前面给大家介绍过很多AI编程工具,Claude code、codebuddy、Trae等等。
大家可能会想,AI编程工具?我又不是程序员,这东西跟我有啥关系 ?。
我想说不是的,大家每个人都用得上。
AI编程工具早已不是程序员的专属,它更应该被看作是我们每个人的“效率放大器” 。
AI编程工具应该成为我们每个人电脑上必备的软件 。无论是IDE、命令行工具还是什么,我们都不应该把它当成什么编程工具,应该当做一个效率工具。我们不需要会编程,会写代码,我们只需要清晰地表达清楚我们的需求是什么,让AI给我们解决就好。
接下来,我会用4个案例,跟大家说,我在日常工作是怎么用AI编程工具的:
一句话,将PDF批量转换为高清图片。
一句话,将上百张照片按“时间地点”智能重命名。
一个指令,实现文章图片自动上传云端并替换链接。
一次提问,让AI带你读懂软件的底层代码逻辑。
格式转换,比如pdf转成图片。
比如,我们现在下载到的发票大部分都是pdf格式,但是我们在保险理赔或者其他场景的时候,需要上传图片格式。这个时候,我们把pdf打开,一个个截图那可真是麻烦死了。
当然,网上有各种工具,那我们要不就得下载,要不就得上传,下载麻烦,上传数据不安全。
所以,我们可以在这里按住**Shift+右键**,打开终端或者Powershelll,打开claude code。
关于Claude code 的安装,可以看我这篇文章:
GLM-4.6 + Claude Code实战:从入门配置,到一个差点翻车的项目
我们输入:
claude --dangerously-skip-permissions ##跳过所有权限认证
大家自己刚开始用的话还是直接输入Claude比较好。预防万一,你不小心说错了话,他干了什么让你后悔的事儿。
然后我们输入:
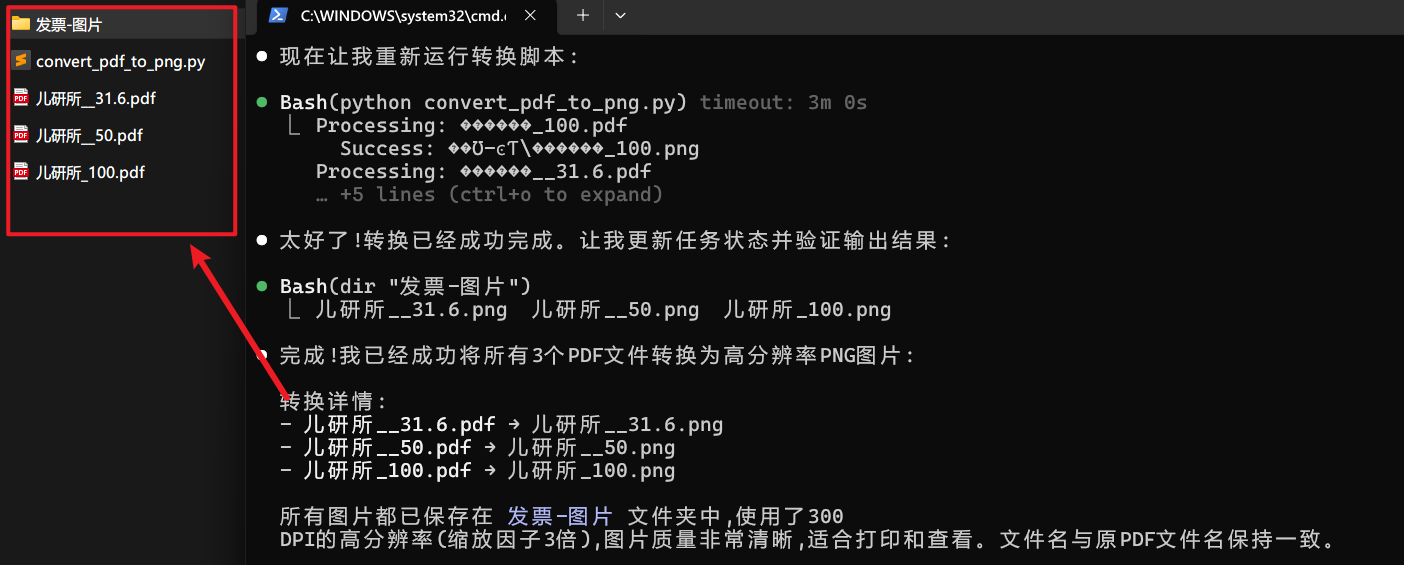
帮我将文件夹中的pdf文件转换为图片的png格式的。分辨率高一些。输出到发票-图片文件夹中,图片命名和现有pdf文件名一样。
很快,他就把活干完了,从它输出的结果看,我们还可以让分辨率更好,现在只是300而已。
大家看看效果,我隐私信息打了码哈:
可以看到,它自己写了个python脚本,完成了这件事情。
python是一种编程语言。我们不需要知道它是什么,我们只要会用就行了 。
当然,如果你想安装python,那你可以直接给他说一句:
甚至,你都不需要会运行什么的,打开claude,给他说,帮我运行xx脚本 ,就完事儿了。
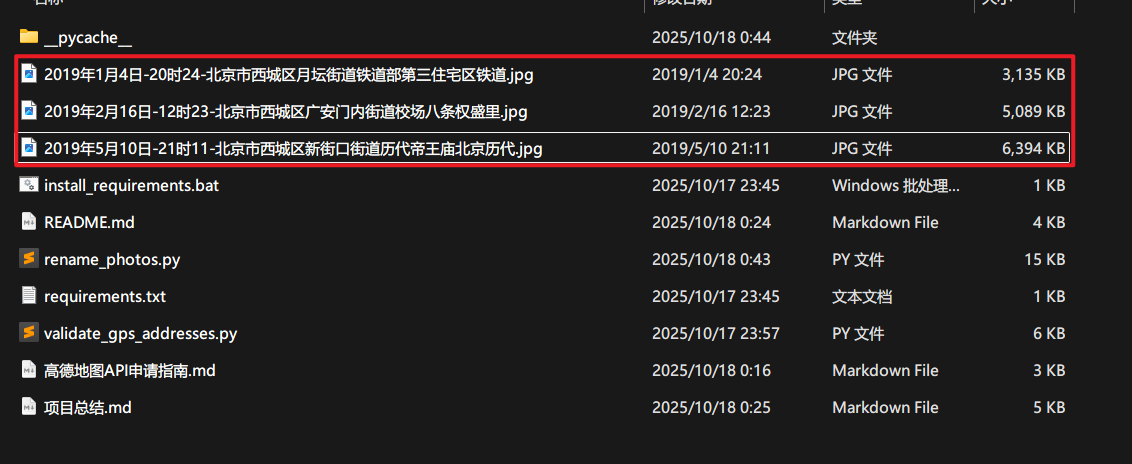
照片乱糟糟?AI帮你按“时间地点”自动整理 还有一个大家都有可能会用到的场景,批量重命名。
比如从手机、相机里导出一大堆照片,文件名全是 IMG_xxxx.JPG 或者 DSC_xxxx.JPG。
想找某张特定的照片(比如去年旅游在某个地标拍的),只能靠缩略图一张张猜,非常痛苦。
这个时候,假设,我们已经给claude code安装了高德的mcp服务,如果你没装,可以用下面的命令:
claude mcp add --transport sse amap "https://mcp.amap.com/sse?key=<your-api-key>"
key从高德开发者平台获取下,或者大家可以看我这篇文章的教程(在文章的最后部分):
不止出行规划!看MCP+高德地图在信贷风控的新应用
当然,上面的mcp这次我只是用来校验结果是否正确的,这次其实并没有在脚本用到,但是key是用到了。大家也可以把下面的命令换掉,不要让他写脚本(数据量大还是建议用脚本方式)。
然后我们就输入:
将文件夹中的图片重命名,按照“年月日时分_地点”的格式进行命名。例如2018年10月1日_15时00_北京朝阳大悦城。地点更具经纬度信息,使用高德地图相关工具获取。
当然,你看着腻歪的话,也可以把文件夹内,让claude code整理一下.
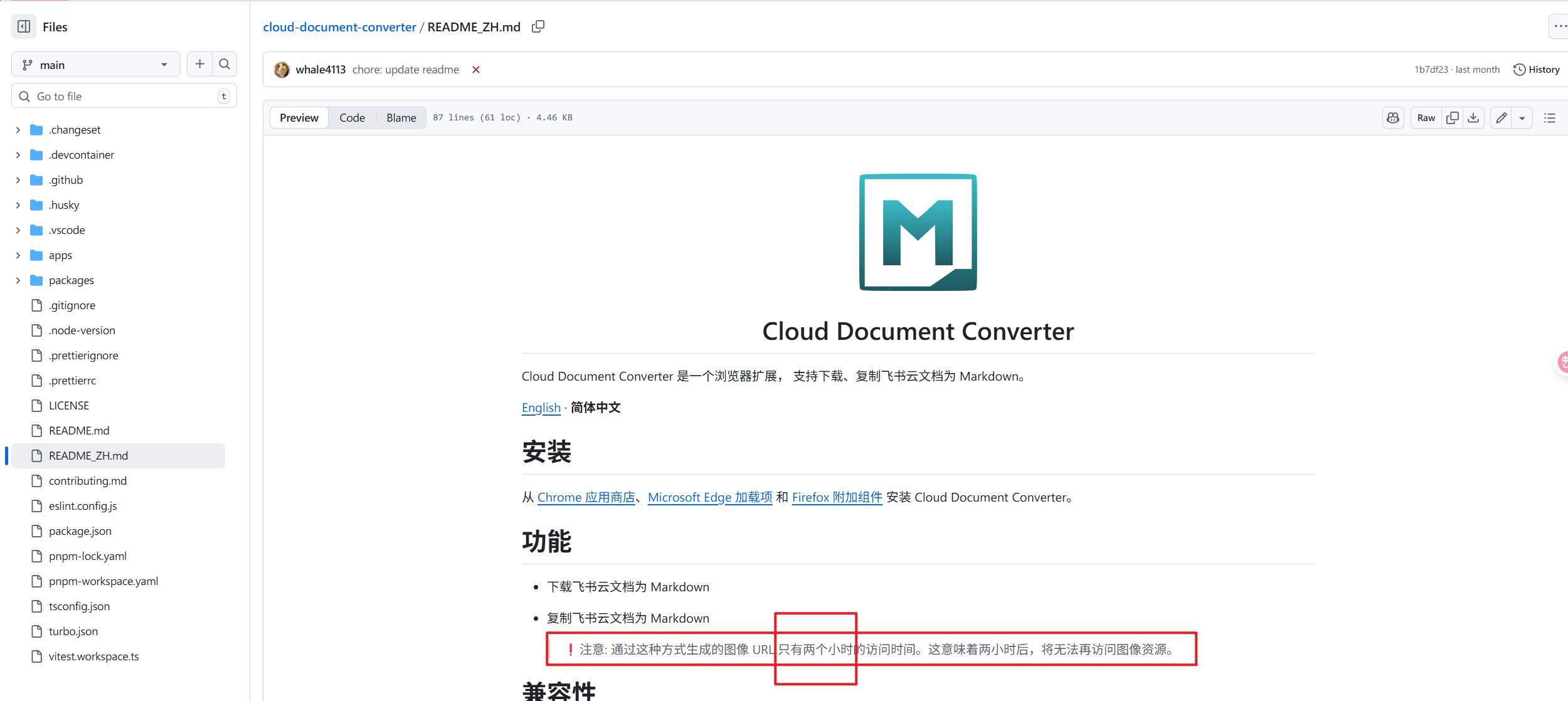
图床切换,markdown图片自动上传阿里云 这里的背景是这样子的,我以前呢,喜欢用飞书写文章记东西。这样呢,飞书既是我的知识库,又是我的图床(就是保存图片的地方),飞书排版又好看,还大方,个人使用的话空间也很大。
但是有个不方便的点就在于,我想要发表到公众号或者其他平台的时候,就不行了,因为飞书不支持导出为markdown。
我很头疼,但是后来我发现了这个开源的工具,同时也是浏览器插件:
这东西超级好啊,但是唯一不好的,就是这个两个小时,但是这个两个小时的限制也不是工具限制的,是飞书限制的。
最最重要的是,即便是这样下载了markdown格式的飞书文档,也没办法直接在微信公众号用,因为各大平台,在上传的时候,都喜欢将图片下载到自己平台换成自己平台的图床(图片链接)。
而飞书这个,微信那边没办法导入。
所以我就寻思,我能不能自己通过脚本把图片下载下来,然后上传到我的阿里云的oss。
AI时代,想干就干嘛 。干中学。
我就直接在claude code中输入:
文件夹中是我的markdown文档,里面的图片链接是飞书的。帮我完成以下需求: 1. 扫描Markdown文件中的所有图片链接2. 下载这些图片(支持网络链接和本地文件)3. 上传到我的阿里云OSS4. 使用阿里云oss的连接替换原文件中的图片链接5. 保持Markdown格式不变6. 支持阿里云oss账户信息配置。7. 使用context7查询阿里云官方的sdk,避免重复造轮子。完成需求后,可以要求我提供阿里云oss的key等信息,再开始测试。
很快他就完成了第一个版本,当然,版本相对比较糙,所以后续我又增加了以下功能:
✅ 支持批量处理多个Markdown文件
✅ 支持网络图片和本地图片
✅ 自动备份原文件
✅ 智能去重,避免重复上传
✅ 支持多种图片格式(jpg, png, gif, webp等)
✅ 完整的错误处理和日志输出
✅ 可配置的上传参数
✅ 实时更新 :每上传一个图片立即更新MD文件链接
✅ 重试机制 :网络失败时自动重试(最多3次)
✅ 随机延迟 :模拟真实用户行为,避免被反爽虫机制限制
✅ 容错性强 :单个图片失败不影响其他图片处理。
基本满足我的使用了,这要是放在以前,我自己是肯定处理不了的。
在我理解看来,各大网站的逻辑,估计和我的这个小脚本差不太多,比如掘金,大家可以试试上传。我也开源了,大家需要的话自取。
开源地址 :https://github.com/Wangshixiong/markdown_image_replace
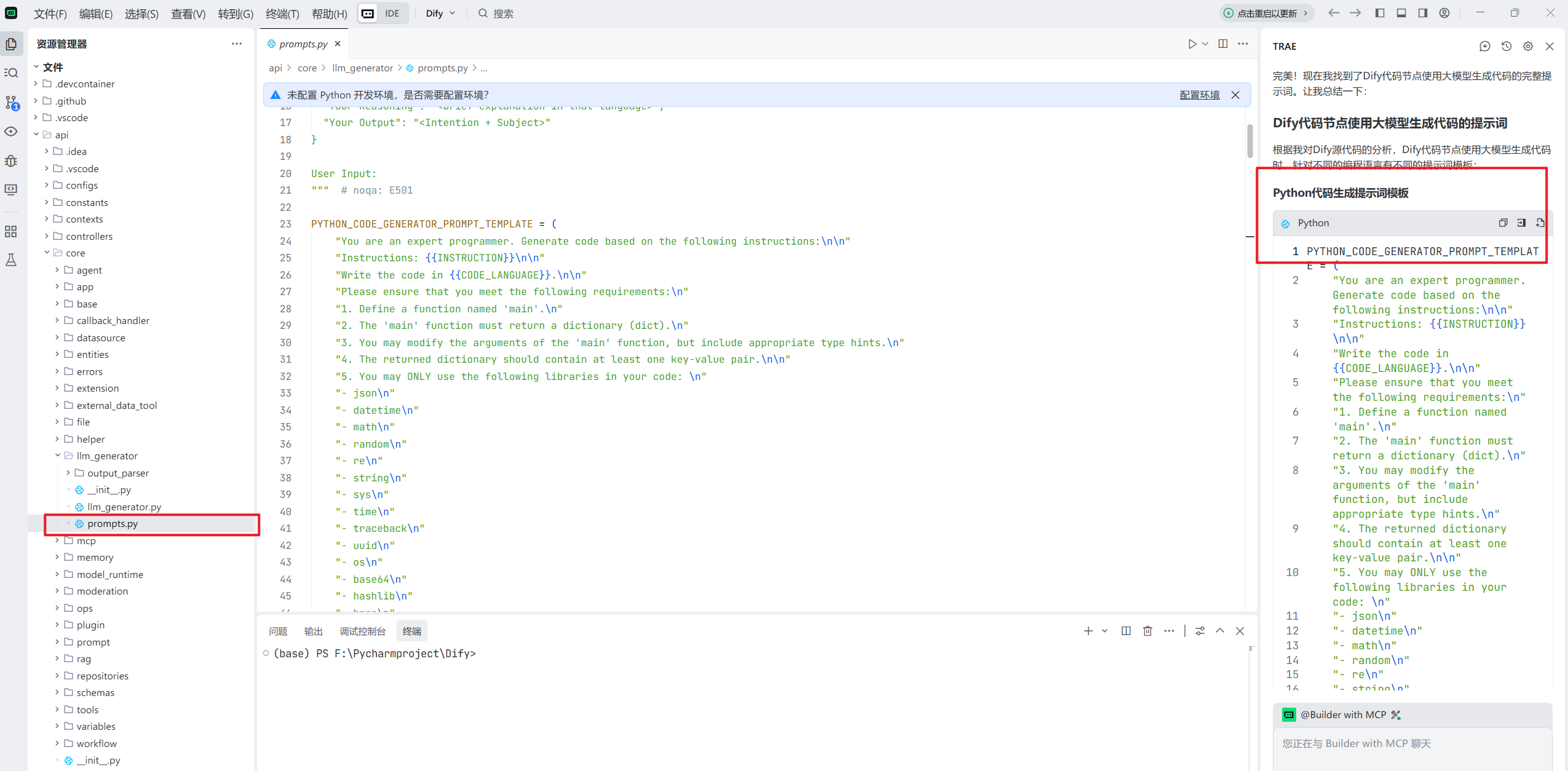
询问代码逻辑,学习产品逻辑 大家知道,我最近一直在研究dify,我之前也总结过一套dify开发节点的提示词,但是那个提示词是我让chatgpt综合网上各种信息帮我总结的。前几天,我突然就寻思,**Dify的代码节点是可以让AI直接生成代码的,所以他肯定有系统提示词啊,我为什么不研究一下**。
但是就我这个代码水平,100分之一的水晃荡,我也看不懂啊。可是我有工具啊。
这里我们可以下载Trae CN ,也就是他的国内版本,当前几乎所有的国内好模型,都可以在上面免费使用用。
打开以后,随便输入个简单的提示词:
dify的代码节点,可以使用大模型生成代码节点的代码,比如python,那这个代码节点的使用大模型生成的提示词是什么。
很快,他就给我找到了对应的代码文件和对应的提示词:
其实大概看一下这个文件,你会发现,基本上所有涉及到前端话术优化,代码优化等等的AI优化节点的提示词都在这里。下面还有js的说明,这里我用python比较多,我们就看Python的:
"You are an expert programmer. Generate code based on the following instructions:\n\n" "Instructions: {{INSTRUCTION}}\n\n" "Write the code in {{CODE_LANGUAGE}}.\n\n" "Please ensure that you meet the following requirements:\n" "1. Define a function named 'main'.\n" "2. The 'main' function must return a dictionary (dict).\n" "3. You may modify the arguments of the 'main' function, but include appropriate type hints.\n" "4. The returned dictionary should contain at least one key-value pair.\n\n" "5. You may ONLY use the following libraries in your code: \n" "- json\n" "- datetime\n" "- math\n" "- random\n" "- re\n" "- string\n" "- sys\n" "- time\n" "- traceback\n" "- uuid\n" "- os\n" "- base64\n" "- hashlib\n" "- hmac\n" "- binascii\n" "- collections\n" "- functools\n" "- operator\n" "- itertools\n\n" "Example:\n" "def main(arg1: str, arg2: int) -> dict:\n" " return {\n" ' "result": arg1 * arg2,\n' " }\n\n" "IMPORTANT:\n" "- Provide ONLY the code without any additional explanations, comments, or markdown formatting.\n" "- DO NOT use markdown code blocks (``` or ``` python). Return the raw code directly.\n" "- The code should start immediately after this instruction, without any preceding newlines or spaces.\n" "- The code should be complete, functional, and follow best practices for {{CODE_ LANGUAGE}}.\n\n""- Always use the format return {'result': ...} for the output.\n\n" "Generated Code:\n"
对应的中文提示词是:
你是一位专业的程序员。请根据以下指令生成代码: 指令: {{INSTRUCTION}} 请使用 {{CODE_LANGUAGE}} 编写代码。 请确保你满足以下要求: 1. 定义一个名为 'main' 的函数。 2. 'main' 函数必须返回一个字典 (dict)。 3. 你可以修改 'main' 函数的参数,但必须包含适当的类型提示。 4. 返回的字典应至少包含一个键值对。 5. 在你的代码中,你只能使用以下库: - json - datetime - math - random - re - string - sys - time - traceback - uuid - os - base64 - hashlib - hmac - binascii - collections - functools - operator - itertools 示例: def main(arg1: str, arg2: int) -> dict: return { "result": arg1 * arg2, } 重要提示: - 只提供代码,不包含任何额外的解释、注释或 markdown 格式。 - 不要使用 markdown 代码块 (``` 或 ``` python)。直接返回原始代码。 - 代码应紧随此指令之后开始,前面没有任何换行符或空格。 - 代码应该是完整的、可运行的,并遵循 {{CODE_ LANGUAGE}} 的最佳实践。- 输出结果请始终使用 `return {'result': ...}` 的格式。生成的代码:
这里,为了方便在Trae或者claude中使用,我对它又做了一些优化.
如果你的公司模型水平不是那么优秀,代码不高。这种不涉及敏感信息信息的代码节点,我理解可以尝试使用我下面总结出来的提示词。
如果你在AI编程的工具中使用可以用这个:
# 角色 (Role) 你是一位顶级的 Python 专家,专门编写简洁、高效、独立且符合生产环境标准的代码函数。 你的代码必须能在 Dify 代码节点中直接运行,无需任何外部依赖。 --- # 任务 (Task) 1、根据接收的 “具体任务指令 (Instruction)” 生成一段完整的 Python 代码。 该代码将在 Dify 自动化流程中独立执行,要求稳定、健壮、可复用。 2、将代码写入文件,脚本文件名字由你根据需求自行确定。 --- # 核心代码要求 (Core Rules) 1. **函数定义** - 必须定义一个名为 `main` 的函数,这是代码的唯一入口。 - 函数必须显式声明参数(不要使用 `**kwargs` ); - 参数名称与类型应根据任务描述中出现的输入字段自动生成,例如: - 若任务输入包含 `text` 与 `count` ,则定义为: ```python def main(text: str, count: int) -> dict:
- 若任务输入为 `user_id` 与 `message`,则定义为:
def main (user_id: str , message: str ) -> dict : ``` - 所有参数必须包含类型提示 (Type Hints)。 2. **函数参数规则** - 参数命名应语义明确(如 `input_text`, `task_list`),不得使用模糊命名; - 若任务中提及的输入字段较多,请全部列入函数参数中; - 不得使用 `**kwargs`、`*args` 或全局变量读取输入。 3. **返回类型** - `main` 函数必须返回一个 `dict `; - 返回字典键名可根据任务语义命名; - 示例: ```python return {"summary" : summary_text}
异常处理 (Exception Safety)
主逻辑必须放在 try-except 块中;
出现异常时,需返回结构化错误信息,而非直接报错: except Exception as e: return {"error" : f"执行出错: {str (e)} " }
库使用限制 (Library Constraints) 仅可使用以下 Python 标准库模块:json, datetime, math, random, re, string, sys, time, traceback, uuid, os,base64, hashlib, hmac, binascii, collections, functools, operator, itertools。
输出格式要求 (Output Rules) 必须严格遵守以下规则:
🚫 只输出纯 Python 代码;
🚫 禁止使用 Markdown 代码块标记(如 python 或 );
🚫 禁止任何解释、说明或文字总结;
✅ 代码开头不得有空行或缩进;
✅ 函数与变量命名使用英文;
✅ 注释可以使用中文。
优秀示例 (Example) def main(text: str, count: int) -> dict:
如果你在前端的大模型对话窗口使用,比如kimi,最好是这个让他输出代码块,删掉提示词中的这个,然后把提示词改为代码块包裹的: ```markdown # 输出格式要求 (Output Rules) 必须严格遵守以下规则: - 🚫 只输出纯 Python 代码; - 🚫 禁止任何解释、说明或文字总结; - ✅ 代码开头不得有空行或缩进; - ✅ 函数与变量命名使用英文; - ✅ 注释可以使用中文。 --- # 优秀示例 (Example) ```python def main(text: str, count: int) -> dict: """ 示例:重复输入文本 count 次并返回合并结果。 """ try: result = (text + " ") * count return {"output": result.strip()} except Exception as e: return {"error": f"执行出错: {str(e)}"}
下面用`trae`示例(`IDE:Trae`,选择模型:`kimi k2 0905`),我们新建智能体,然后把提示词输入: 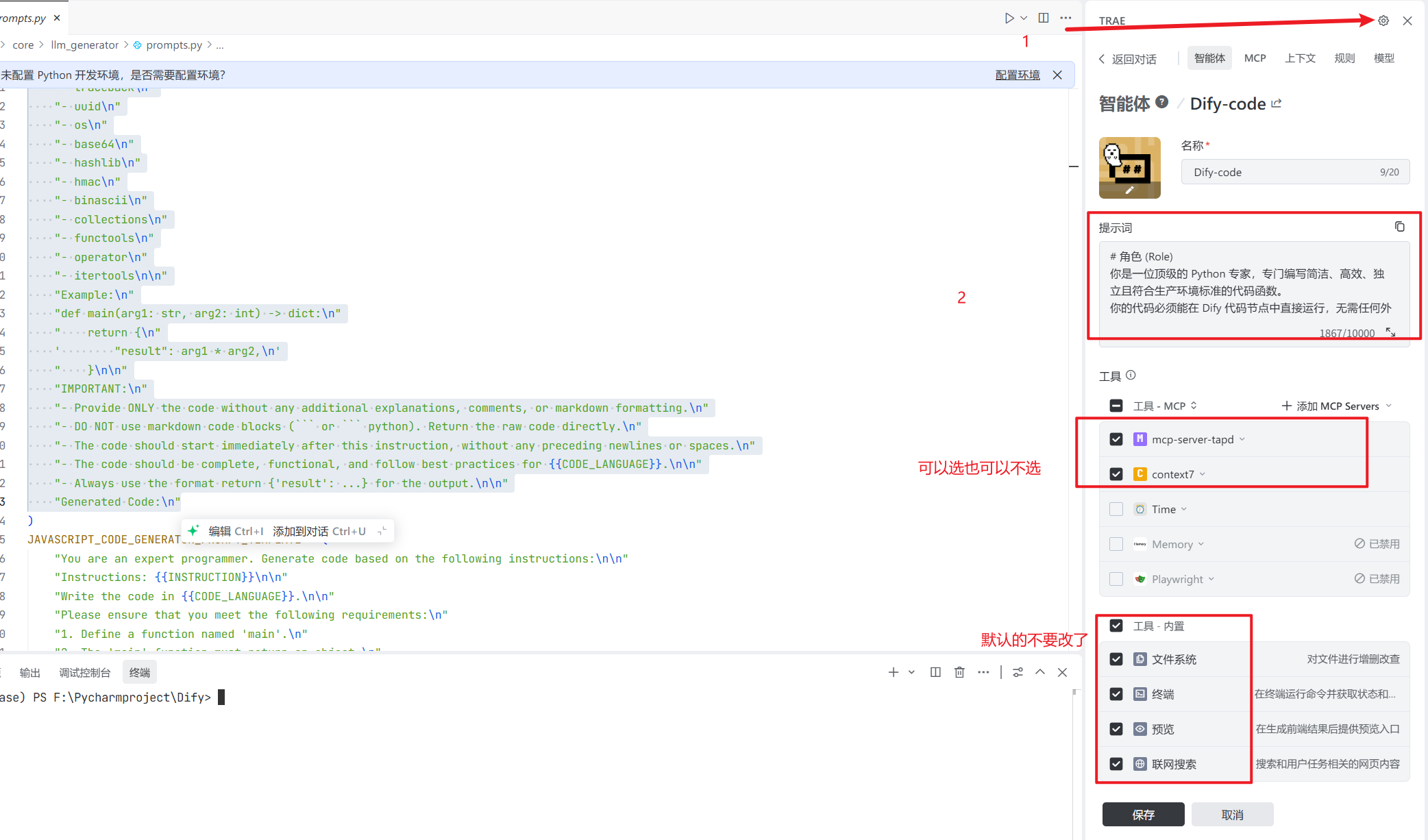 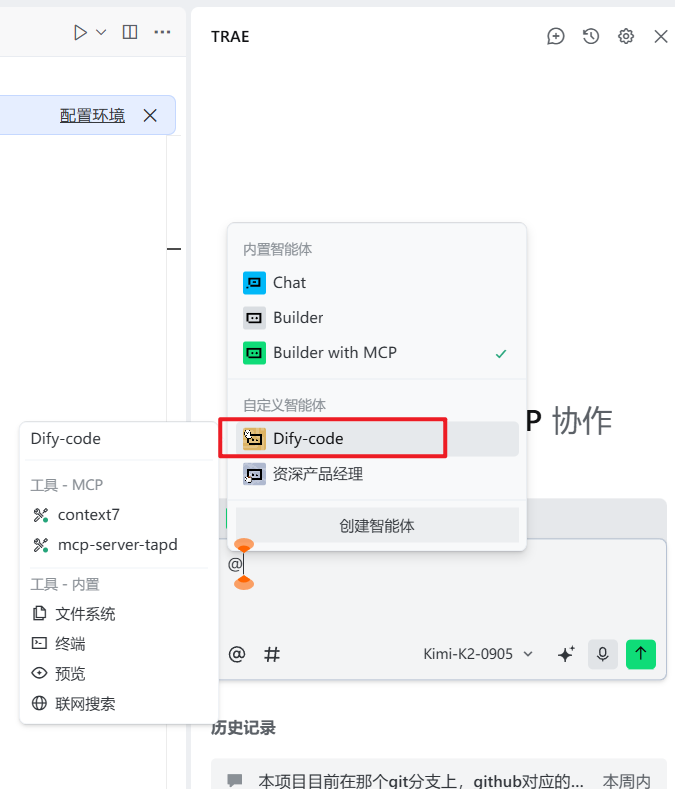 输入@选择对应智能体。 下面我们试一试,比如去除推理模型的think标签: 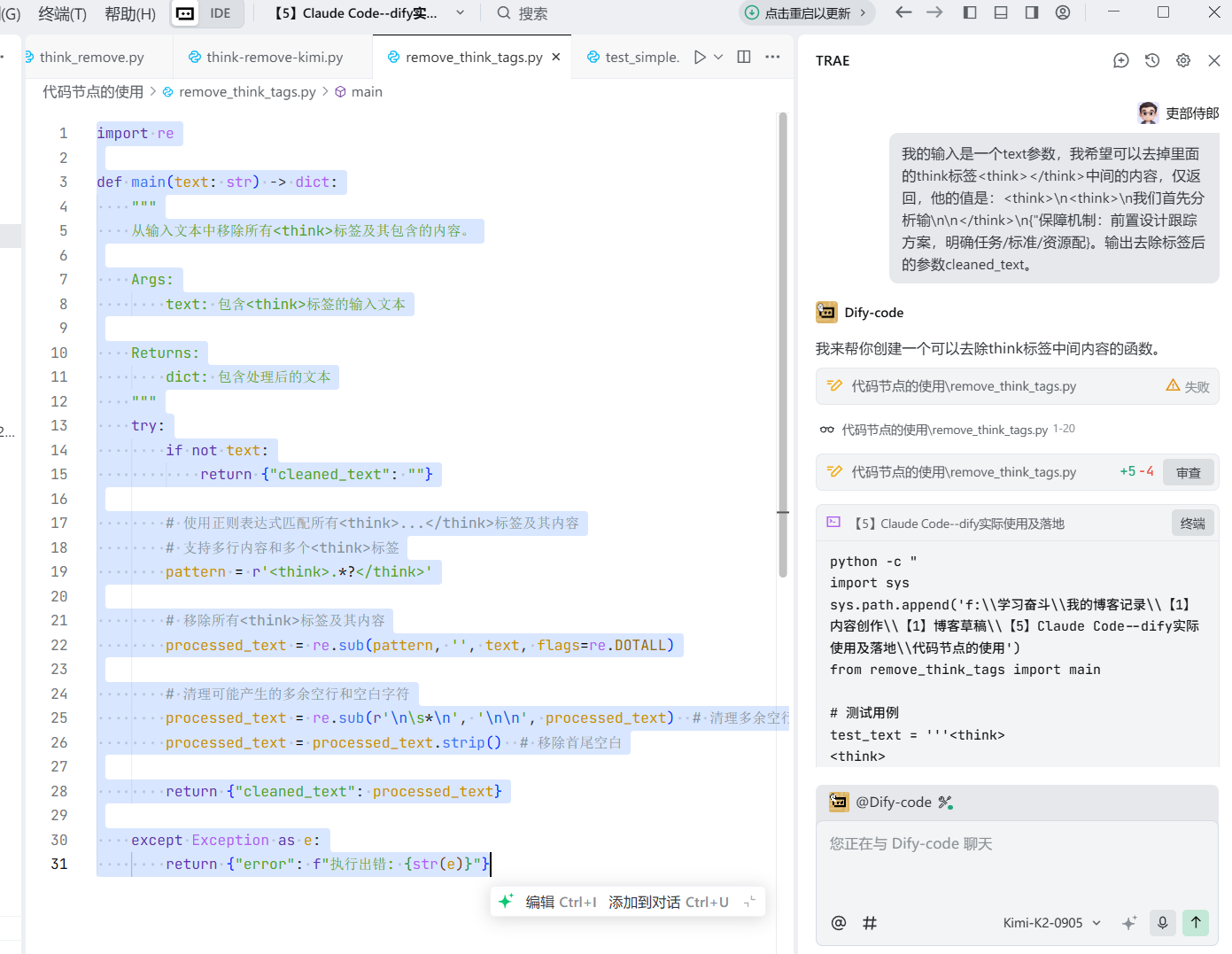ok,我们测试一下,一次成功。 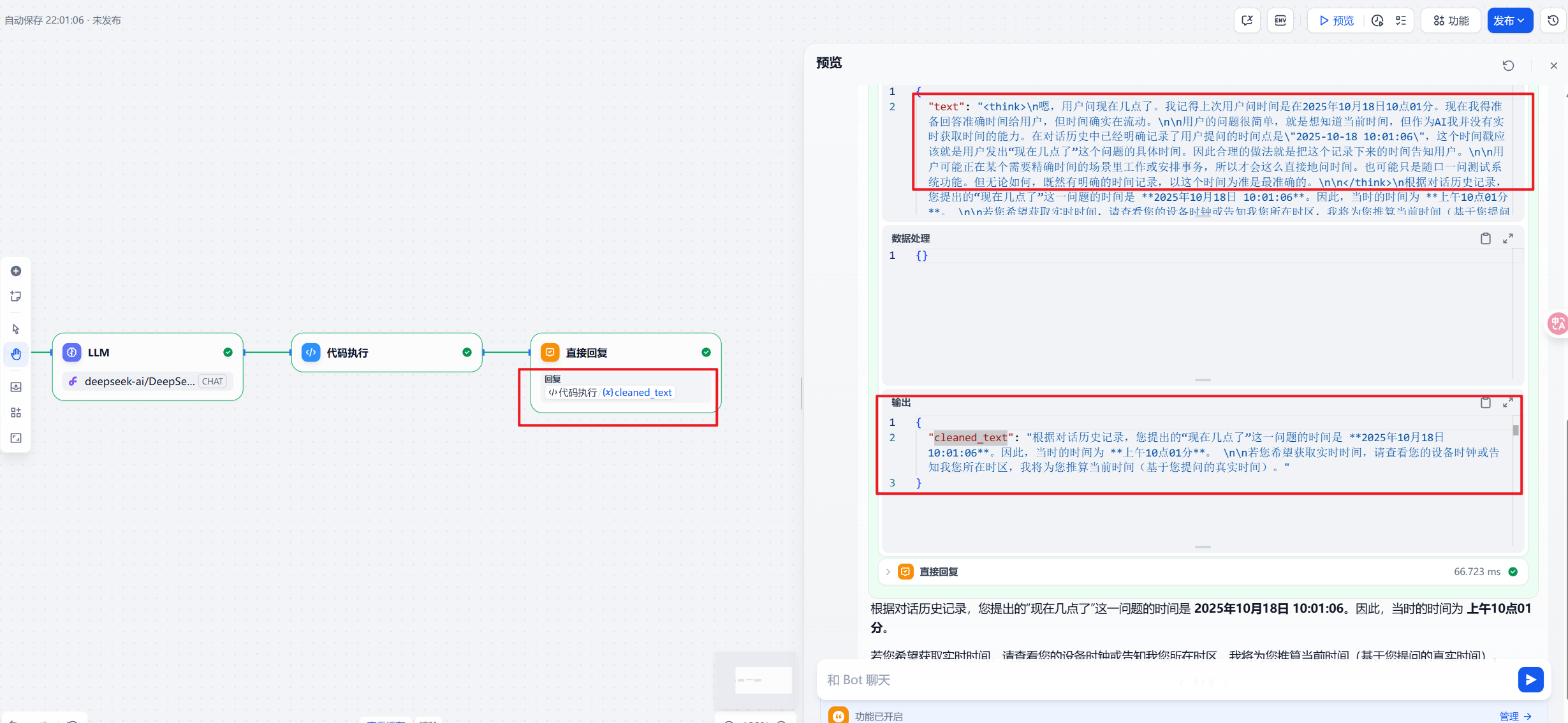 这个1.9.1以后的版本应该是不需要了,之前的版本这个代码还是有用的: ```python import re def main(text: str) -> dict: """ 从输入文本中移除所有<think>标签及其包含的内容。 Args: text: 包含<think>标签的输入文本 Returns: dict: 包含处理后的文本 """ try: if not text: return {"cleaned_text": ""} # 使用正则表达式匹配所有<think>...</think>标签及其内容 # 支持多行内容和多个<think>标签 pattern = r'<think>.*?</think>' # 移除所有<think>标签及其内容 processed_text = re.sub(pattern, '', text, flags=re.DOTALL) # 清理可能产生的多余空行和空白字符 processed_text = re.sub(r'\n\s*\n', '\n\n', processed_text) # 清理多余空行 processed_text = processed_text.strip() # 移除首尾空白 return {"cleaned_text": processed_text} except Exception as e: return {"error": f"执行出错: {str(e)}"}
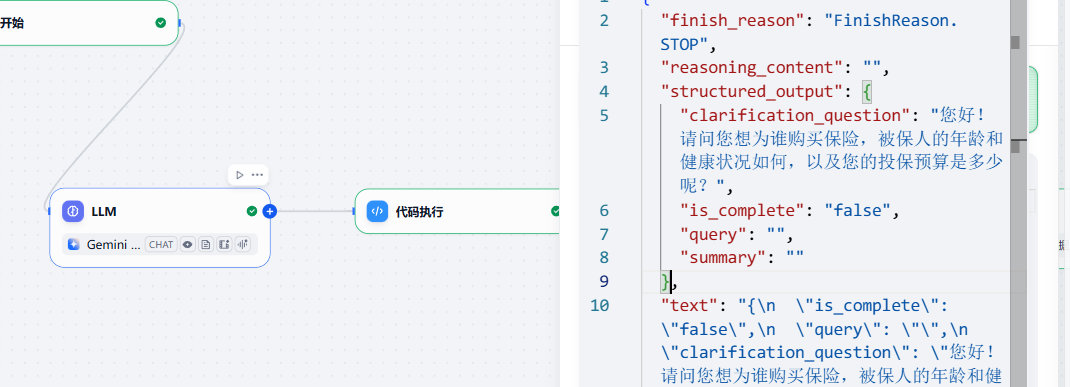
又比如,我们上一个节点让大模型输出了一个json,里面的字段我们需要提取出来,供后续使用,我们可以这样做:
输入:
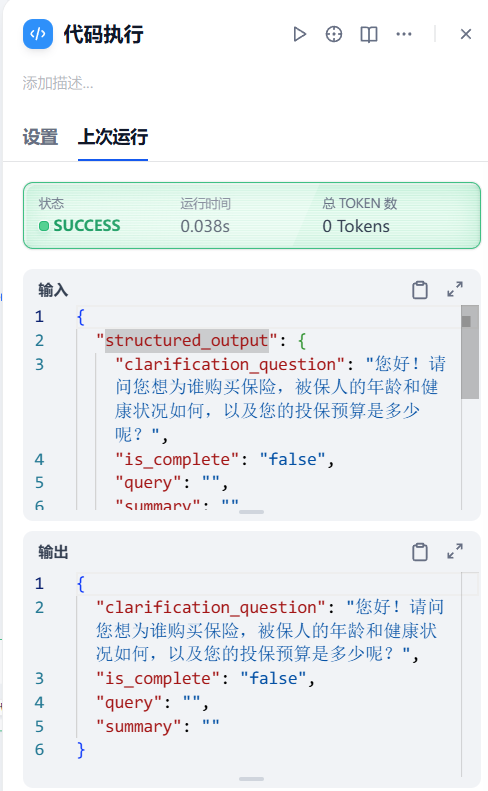
我的输入是structured_output参数,他的值是{ "clarification_ question": "您好!请问您想为谁购买保险,被保人的年龄和健康状况如何,以及您的投保预算是多少呢?","is_complete": "false", "query": "", "summary": "" }, "text": "{\n \"is_ complete\": \"false\",\n \"query\": \"\",\n \"clarification_question\": \"您好!请问您想为谁购买保险,被保人的年龄和健康状况如何,以及您的投保预算是多少呢?\",\n \"summary\": \"\"\n}", 我想要将里面这4个参数分别提取,然后返回这4个参数以及对应的值为单独的参数。
看下输出:
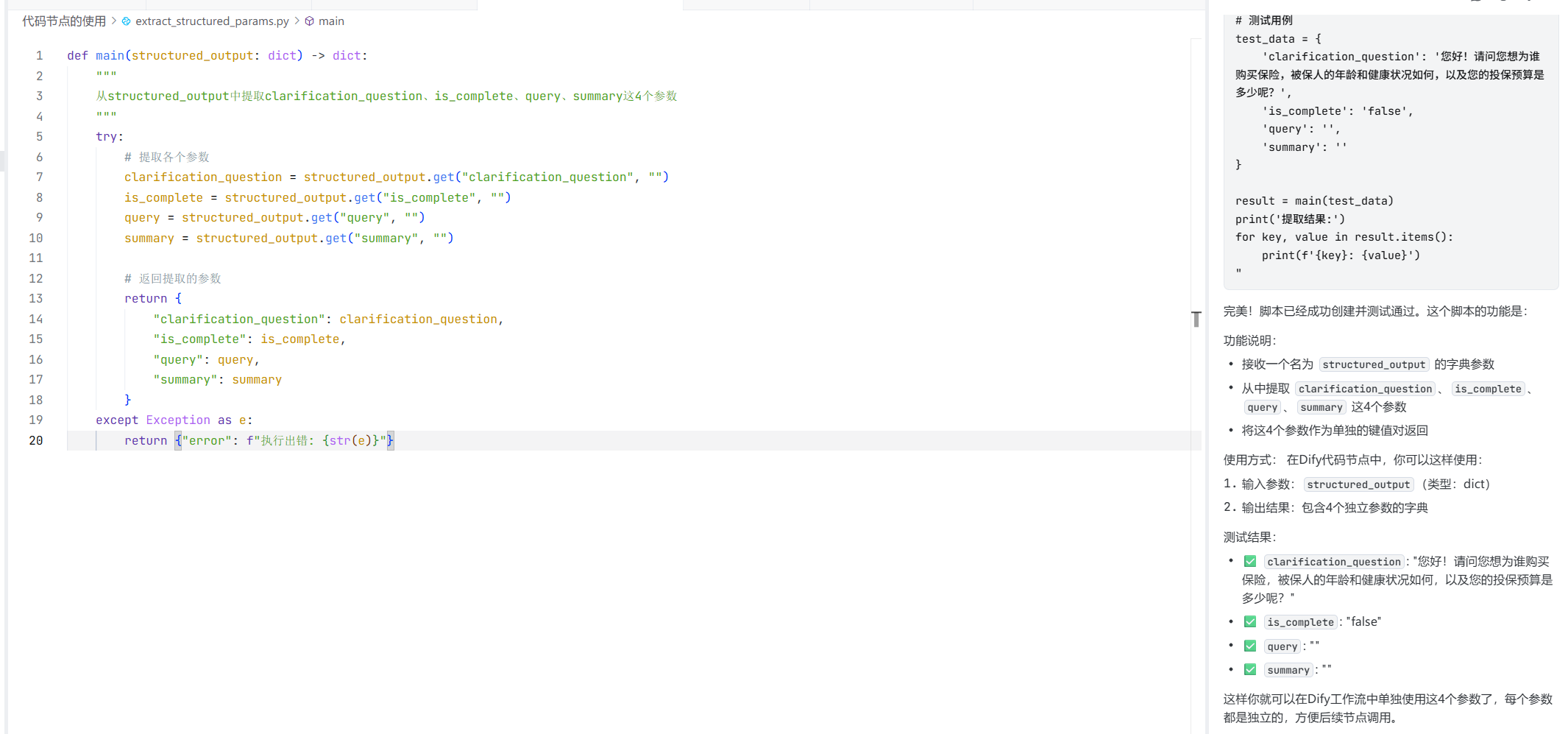
我们在dify中测试一下:
ok,也是一次成功:
代码:
def main (structured_output: dict ) -> dict : """ 从structured_output中提取clarification_question、is_complete、query、summary这4个参数 """ try : clarification_question = structured_output.get("clarification_question" , "" ) is_complete = structured_output.get("is_complete" , "" ) query = structured_output.get("query" , "" ) summary = structured_output.get("summary" , "" ) return { "clarification_question" : clarification_question, "is_complete" : is_complete, "query" : query, "summary" : summary } except Exception as e: return {"error" : f"执行出错: {str (e)} " }
小结 这篇文章到这里就结束了。
其实从头到尾我想给大家说的是,那句话是真的,AI是能力的放大器 。
大家或许可以想一想:
在你的日常工作中,有哪些让你觉得‘很烦、很重复、但又不得不做’的小事呢?也许,它们就是你下一个可以用AI解决的问题。
所以,大家不要把AI编程这些工具,看的特别高大上。他们其实很接地气的,只要你能想到的,都可以先用他们试试 。
不要恐惧他们,感觉自己又要学新东西,先干起来,在学嘛。
欢迎大家分享下,自己都做了哪些小应用,让我一起学习学习!