我只是想留住一个投资人的思考,结果学会了如何让 AI 替我干脏活

我非常喜欢一位投资人的投资风格和分享的投资理念,老粉如果注意过的话,我之前其实提到过一次。最近他不在微博说话了,因为被迫要收取投顾费,所以他转到了且慢基金社区的同路人小组去发言。
我就想着记录下他的投资理念,方便未来哪天,大佬身退了,我也能学个5成的水平。

在开始正文之前,我想要警告各位:
本文不需要太高的技术水平,如果有兴趣,应该可以在几个小时到一天内复现。
我们不会的,AI会的,让他教我们。
使用国内版本的Trae,可以完成。
另外,本文不构成任何投资建议。
我不会的,AI会
所以我就问Gemini:


这里为什么会问Obsidian呢,是因为我最近在将我自己所有的知识体系向这里转移。
很明显,看来我需要写一个网络爬虫才能实现我的诉求了。我真正意识到的问题不是“我不会写代码”,而是“我之前问错了问题”。
我已经自己写过爬取静态网页,就是请求一次,所有内容都展示的网页。
但是很明显,且慢的网页不是的,他是动态的,因为有很多内容都需要点击查看全文、查看更多,甚至会跳转到一个新的网页。

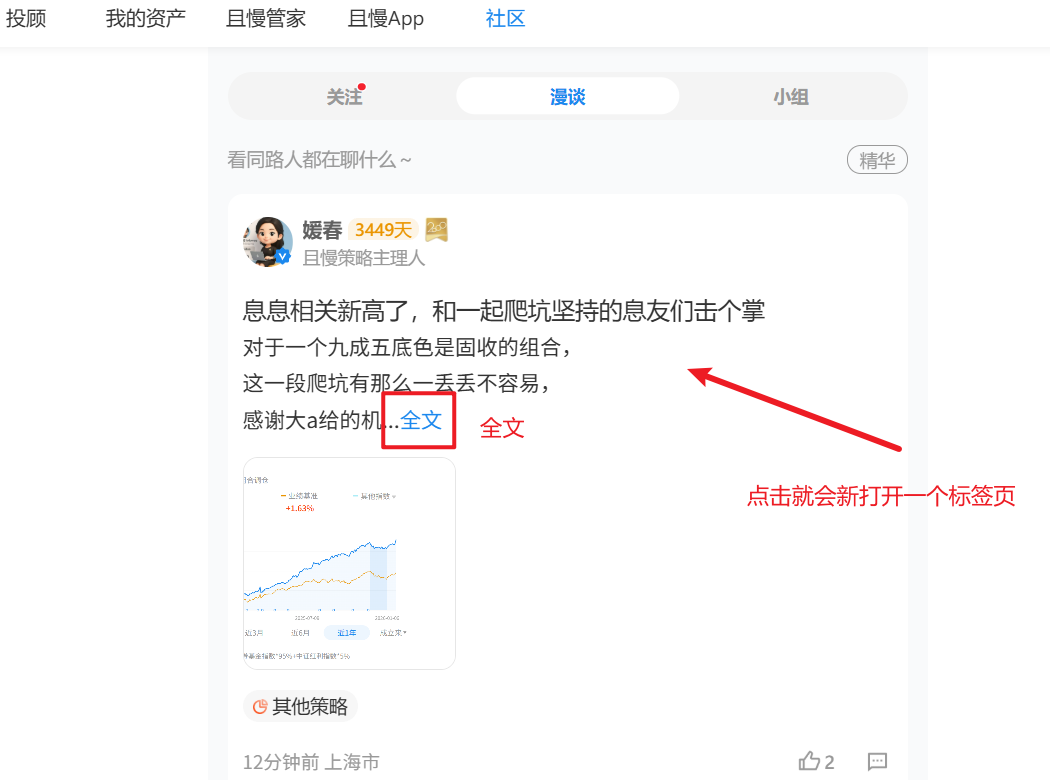
所以,我紧接着问了Gemini一个问题:

这个时候我的想法其实是,将html保存到本地,让后让Claude去分析html结构,最后直接写脚本爬取(这个时候我完全还是静态网页的思维,还没有想到动态网页的方式)。
但是看完以后,我就知道了,我这个网页是动态加载的,他提醒到我了。

我就寻思,既然他说可以保存到本地html,我就让他写个脚本,然后找Claude code来分析,直接给我写个爬虫脚本不就行了。
很快它就把代码给我写好了。并且告诉我如何使用。
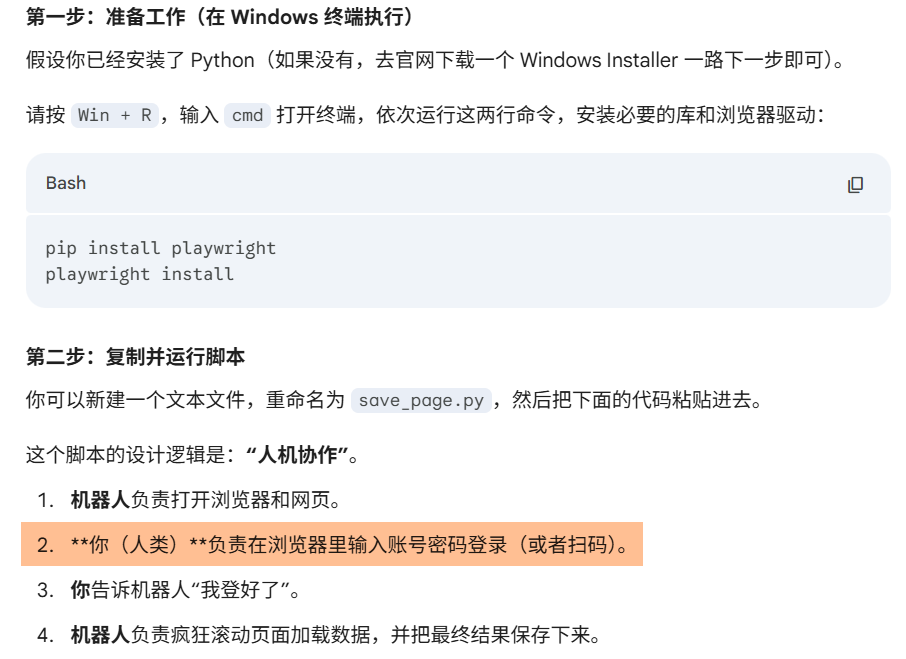
这段代码的价值不是“让你学 Playwright”,而是一次性帮你把动态页面“拍平”为静态 HTML。你完全不需要理解这段代码的每一行,只要知道:它的产出是一个“可被 AI 分析的 HTML 文件”。
import time |
ok,这是一个脚本,但是我们不会运行啊。
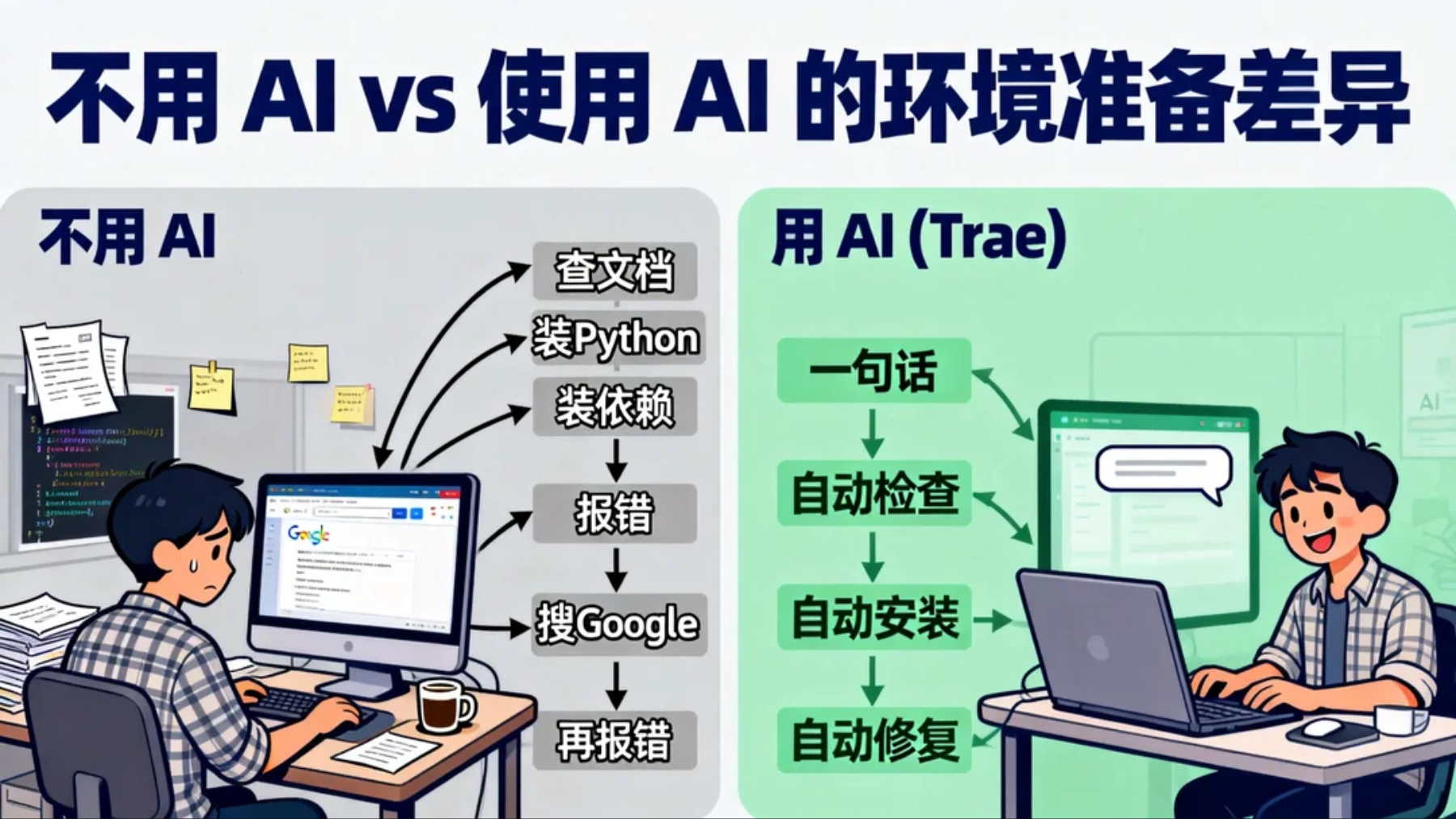
如何安装环境
没关系,问AI,让他告诉我们,我应该如何在本地运行。

哇,好复杂。
大家还记得我们最开始装了Trae。现在打开它,只要输入:
我现在需要运行一个基于 Python 和 Playwright 的网页爬虫脚本。 |
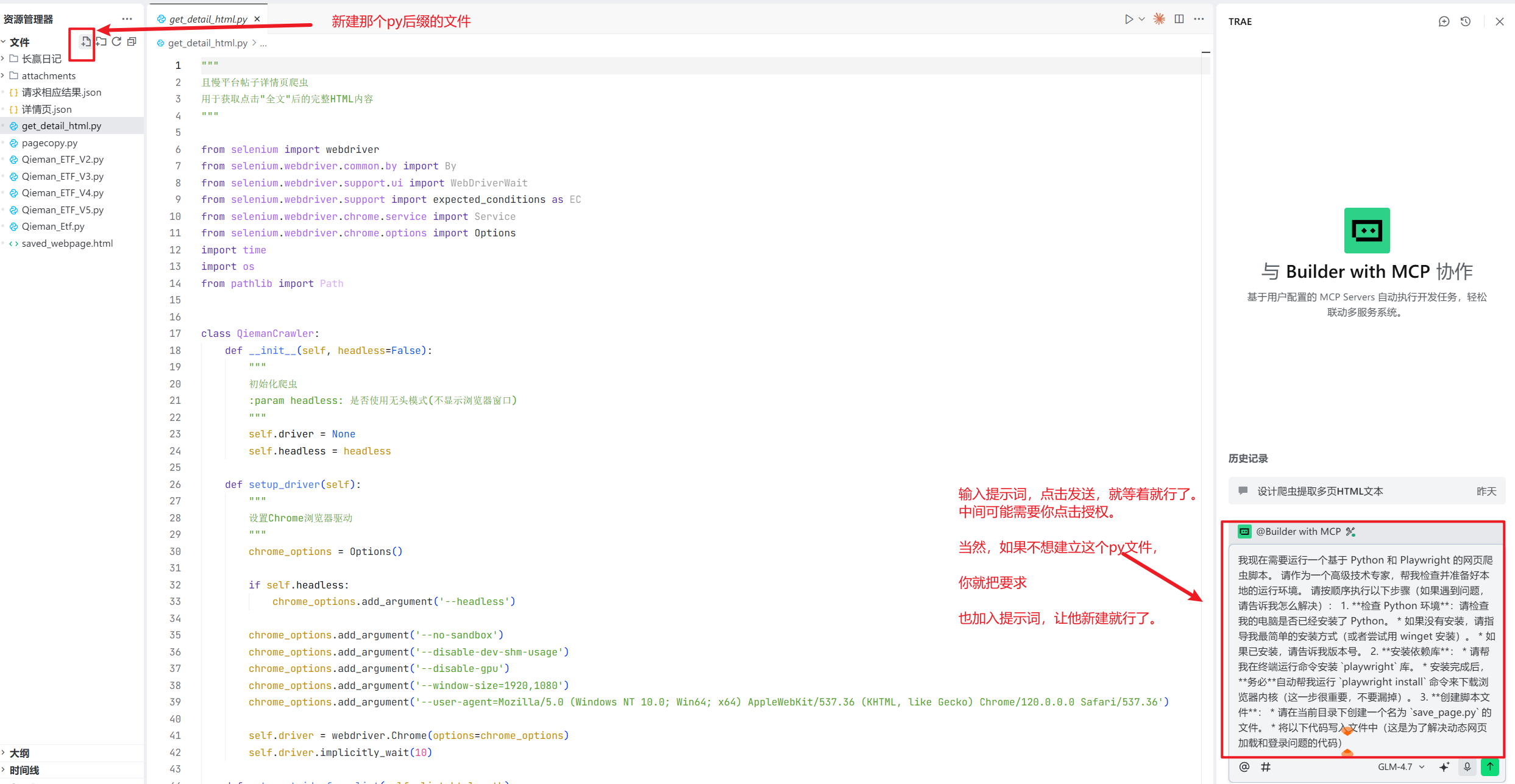
如何来写需求
虽然,现在的AI很厉害了,在写代码上面,国内的kimi-k2和GLM-4.7,可以完成这个写代码的任务,但是,还是需要我们准确的描述需求。
我对爬虫的熟悉程度只能说懂5%吧,所以,继续问AI。
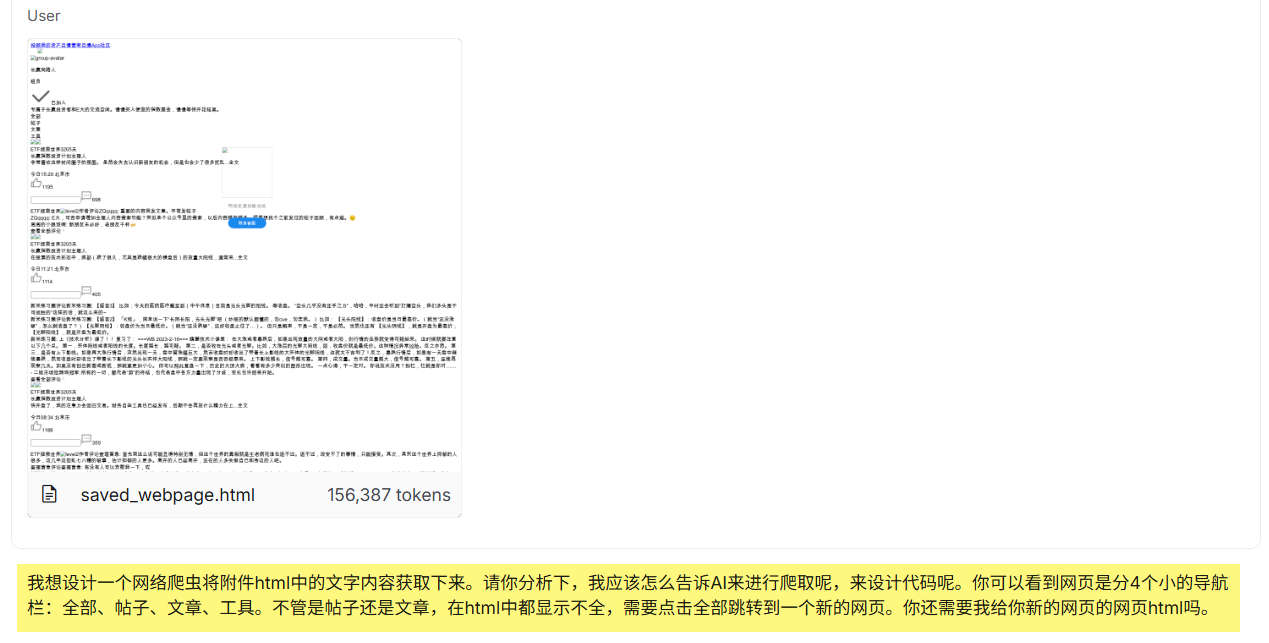

这里他给我写的这个方法,我以前是真的不知道。这次真的是学到了。按照他给我的详细步骤,我去查看了且慢的网页,真的如他所说,响应结构是json。
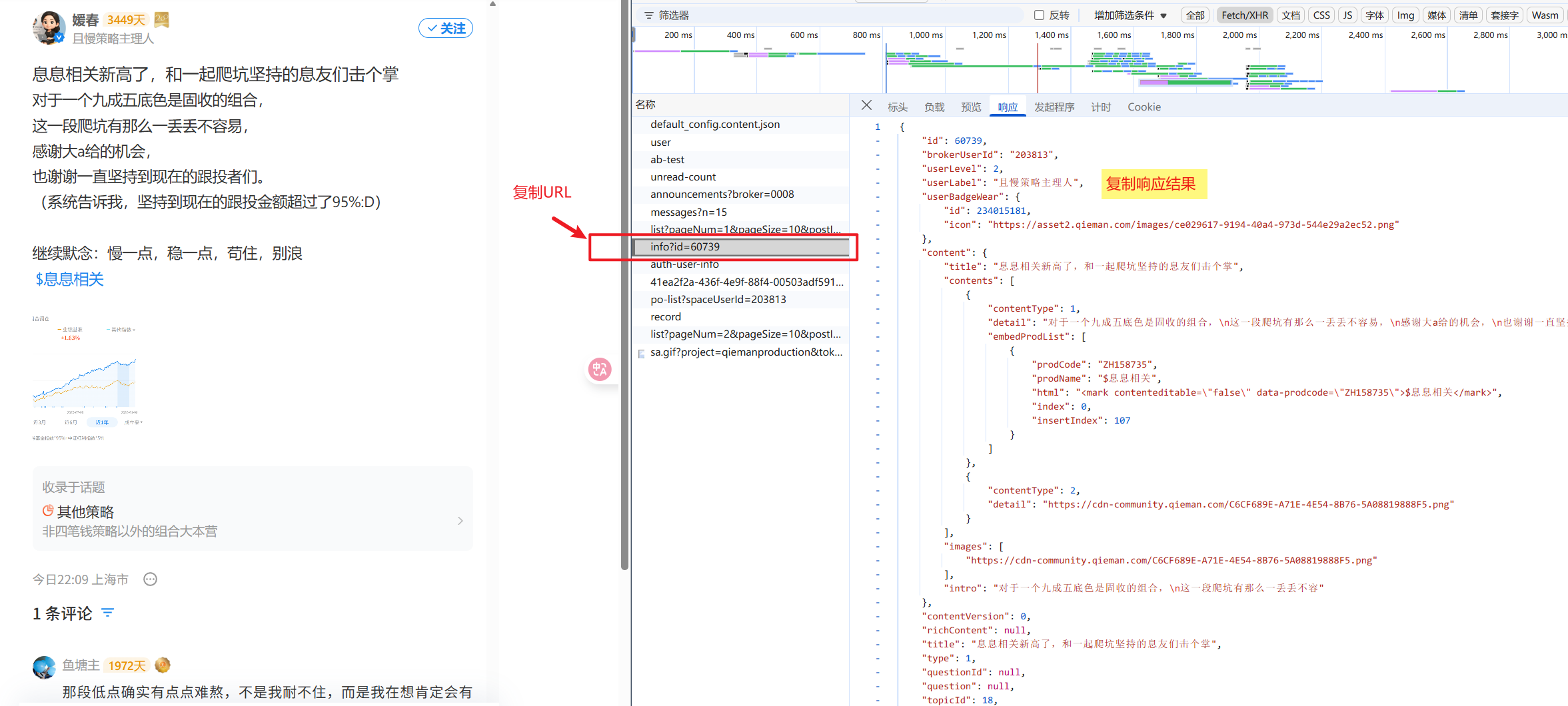
然后,大家如果真的实操,请好好看这张图(如果看不懂就依次问AI):
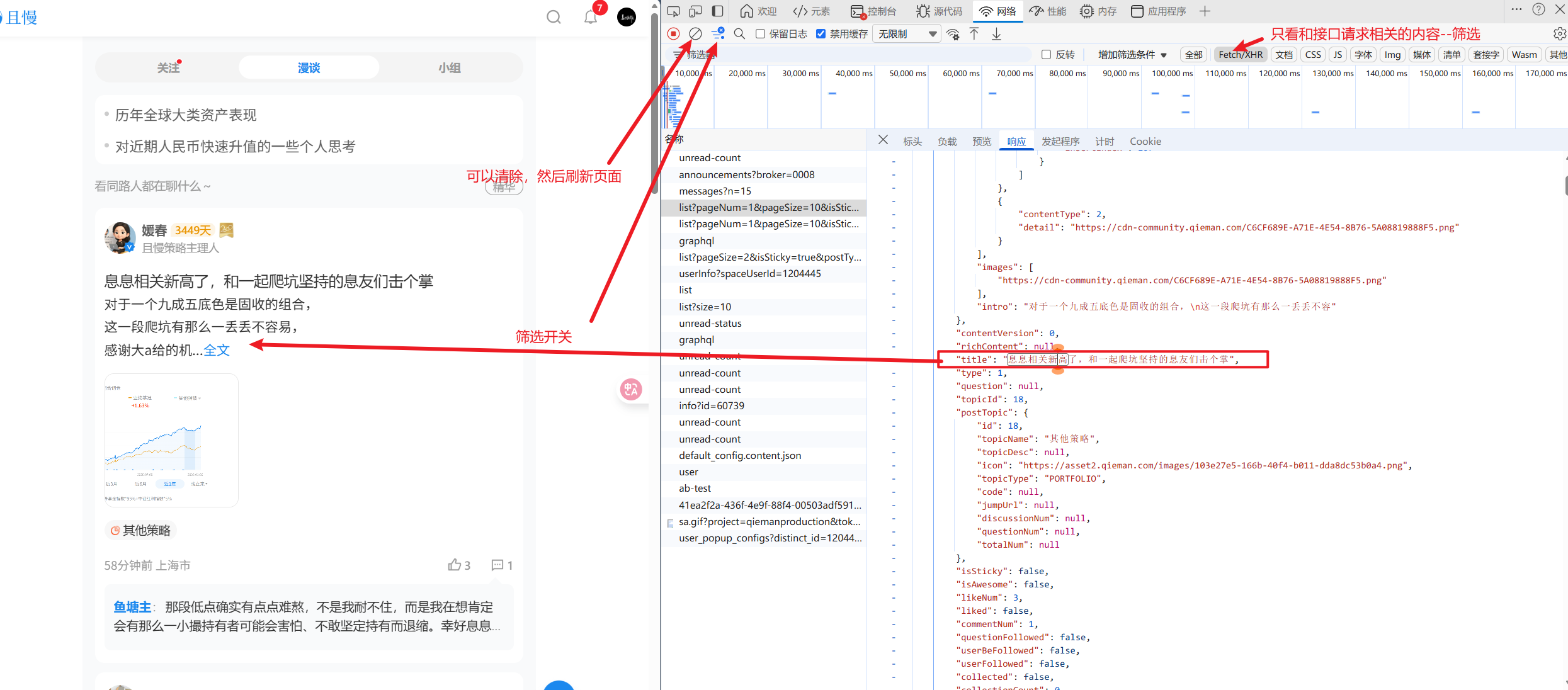
大家可以看到这个请求的内容和左边是对不上的,左边多,右边少。
实际上,我们也确实需要点击全文,就会跳转到一个新的tab页:
我们接下来,就依次观察这两个页面,将两个页面对应的这个页面的请求URL和响应的json,复制下来保存。
就像这个样子:
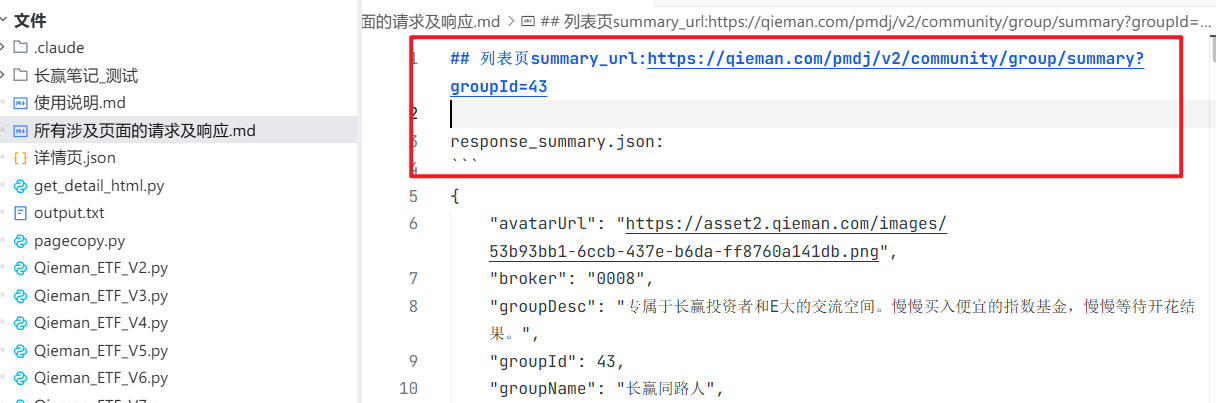
这里,我还需要跟大家说的是,大家如果仔细观察,就会发现。他是有多个URL的。
所以,我们需要粘贴复制很多次,还要仔细观察。
其实到了这里,需求就写完了。
AI 写代码的前提不是你会不会代码,而是你是否能把「系统边界」和「数据形态」描述清楚。换句话说,写 AI 爬虫编程提示词时,只要想清楚三件事:
- 数据从哪里来(接口 / 页面 / 文件)
- 数据长什么样(HTML / JSON / 列表)
- 最终要变成什么(Markdown / 表格 / 数据库)
如何开发
如果你对输出结果没什么特别的要求,那就直接将这个json和你的需求,告诉Trae,让他给你开发,然后测试对比就行了。
可以参考下面的提示词:
请帮我编写 Python 代码(使用 requests 库)。 |
数据源这里,就把你复制的URL和响应结果的json给到它就可以。
这里其实是最费时间的….本文主要讲的还是思路。但是如果你按照这个思路做,一定能做出来。
其实,这里,如果我不是对输出的结果,要求评论必须怎么排版、布局、排序的话,第二个版本,就已经可以完成我们的需求了—批量抓取全部的帖子和文章内容。
网络爬虫,一定要注意不要对人家的服务器造成影响。频率要低。最好按照爬虫协议执行:
查 robots.txt(网站爬虫协议)
- 访问格式:https:// 目标域名 /robots.txt(如https://www.baidu.com/robots.txt)。
- 关键字段:User-agent(指定爬虫,* 代表所有)、Disallow(禁止路径)、Allow(允许路径)、Sitemap(站点地图)。
- 示例解读:User-agent: * / Disallow: /admin/ → 禁止所有爬虫访问 /admin/;Allow: /public/ → 允许访问 /public/。
两个简单地单篇文章获取方法
上面的批量爬取,确实比较麻烦,如果一点技术背景都没有,可能要琢磨好久。
还有一种操作方式,就是需要每天都点,麻烦:
安装浏览器插件:
Obsidian:https://chromewebstore.google.com/detail/obsidian-web-clipper/cnjifjpddelmedmihgijeibhnjfabmlf
飞书剪存:https://chromewebstore.google.com/detail/飞书剪存/mofcmpgnbnnlcdkfchnggdilcelpgegn
这两种方式,需要你在本地安装飞书或者是Obsidian。当然这两个插件,可以尝试剪存万物,比如你喜欢的公众号的文章。
就是麻烦在,每天都需要登录点击存一下,不然就会一下子积攒好多。
而上面的脚本,后续我就可以通过在win电脑上面,设置任务计划程序,实现定时自动执行。
有了这些材料,我后面可以自己做个知识库,供我学习,各有利弊。
总结下来,如果你想照着做一遍,只需要完成这 6 步:
- 明确你要长期保存的内容来源
- 用 AI 判断网页是静态还是动态
- F12 → Network → 找 JSON 接口
- 把接口 + 响应丢给 AI 写爬虫
- 输出为你熟悉的知识格式(如 Obsidian)
- 用任务计划程序实现自动化。
如果你和我一样,希望长期、系统地保存高价值信息,这套思路非常值得一试。
在 AI 时代,真正的学习不是“学会一项技术”,而是“学会如何让 AI 替你补齐技术短板”。