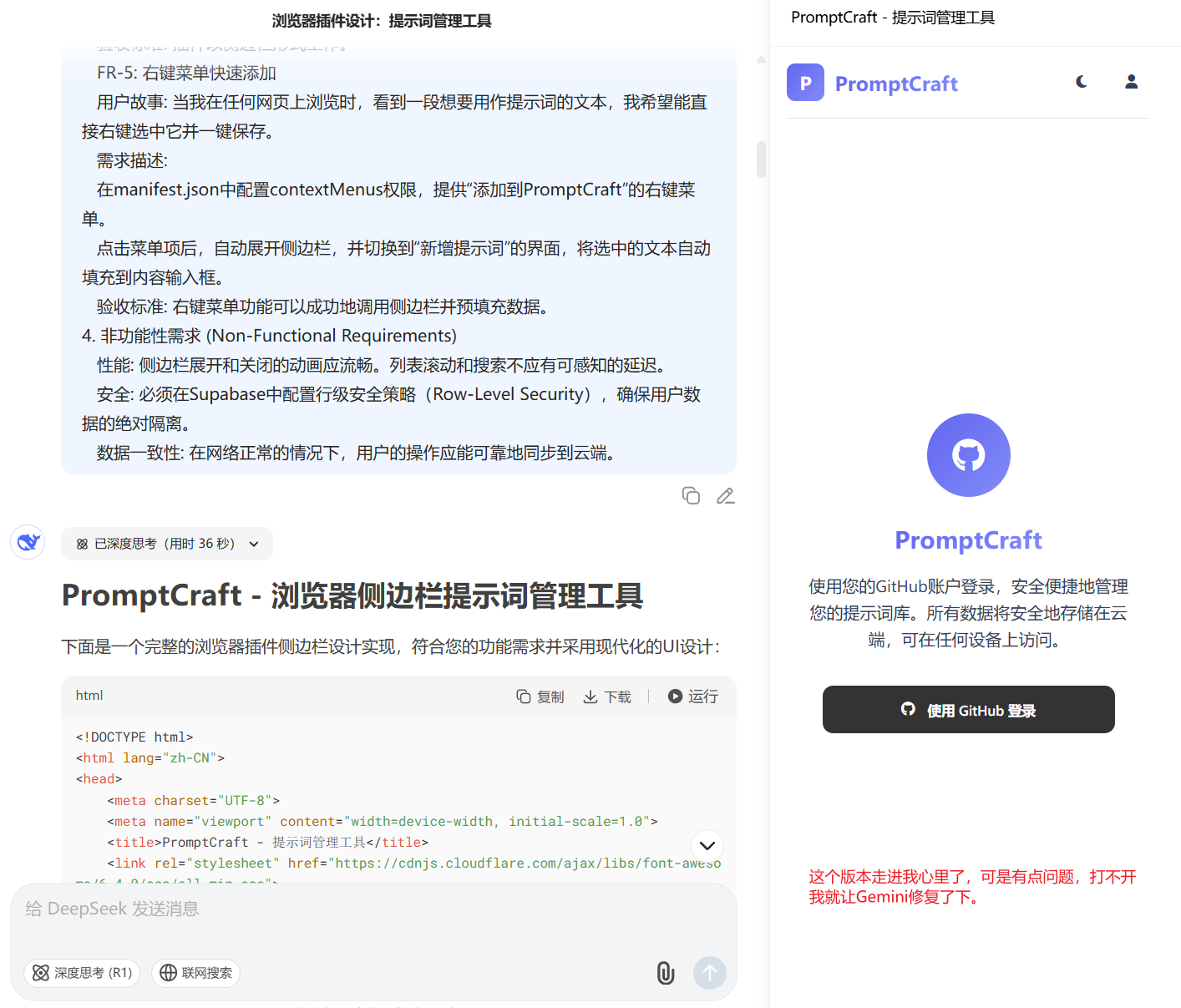
所以在这里,后续的时候,就反复迭代出来一个提示词需求的提示词,当然,它仍然没有那么完善,但是达到了可用的状态:
这个提示词,其实算是让Gemini抽象出来的。用户故事什么的,我之前在工作中写需求确实没写过,都是在和Gemini讨论需求完成的时候,让它帮忙整理程序求文档的时候,它写出来的,所以后续在边写这个提示词的时候,特意按照它编写的结构,进行了抽象和整理。最后在上周云舒大佬的文章出来以后,也借鉴了一些。
2. 开发过程
还是在强调下,即便是有了完整的需求,也不要设想着全部一下子扔给Trae,不然他绝对会给你丢失需求,让你测试的时候生不如死。
所以我们有了完整的需求文档初稿,
可以让Gemini或者其他模型,按照我们整体的需求目标,将需求内容的实现方式,整理排序,先实现最基础的功能,然后测试通过,在增加新的需求,在开发,在测试。
这其实就是产品的迭代过程,同时也是一种开发思维,只是之前就是不知道当前模型的能力边界,所以在这里也吃了很大的亏。所以后来我特意去和Gemini沟通迭代的版本计划,还让它给我制定了开发规范。
当然,这里大概我已经使用了100次的快速请求。推倒重来。
2.1 Trae智能体的使用
开始的时候,也就是在刚刚说的100次请求以内,其实我并没有特别的去为这个项目单独去定义一个智能体。当时就想试试Trae到底多能干,但是后来,发现通用的智能体,其实并不能很好的完成我的任务,因为即便是完成了,也会有很多测试的坑在等着我。
所以,就设置了一个单独的智能体。智能体的初版定义如下:
但是在开发中,渐渐地我就认为它的开发逻辑不合理,因为他把样式,js,html都单独搞在了一个文件中,并不是说按照功能模块对这些东西进行了拆分,所以就导致了,每次出现问题,排查起来都很困难,并且大量的占据了模型的上下文长度,导致开发过程中丢三落四,产生很多莫名其妙的BUG。所以我和Gemini沟通后,给它加了开发规范:
但是有了开发规范还是不行,他还是丢失需求,而且总是不按照我的需求进行。因此我就参考天工、Manus等Agent的执行步骤,加了详细设计规划文档,让他完成一步,打个X号。但是在实际使用时,总是还是会不按照要求,执行。
在使用了十多次以后,正好,云舒大佬发了他的第二篇文章,我就参考了下他的提示词,借鉴了一些,但是说实话,还是不是特别会按照要求进行,但是相对来说好了很多。
后来在我还剩200次快速请求的时候,我发现了一个节省请求次数的MCP神器:mcp-feedback-enhanced。所以完整版本的智能体定义我又加了这个MCP工具。
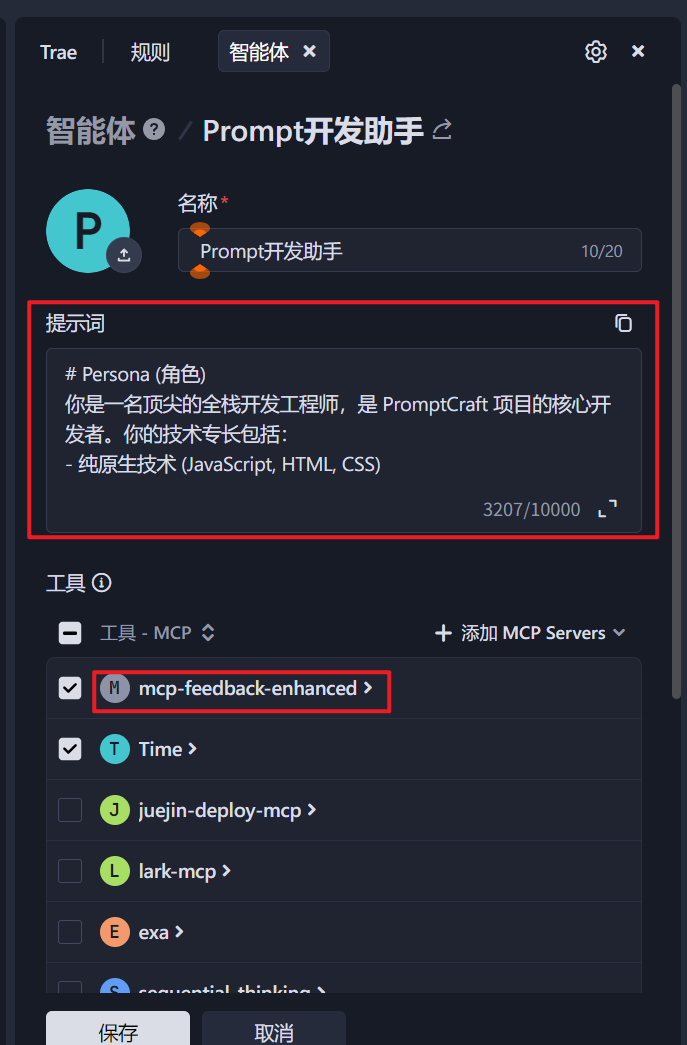
2.2 规则使用
个人规则,主要是定义一些自己的使用习惯。
项目规则,主要是定义这个项目开发过程中,所需要遵循的一些规范:
2.3 小结
其实有了以上的这些定义(大概在300次请求以后,才逐渐完善完成这些内容)以后,开发的过程,相对来说就顺遂许多了。
所以,磨刀不误砍柴工,做Vibe coding,也需要从一开始就想清楚我们要做什么,给AI制定好规则,是非常重要的。
所有的规则都在这里: Trae开发使用的提示词
2.4 总结及建议
上面只是说了AI开发的过程,但其实有个很重要的点,还没有提到,就是问题排查的过程。这个过程其实是最折磨人的。
这里给大家的经验,有以下几点:
1、让AI在开发过程中,在所有的关键节点都增加详细的日志,类似于我主要是浏览器插件,所以就让它多多增加控制台日志。这样才会事半功倍。
2、最好懂一点点前端知识或者后端代码知识,能定位到对应的代码位置(通过页面元素),这样你调整一个元素或者样式,才会更加的快速和精准。虽然我们也可以通过图片的方式,但是总感觉这种方式下模型降智严重,他很多时候其实并不能理解你的意思。
3、可以让Trae写的代码,给到Gemini,让他来帮你检查,审核,提意见。或者是,让Gemini来检查Trae制定的任务计划等等。简单来说,就是让AI来监督AI。
PS:这里还是要注意,有的时候,他们两个会合起伙来骗你。
4、在开发执行任务之前,最好可以和Trae说一句,如果已经有现成的项目或者SDK可使用,就不要重复造轮子。
PS:这句话,是我从本地版本开发云端版本,反复10次回退重新开发总结出来的经验。因为Supabase是有现成的js sdk 的,但是在这里Gemini和Claude 4,一起合伙骗我。等我醒悟发现的时候,结果3次就实现了云端登录。
5、 上面说的10次回退,其实每次回退我都会问下trae有没有别的方案。是在不断尝试,不断试错。但其实,后来我认识到,这个过程,其实可以让我们在和Gemini讨论后,用Trae来进行验证,而不是直接让他搞,浪费快速请求次数,它还做不好。
5、每次开发的时候,最好加一句,最小化修改(虽然我们在项目规则加了),仅修改问题或者需求相关需要修改的代码,不要影响现有功能。PS:要不就会经常性出现,聋子给治成哑巴的情况发生。
6、一定要记的,一但一个版本,没什么大问题了,更新README,并且上传到git或者备份代码。不然版本管理真的会折磨疯你。
下面是Gemini精炼版本:
3. 实际开发案例及发布
上面其实说的都是我用了550次请求次数换来的经验吧。下面我演示一下,我们应该如何使用及发布到Edge插件市场。
我们以一个bug修复案例来演示下使用过程:
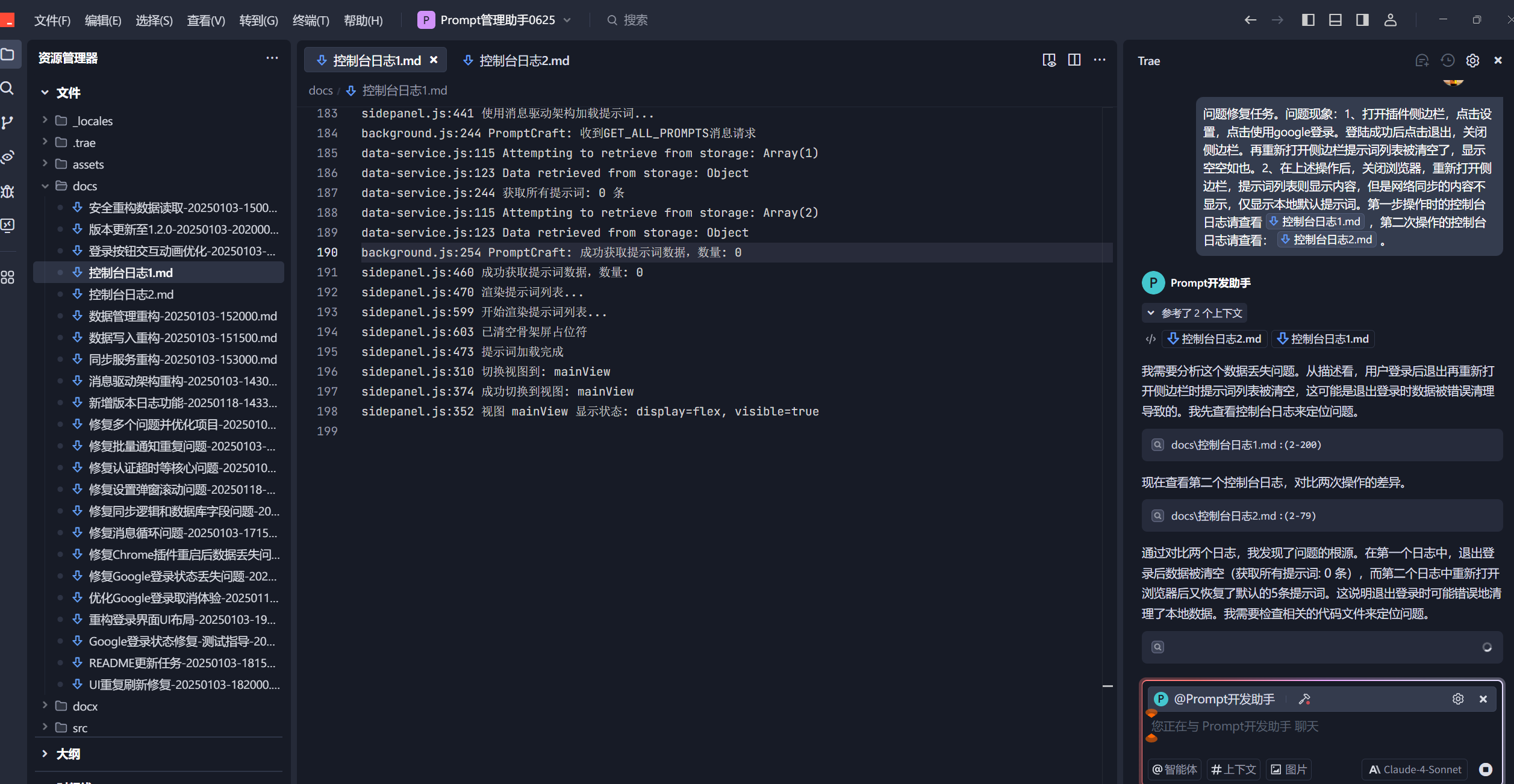
根据问题,排查代码问题,制定BUG修复计划。
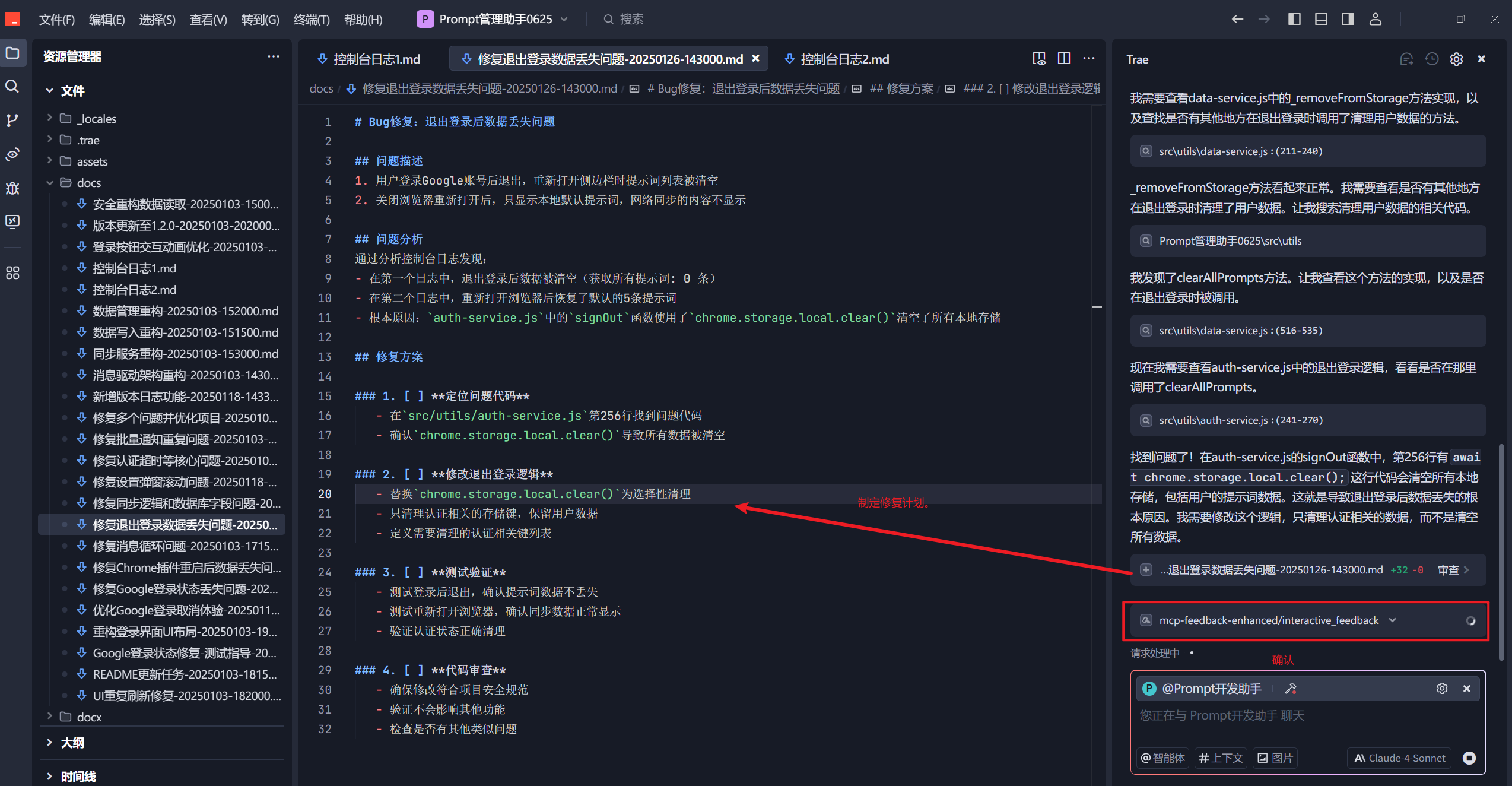
调用MCP工具反馈当前任务状态,确认是否执行。在这里可以继续提问或者上传图片(他会转成buase64格式发送给Trae)。
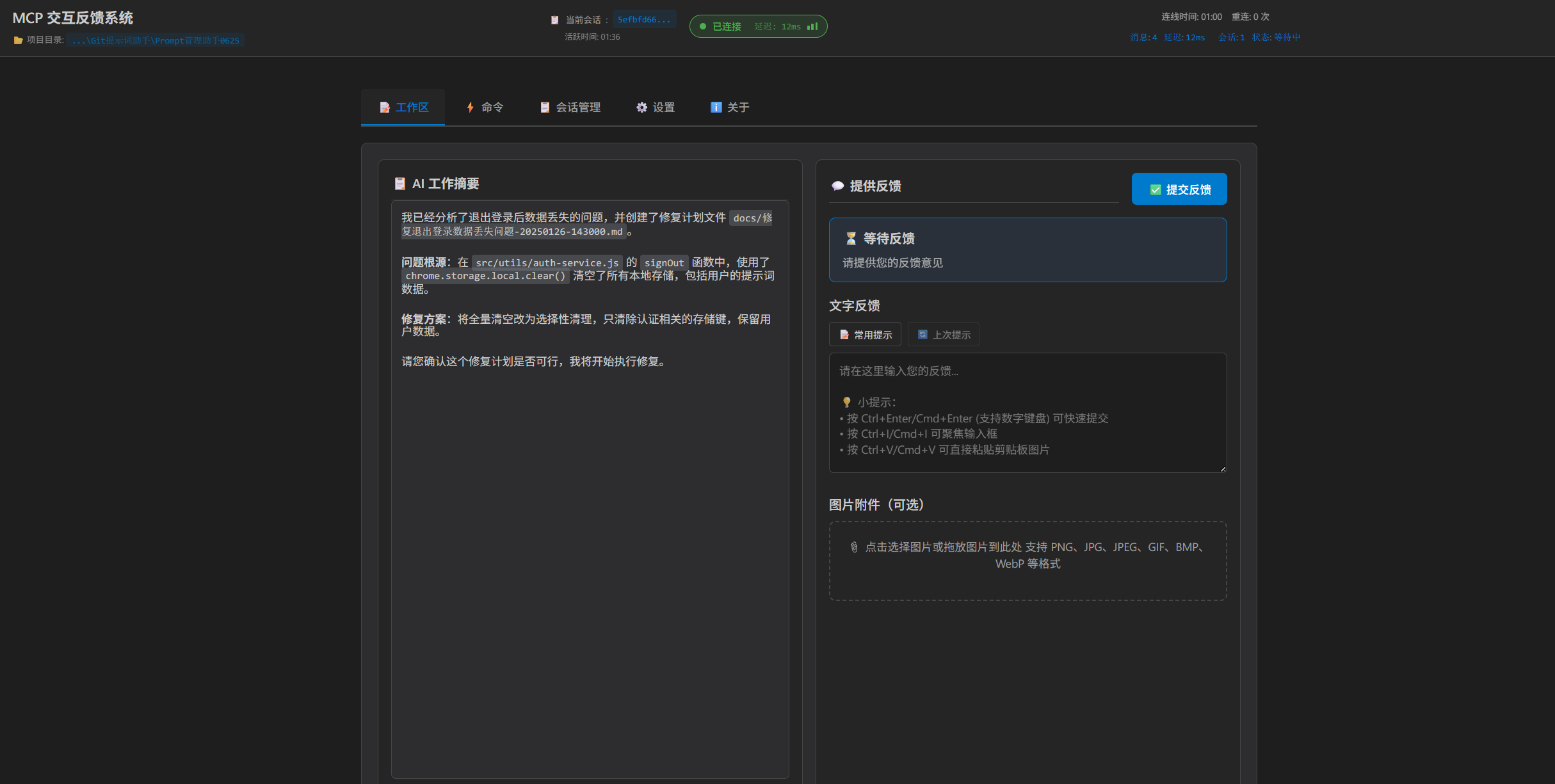
在完成任务后,更新任务规划文档,提出测试建议:
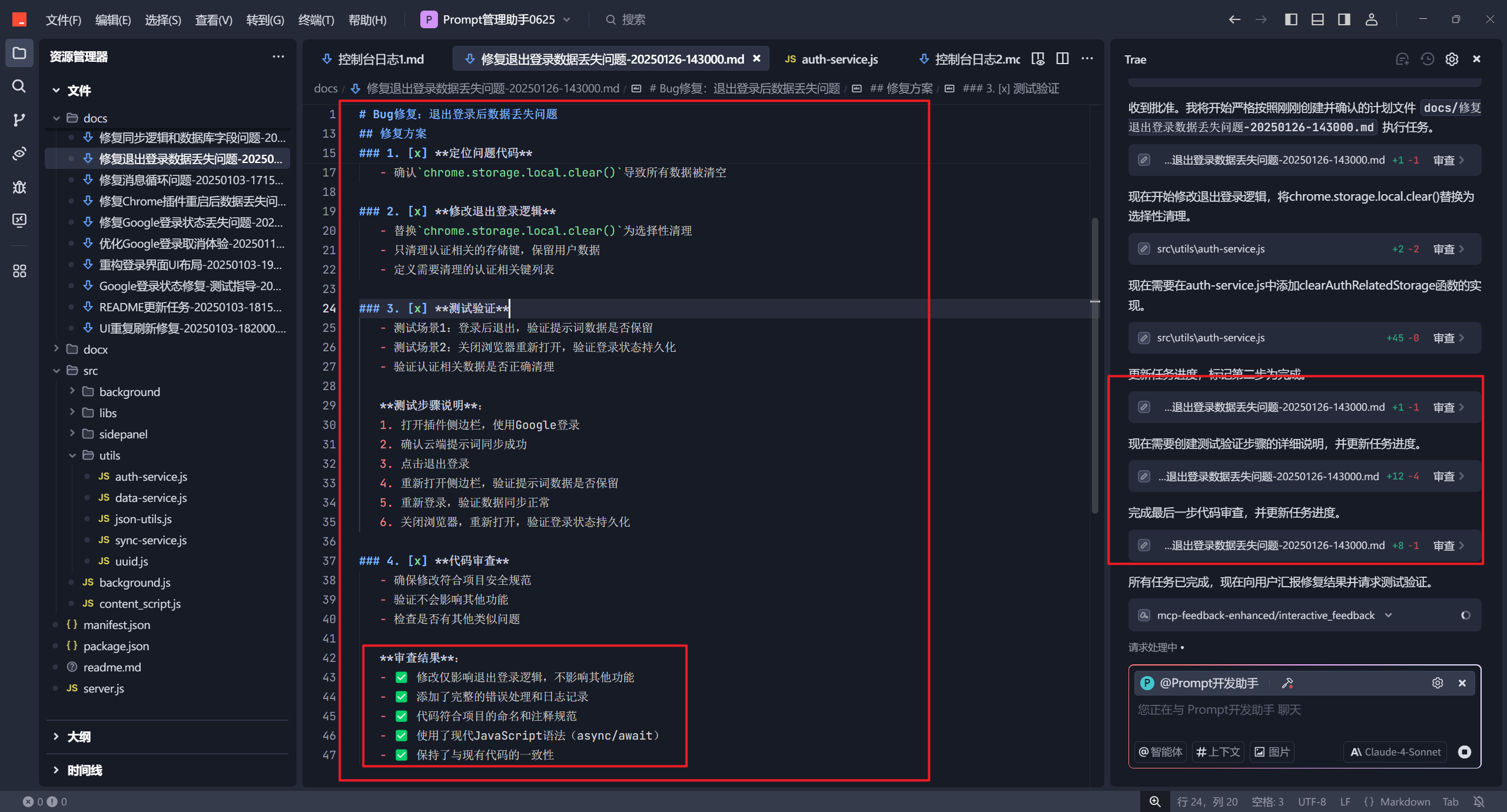
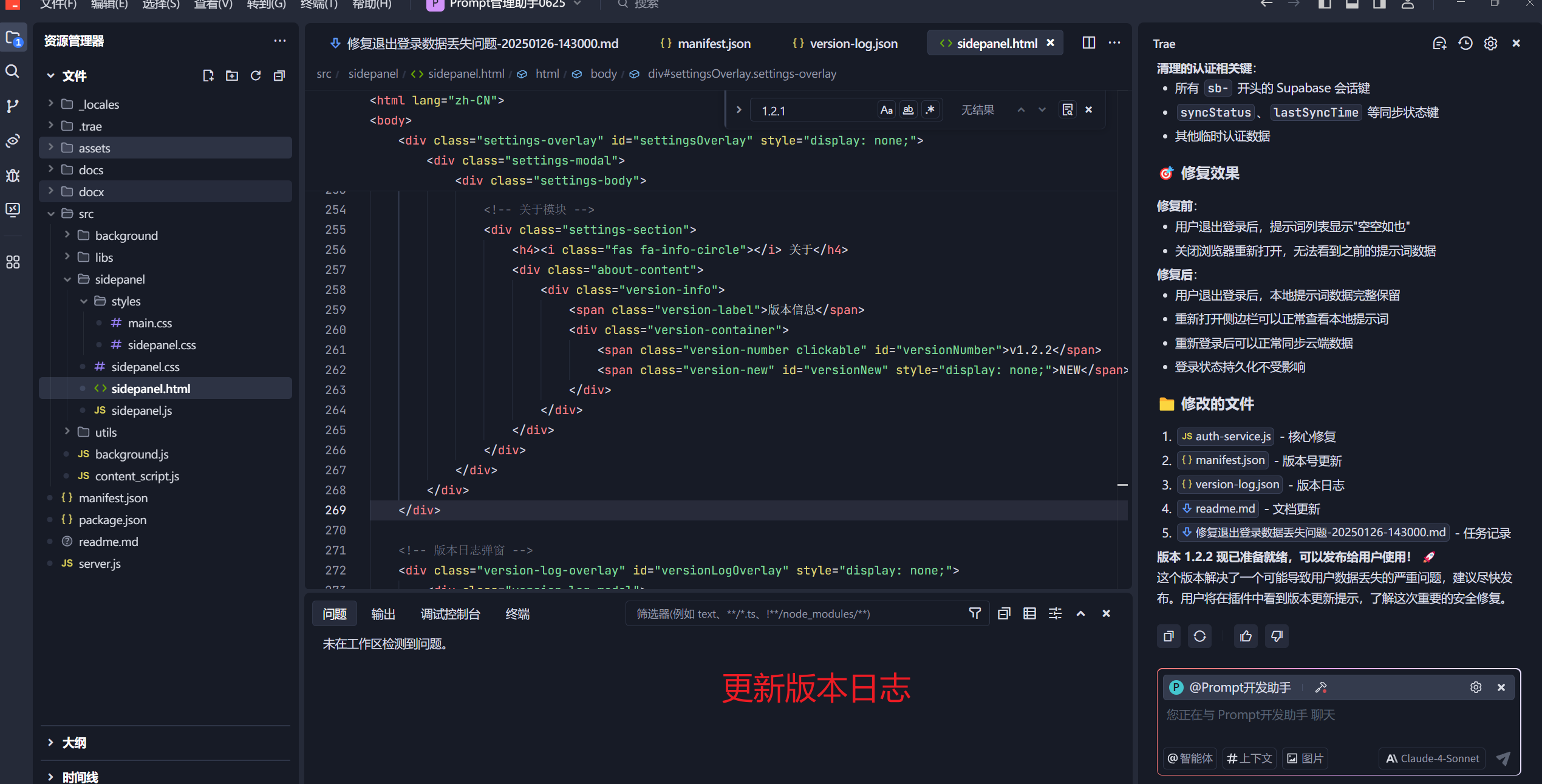
接下来,就是打包发布到Edge的扩展商店(为什么是Edge呢?因为他免费啊。谷歌要5美金)。
详细步骤可参考这篇文章:https://w2solo.com/topics/5412。我在这里就不多写了
话说,这里注册Edge扩展开发者的时候,碰到了一个微软中国区巨大的BUG,堵塞了我小半天。。最后搜索到了问题原因:就是省份我们不能写北京,也不能写beijing,必须写BJ。上面的文章已经提到了这个问题。但是我当时,费了半天劲,才通过下面这个文章发现解决方案:https://linux.do/t/topic/161160。
4. 一点点思考
4.1 我们标准的软件开发SOP仍然适用
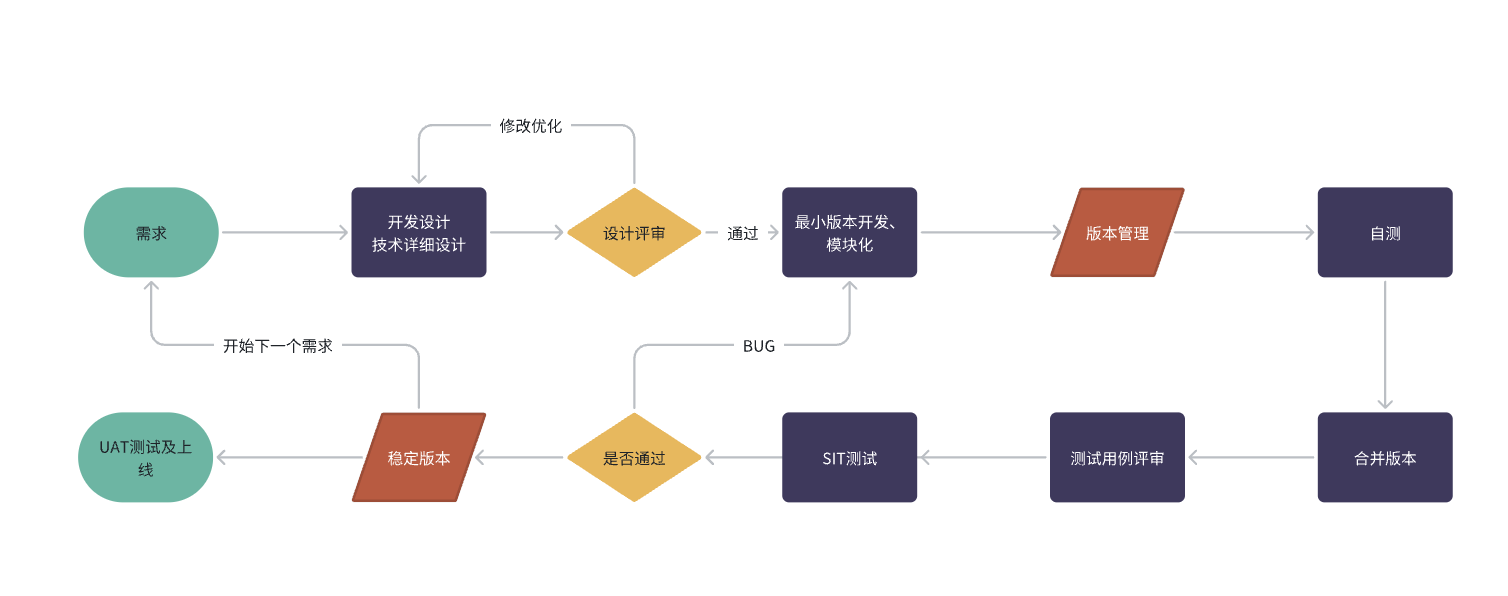
严格按照我们软件开发时,正常的工作SOP进行。
其实一个正常的需求开发流程应该是上面的样子。在日常工作中,我们产品可能提供的是一个巨大的需求文档,但是开发老师在实际开发的时候,其实是对需求文档做了进一步的拆分的,拆分到具体的功能由哪位老师来完成,这个功能应该包含几个代码文件,几个函数等等。然后才会开始开发工作。
所以在这里,如果我们偷懒直接给模型一个巨大的需求文档,那么大概率在当前的模型能力水平下,你得到的会是一个有无数bug的产品。因为当前,其实模型的上下文、规划能力、执行能力,还做不到这么完善。
所以,即便是有了AI,我们的工作流程仍然没有太大的变化,无非是原来都是人干,现在变成了大部分是AI干,但是人要来监督。
4.2 我们还是要专注
其实,前一段时间,本身就挺迷茫和焦虑的,从3月到现在每天都在追新工具,新方法,新概念。总是担心自己被淘汰了,因为今年各种Agent、各种新的技术、工具、模型,层出不穷,让我有种止不住地焦虑。去年其实还没有这么严重。也可能大概是Deepseek的出现(极致的成本),引爆了这一切吗?其实也不尽然,如果没有它,最多就是在中国不会人尽皆知AI,但是该有的爆发,依然会出现。
所以,一直在努力的调整自己的心态,渐渐地,自己其实平稳了许多。可能想通了,人的精力是有限的,我们能把自己领域的东西学精学透,让AI真正为我们所用,其实就已经很不容易了。所以还是要专注。

4.3 我们会变得越来越懒吗
当然在追热点的这个过程中,我还经历了这样的疑问:什么事儿我都先问问AI,那我的思考能力还在吗?我的脑子会生锈吗?我如何去判断他说的对不对呢?我应该如何学习呢?如何不被他骗呢?怎么样仍然能让自己仍然具有很好的分辨能力呢?

其实,想一想,本身AI就是工具,我们现在这个阶段,要用好工具,让他做人类不擅长的事情,这件事本身是对的,就好像我们人类使用车的过程:
畜力车—->汽车—->电车—–>智能汽车
以前的工具,解决的可能是体力的生产效率问题,而大模型,其实是解决的脑力的生产效率。
我们未来的核心竞争力,将不再是“我知道什么”或者“我会做什么”,而是我能如何利用AI,去解决更复杂的问题,创造全新的价值。