在这篇文章里,我想和大家分享一下我是如何一步步建立一个问答助手Demo的经历。过程中遇到了一些挑战,但同时也找到了解决办法,希望能给正在尝试类似项目的朋友们带来一点帮助和启发。
关键词:Dify 智能助手 记忆 多轮问答
1. 初版Demo
创建应用
首先,我们打开Dify,选择创建空白应用,随意取一个名字,创建一个chatflow。
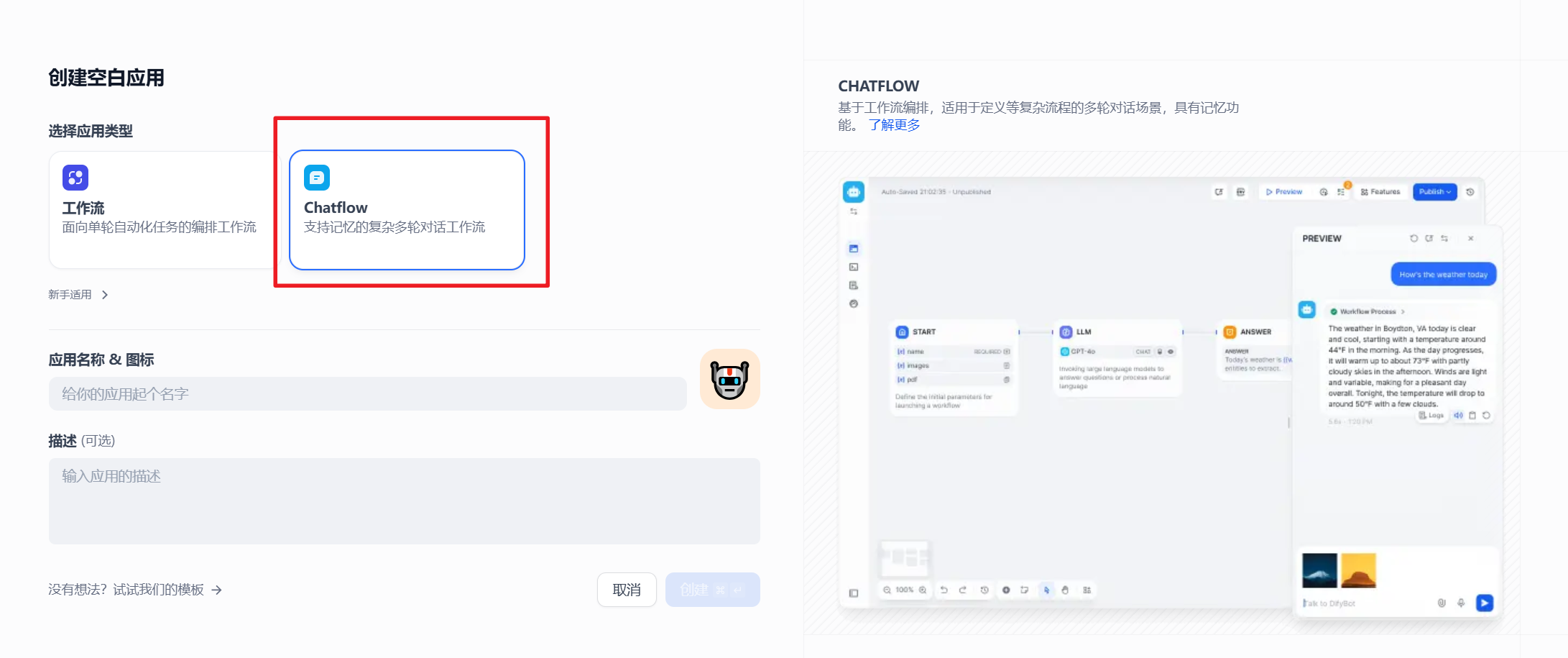
创建应用后,打开界面如下,则直接就是
开始—–>大模型——>直接回复。
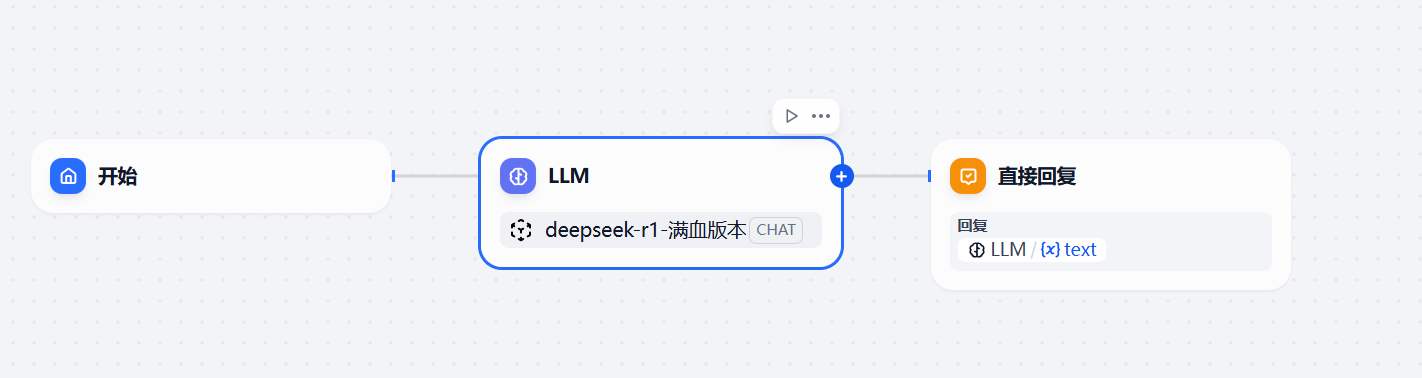
按照常规思路,很显现,现在需要一个知识库,比如用于回答公司内部的政策。所以我们需要加一个知识库节点。

ok,现在按照顺序,明显我们需要开始准备知识库了。
知识库的简单说明
_一个问答助手,能不能准确的回复用户的问题,主要在于3个方面_:
- 知识库是不是构建的相对比较好,比如分块逻辑,块大小,检索逻辑等等。
- LLM节点的提示词写的是不是足够好,足够稳定。
- 是不是很好的能理解用户的问题。
首先,构建知识库的时候,不要寄希望于丢几个 PDF 给嵌入模型,就可以有很好的效果。
比如我有一个PDF文件,我先实验了一下直接导入行不行,选择知识库—新建知识库—选择上传文件。
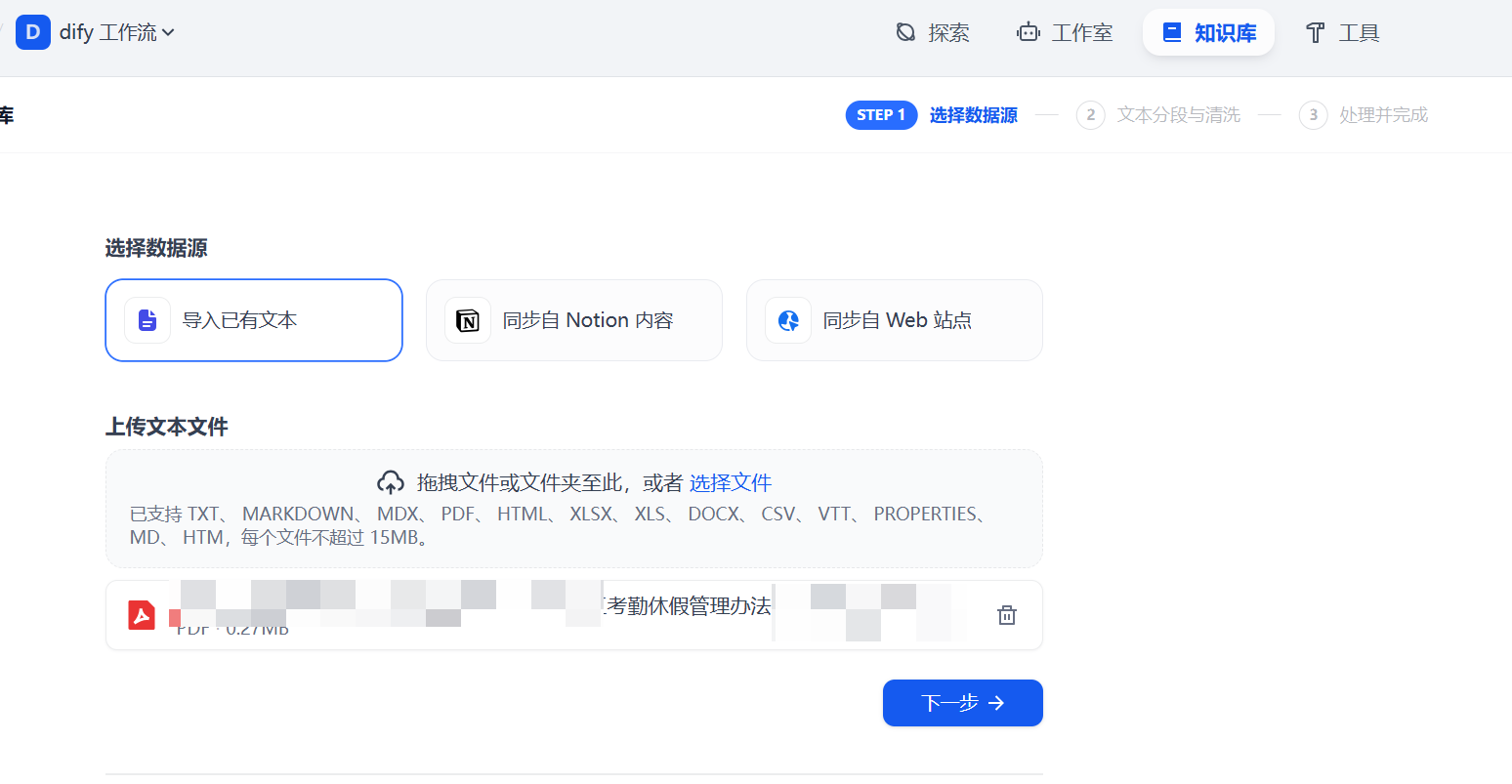
这里,我就不详述实验过程了,我实验了通用分段,父子分段,试验了QA,但是发现效果不太好。我认为可能是PDF文件格式的问题。所以最后,我决定先对PDF进行加工,将它改成了markdown格式的文件。
当然,针对于这种咨询性的知识库,其实应该仔细实验一下QA,效果估计不错,但是我是做demo(其实算是正式应用),这里因为我自己实验不同问题,相对来说回答的不错,我就没有深入搞一下QA。
当然知识库的建立那又是一个非常重要的专题,我们今天的主题是问答助手,所以在知识库这里就不太多赘述了。
最终还是使用父子分段,#做父块,##做子块标识(这里大家可别把分段标识符固定成标点符号了,其实文字也是可以的,比如“第”第几章。。)
好了,上提示词:
# 角色
你是一个专业、严谨的人力资源(HR)智能助手,现在是2025年。
# 任务
你的唯一任务是根据下面[知识库检索结果]中提供的信息,来回答用户的[提问]。
# 核心规则
1. **绝对忠诚**:你必须,且只能使用[知识库检索结果]中的内容来组织你的回答。严禁使用任何外部知识或进行任何形式的推理、猜测。
2. **内容为王**:如果[知识库检索结果]中明确包含了答案,请直接、清晰地进行回答。
3. **知之为知之**:如果[知识库检索结果]中的信息不足以或完全不能回答用户的[提问],你**绝不允许**编造答案。你必须明确告知用户,你无法在现有的制度文件中找到相关信息。
- **[知识库检索结果]**:
|
接下来我们就可以开始测试了。
增加问题分类器
上面只是解决了考勤问题,下面我们增加一个一个分支用于回答用户的其他问题,比如福利,比如补充医疗的理赔。
这一步的操作比较简单,就不详细说了。
这个时候,chatflow 就变成这个样子了:
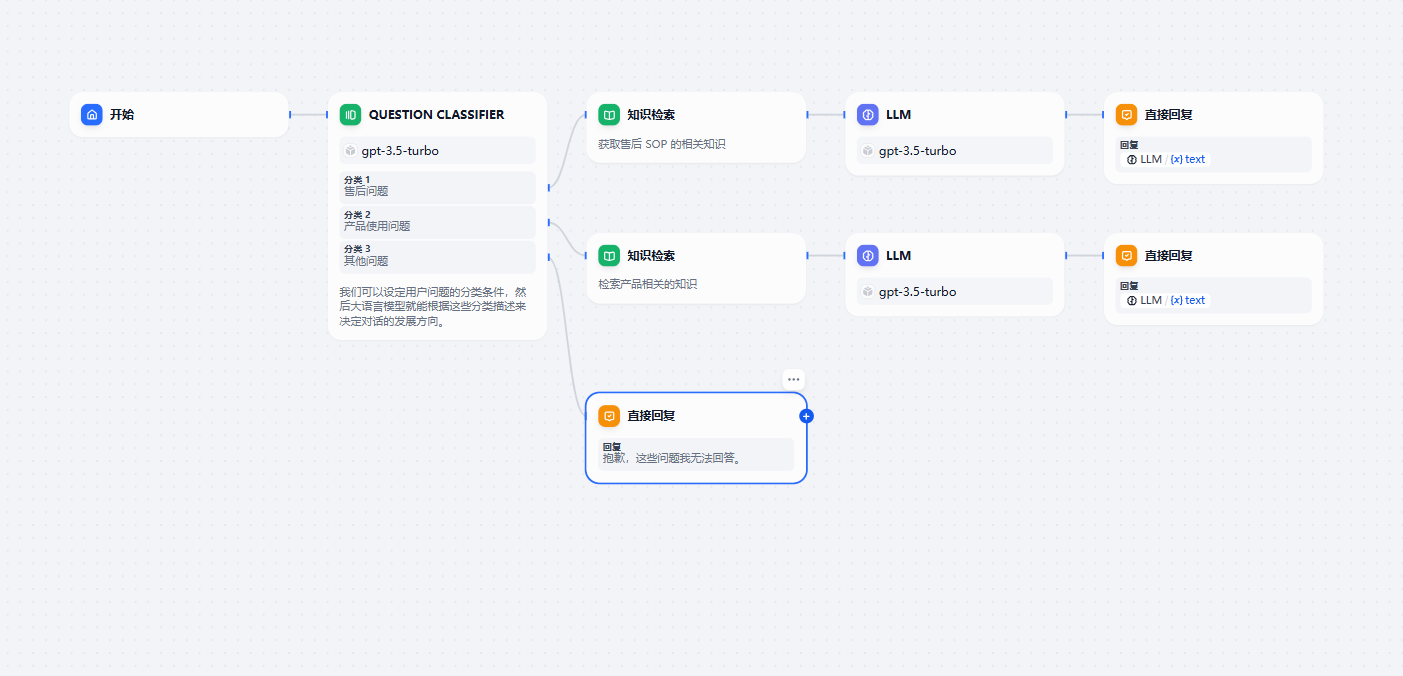
2. 正式版本
因为本质上,我们现在做的这个问答助手,还是一个 chat,所以他是需要记忆的。要用明白记忆,我们就得先明白这个记忆是如何运行的。
Dify 中记忆工具的运行机制探索
关闭记忆
依次输入
看下模型请求:

{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "使用以下上下文作为你所学习的知识,放在<context></context> XML标签内。\n<context>\n{{#context#}}\n</context>\n当回答用户时:\n如果你不知道,就说你不知道。如果你不确定时不知道,寻求澄清。\n避免提及你从上下文中获取的信息。\n并根据用户问题的语言进行回答。",
"files": []
},
{
"role": "user",
"text": "用户问题:1+4",
"files": []
}
],
"usage": {
"prompt_tokens": 213,
"prompt_unit_price": "0",
"prompt_price_unit": "0",
"prompt_price": "0",
"completion_tokens": 5,
"completion_unit_price": "0",
"completion_price_unit": "0",
"completion_price": "0",
"total_tokens": 218,
"total_price": "0",
"currency": "USD",
"latency": 0.33365140948444605
},
"finish_reason": "stop",
"model_provider": "langgenius/openai_api_compatible/openai_api_compatible",
"model_name": "deepseek-v3"
}
|
可以看到,每次只保留了最新的请求的问题。
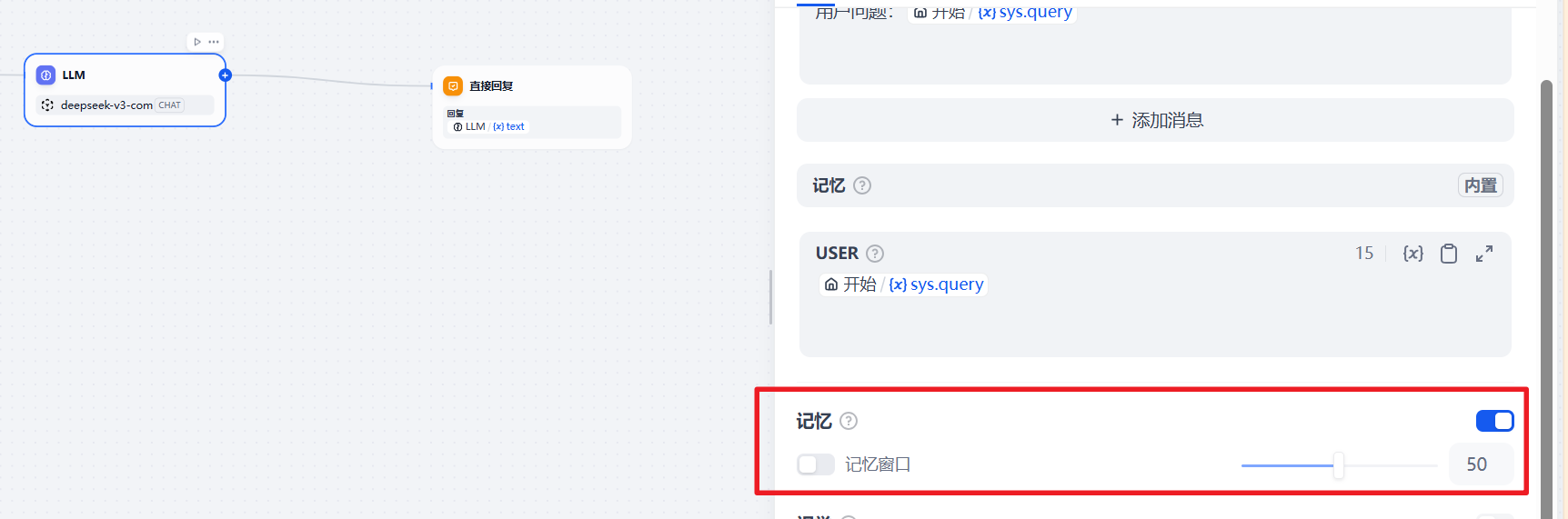
打开记忆
我们先打开记忆,不打开记忆窗口。
然后我们依次输入
然后看下模型的请求:
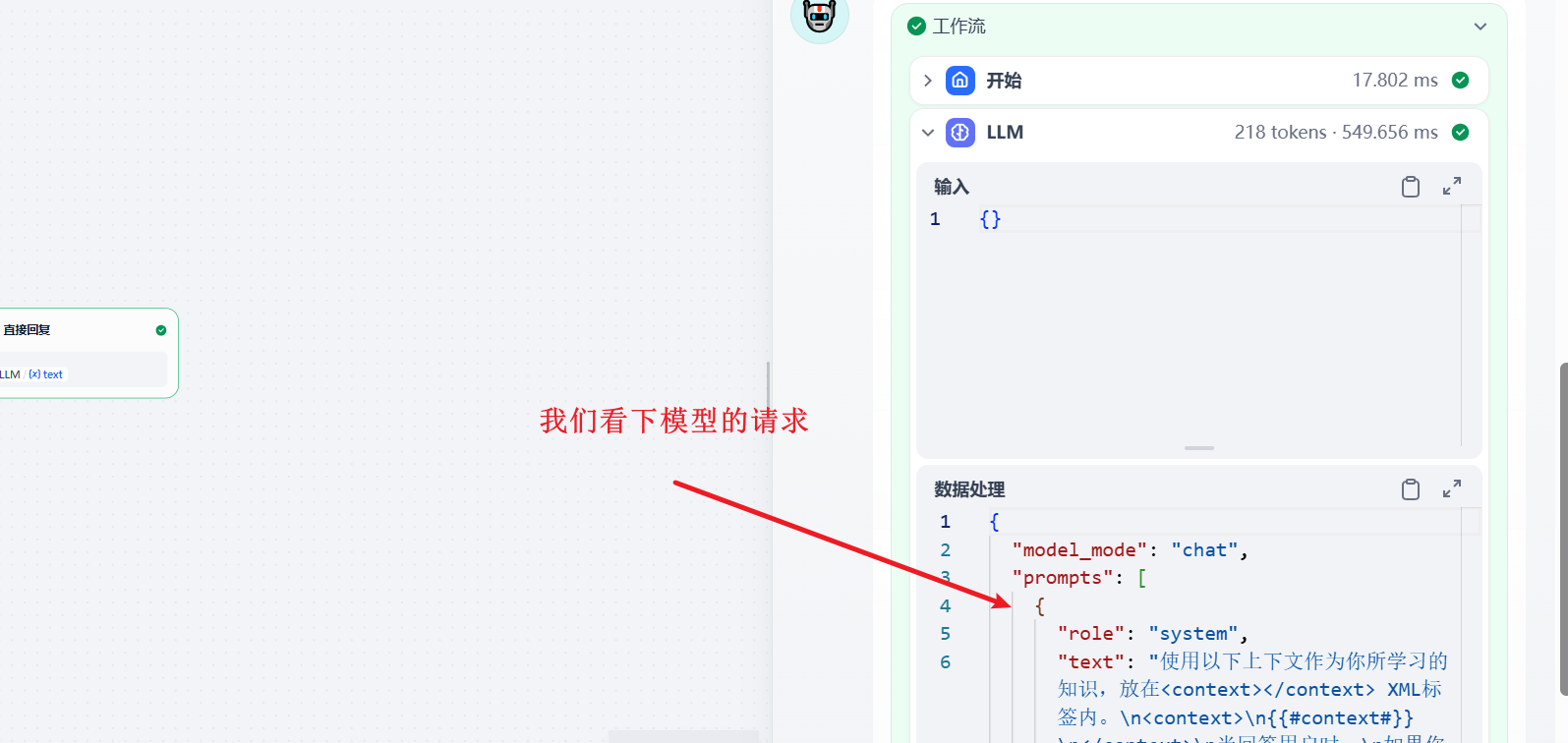
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "使用以下上下文作为你所学习的知识,放在<context></context> XML标签内。\n<context>\n{{#context#}}\n</context>\n当回答用户时:\n如果你不知道,就说你不知道。如果你不确定时不知道,寻求澄清。\n避免提及你从上下文中获取的信息。\n并根据用户问题的语言进行回答。",
"files": []
},
{
"role": "user",
"text": "用户问题:1+5",
"files": []
},
{
"role": "user",
"text": "1+1",
"files": []
},
{
"role": "assistant",
"text": "1 + 1 = 2",
"files": []
},
{
"role": "user",
"text": "1+2",
"files": []
},
{
"role": "assistant",
"text": "1 + 2 = 3",
"files": []
},
{
"role": "user",
"text": "1+3",
"files": []
},
{
"role": "assistant",
"text": "1 + 3 = 4",
"files": []
},
{
"role": "user",
"text": "1+4",
"files": []
},
{
"role": "assistant",
"text": "1 + 4 = 5",
"files": []
},
{
"role": "user",
"text": "1+5",
"files": []
}
],
"usage": {
"prompt_tokens": 213,
"prompt_unit_price": "0",
"prompt_price_unit": "0",
"prompt_price": "0",
"completion_tokens": 5,
"completion_unit_price": "0",
"completion_price_unit": "0",
"completion_price": "0",
"total_tokens": 218,
"total_price": "0",
"currency": "USD",
"latency": 0.4152184668928385
},
"finish_reason": "stop",
"model_provider": "langgenius/openai_api_compatible/openai_api_compatible",
"model_name": "deepseek-v3"
}
|
可以看到他将每次的 user 和模型回答 assistant 都记录下来了。最上面和最下面的 user 是用户的本次输入。
打开记忆窗口
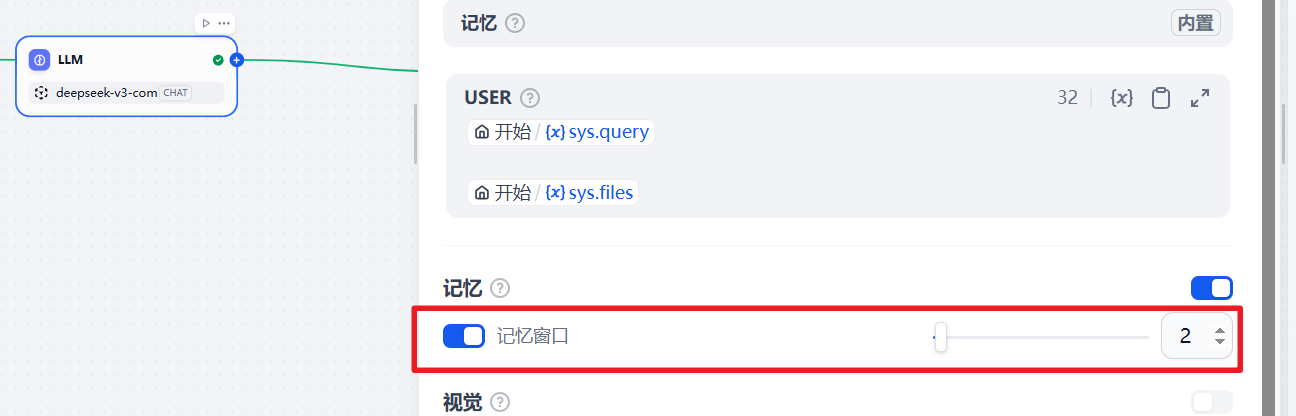
现在我们打开记忆窗口,继续输入上面的内容:
我们接着看请求参数:
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "使用以下上下文作为你所学习的知识,放在<context></context> XML标签内。\n<context>\n{{#context#}}\n</context>\n当回答用户时:\n如果你不知道,就说你不知道。如果你不确定时不知道,寻求澄清。\n避免提及你从上下文中获取的信息。\n并根据用户问题的语言进行回答。",
"files": []
},
{
"role": "user",
"text": "用户问题:1+5",
"files": []
},
{
"role": "user",
"text": "1+4",
"files": []
},
{
"role": "assistant",
"text": "1 + 4 = 5",
"files": []
},
{
"role": "user",
"text": "1+5\n\n[]",
"files": []
}
],
"usage": {
"prompt_tokens": 213,
"prompt_unit_price": "0",
"prompt_price_unit": "0",
"prompt_price": "0",
"completion_tokens": 5,
"completion_unit_price": "0",
"completion_price_unit": "0",
"completion_price": "0",
"total_tokens": 218,
"total_price": "0",
"currency": "USD",
"latency": 0.389557683840394
},
"finish_reason": "stop",
"model_provider": "langgenius/openai_api_compatible/openai_api_compatible",
"model_name": "deepseek-v3"
}
|
可以看到,他只保留了最新一次和上一次的 user 问题。
记忆功能总结
| 记忆设置 |
发送给模型的内容 |
效果 |
| 关闭记忆 |
仅当前的用户输入 |
无上下文,一问一答,完全独立 |
| 开启记忆(无窗口) |
完整的对话历史 |
拥有全部上下文,能进行连贯的多轮对话 |
| 开启记忆(有窗口) |
最近的几轮对话历史 |
拥有有限的上下文,只“记得”最近的对话 |
开始实验方案
为了得到比较好的效果,我准备了以下几个方案:
- 打开问题分类节点的 记忆。
- 打开 LLM 节点的 记忆。
- 新增一个 query 改写节点,打开 记忆。
前面 2 个方案,没什么稀奇的,第 3 个方案,是我在研究前两个方案时,思索的一个方案。
方案实验
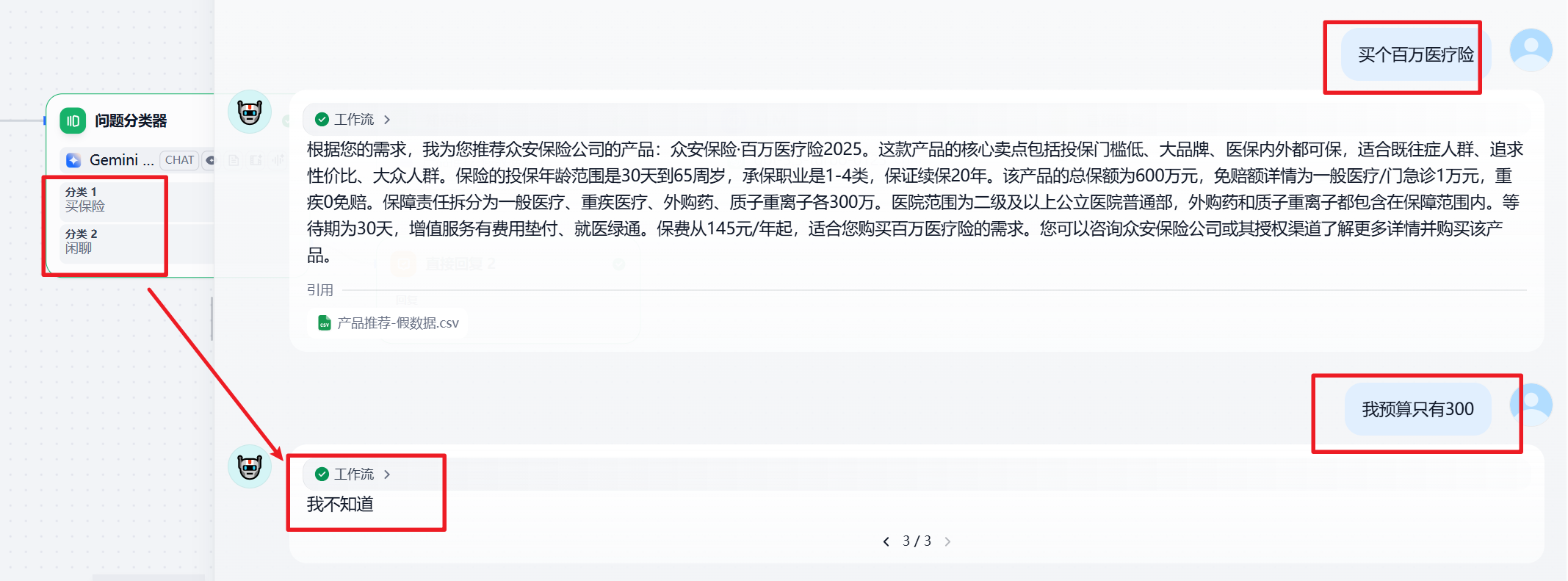
前两个方案在测试时,都碰到了以下问题,会在第三次对话的时候,污染用户的问题。
只打开 LLM 节点,不打开问题分类节点的记忆,会导致分类错误。
比如:
或者会出现知识库内容检索的不精确(因为指代消解等等各种原因):
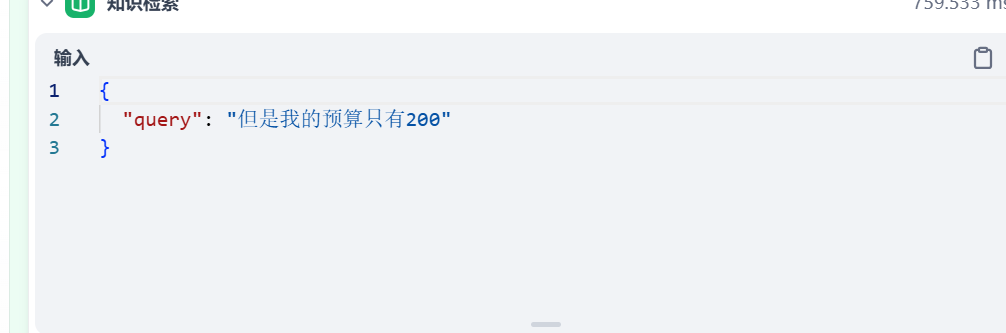
最终造成回复的不准确,甚至无法回复。
而且,还有一个问题,就是,虽然我们打开了问题分类的记忆,而且请求时,也将所有的历史聊天记录发给了模型,但是有时还是会出现分类错误的情况:

因此,我们需要一个问题 query 的改写节点。
用它来尽可能提高问题分类的正确性,并且实现知识库的精确检索。
query 改写节点
这样的话,我们的 chatflow 就变成了这样子。
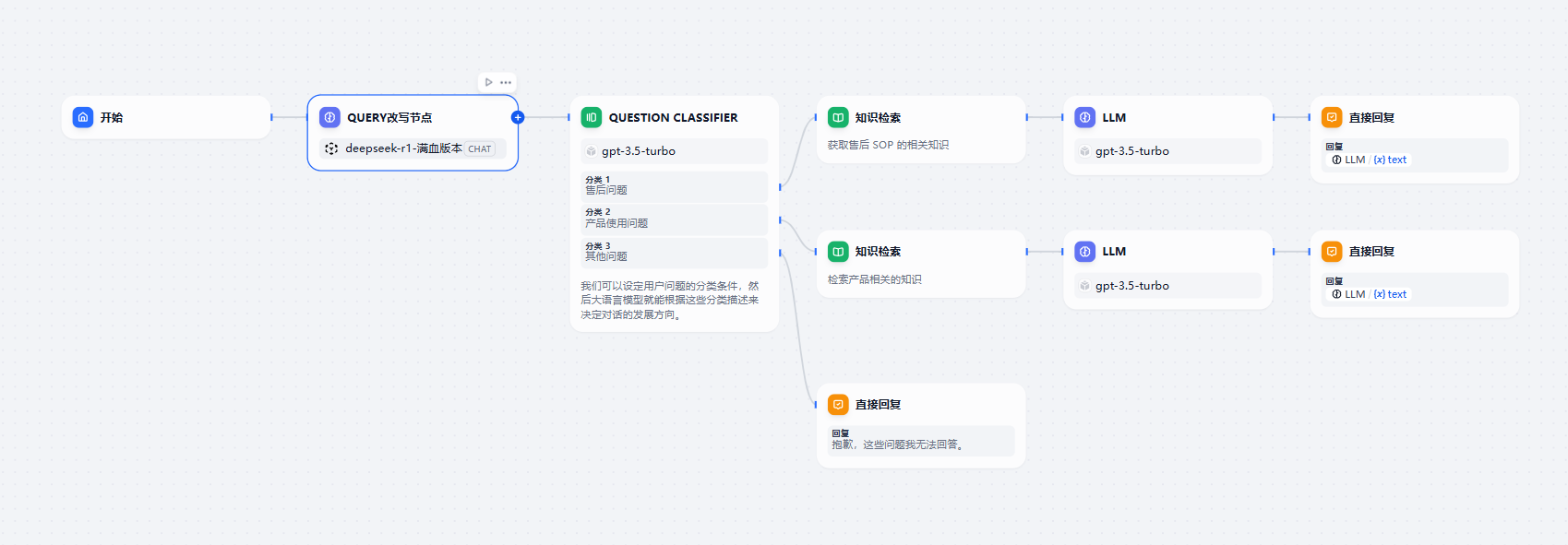
改写节点的提示词如下:
# 角色与任务
你是一个专用于智能客服系统的“用户问题改写专家”。
你的核心任务是:结合上下文对话,将用户当前提出的、可能模糊或有依赖的问题,改写成一个信息完整、意图明确、无需上下文即可独立理解的标准问题。
# 工作原则
1. **联系上下文补全信息**:分析对话历史,弄清用户问题中“它”、“我的”、“那个”等代词的具体指代,并补全问题中被省略的主语或宾语。
2. **判断是否需要改写**:如果用户原问题本身已经是一个完整的标准问题,则无需改写,直接输出原问题。
3. **忠于用户字面意图**:这是最重要的原则。你的任务是让问题变得信息完整,而不是改变用户的提问焦点。
* **例如**:如果用户问的是关于“一般情况”的问题,就绝不能将其改写为针对“他当前个案”的问题。
# 输出要求
* **格式唯一**:最终输出的内容,必须且只能是改写后或无需改写的“标准问题”文本。
* **绝对禁止**:禁止输出任何解释、说明、注释、理由或任何形式的对话。
# 示例
---
**示例 1: (指代消解)**
* **对话历史**: "你好,我想了解一下你们的‘长乐安康’重疾险。"
* **用户当前问题**: "它的等待期是多久?"
* **你的输出**:
“长乐安康”重疾险的等待期是多久?
---
**示例 2: (省略补全)**
* **对话历史**: "给孩子投保补充医疗保险,理赔时需要哪些申请资料?"
* **用户当前问题**: "如果是我自己呢?"
* **你的输出**:
我给自己投保的补充医疗保险,理赔时需要哪些申请资料?
---
**示例 3: (忠于字面意图)**
* **对话历史**: "我上周五提交的理赔申请,现在什么进度了?"
* **用户当前问题**: "一般要审核多久?"
* **你的输出**:
理赔申请的审核一般需要多久?
---
|
这次,我直接关掉了问题分类节点和其他节点大模型的记忆。只打开了 query 改写节点的记忆。
在测试的时候,又发现了新的问题,每次问 3 个问题以上的时候,这个节点改写后的问题,总是会包含知识库的检索结果(当然,中间我多次换过模型,没想明白为什么会出现这个问题)。
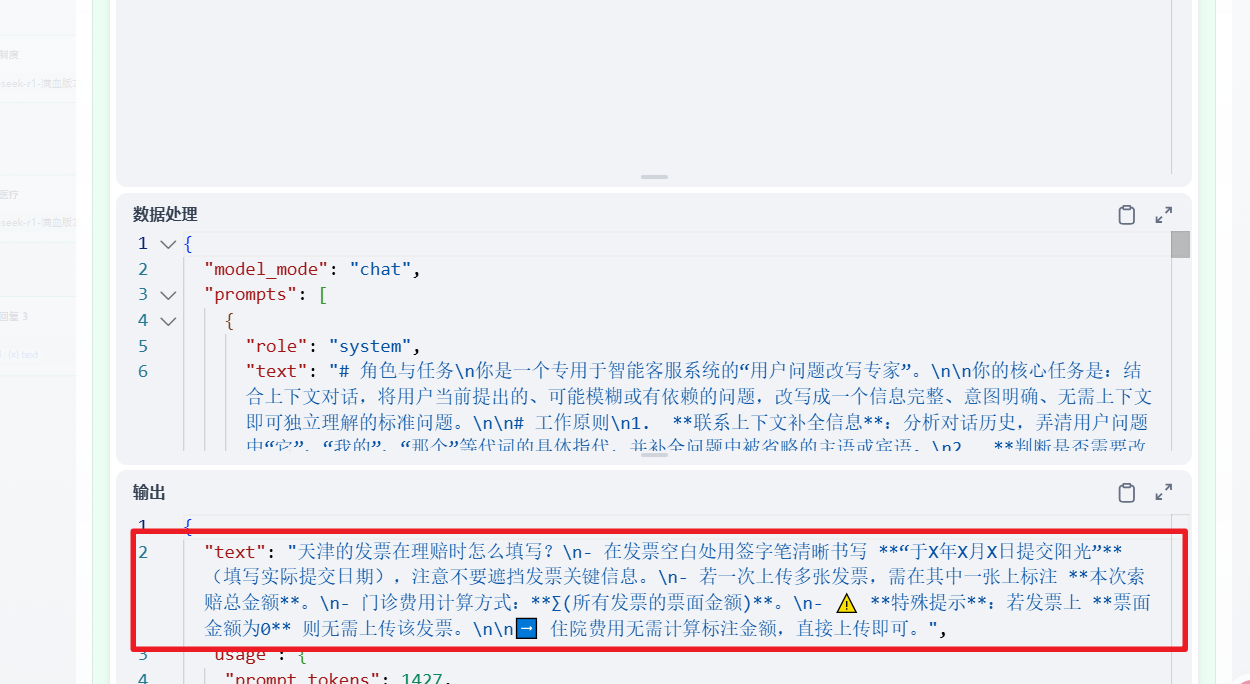
虽然说,在测试的时候,回复的问题只出现了几次不正确的情况,但是我还是很担心,因为历史请求中的assistant 的回答,会污染在这个 query 改写节点新生成的 query。直接导致知识库检索出现问题,最终回答错误。
所以我就在想,我应该怎么解决这个问题。
提示词问题
首先我怀疑的就是提示词导致的问题。
所以我将模型换成了 Gemini1.5flash,然后还将提示词更换成了下面的:
# 角色与任务
你是一个专用于智能客服系统的“用户问题改写专家”。
你的核心任务是:结合上下文对话,将用户当前提出的、可能模糊或有依赖的问题,改写成一个信息完整、意图明确、无需上下文即可独立理解的标准问题。
# 工作原则
1. **联系上下文补全信息**:分析对话历史,弄清用户问题中“它”、“我的”、“那个”等代词的具体指代,并补全问题中被省略的主语或宾语。
2. **判断是否需要改写**:如果用户原问题本身已经是一个完整的标准问题,则无需改写,直接输出原问题。
3. **忠于用户字面意图**:这是最重要的原则。你的任务是让问题变得信息完整,而不是改变用户的提问焦点。
* **例如**:如果用户问的是关于“一般情况”的问题,就绝不能将其改写为针对“他当前个案”的问题。
4. 只关注对话历史中的"role": "user",即用户说的话,忽略模型回复内容。
# 输出要求
* **格式唯一**:最终输出的内容,必须且只能是改写后或无需改写的“标准问题”文本。
* **绝对禁止**:禁止输出任何解释、说明、注释、理由或任何形式的对话。
|
但是我发现,还是会有问题,还是出现了模型回复内容:
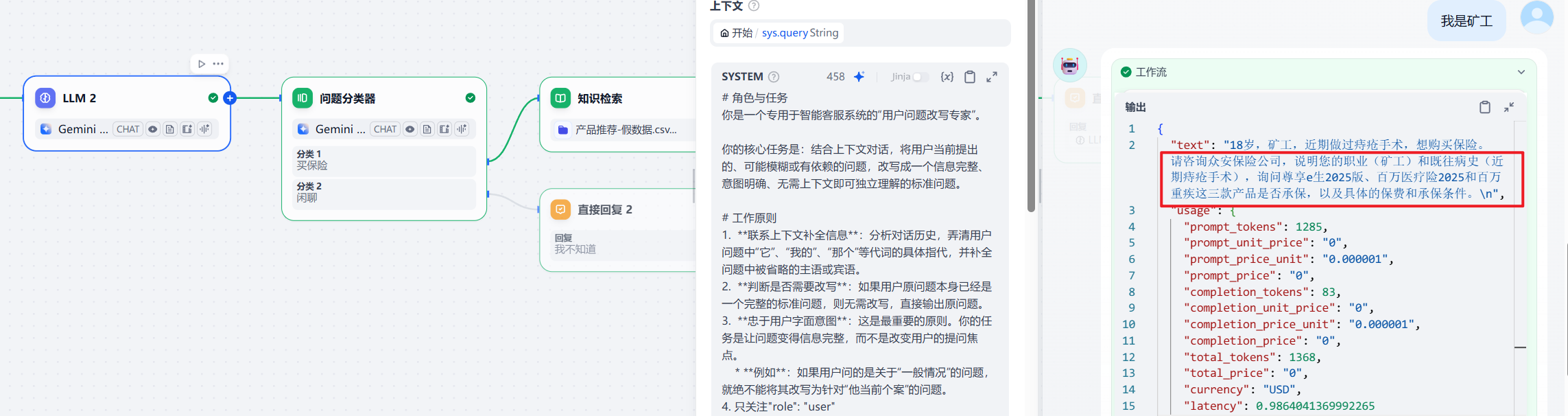
但是我实在是没有理解为什么在 query 改写节点,会出现整合加工这个节点的模型输出结果。
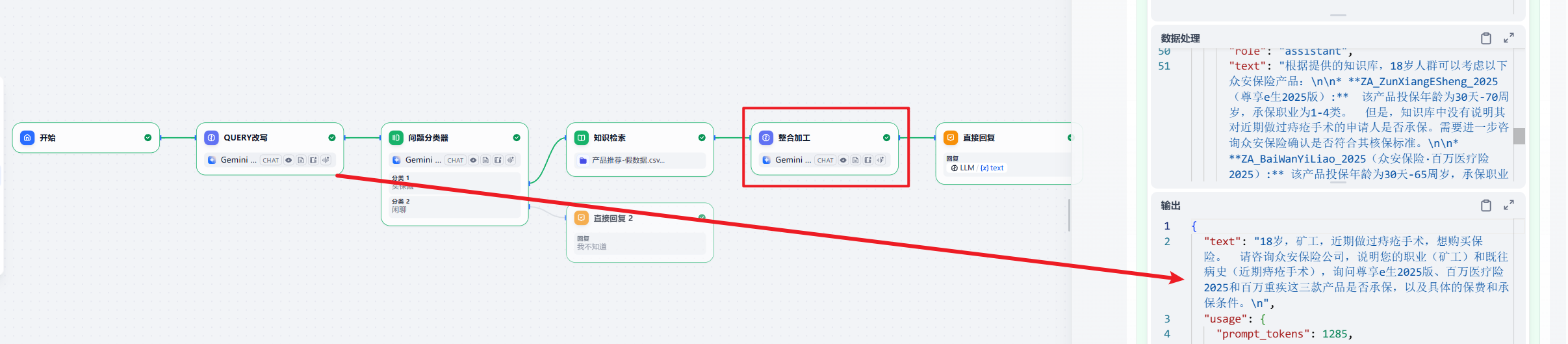
很明显,query 节点的回复,被污染了。
但是上面这个原因,我还没研究明白。
解决方案
经过仔细阅读官方文档,我找到了一个解决方案,使用会话变量。
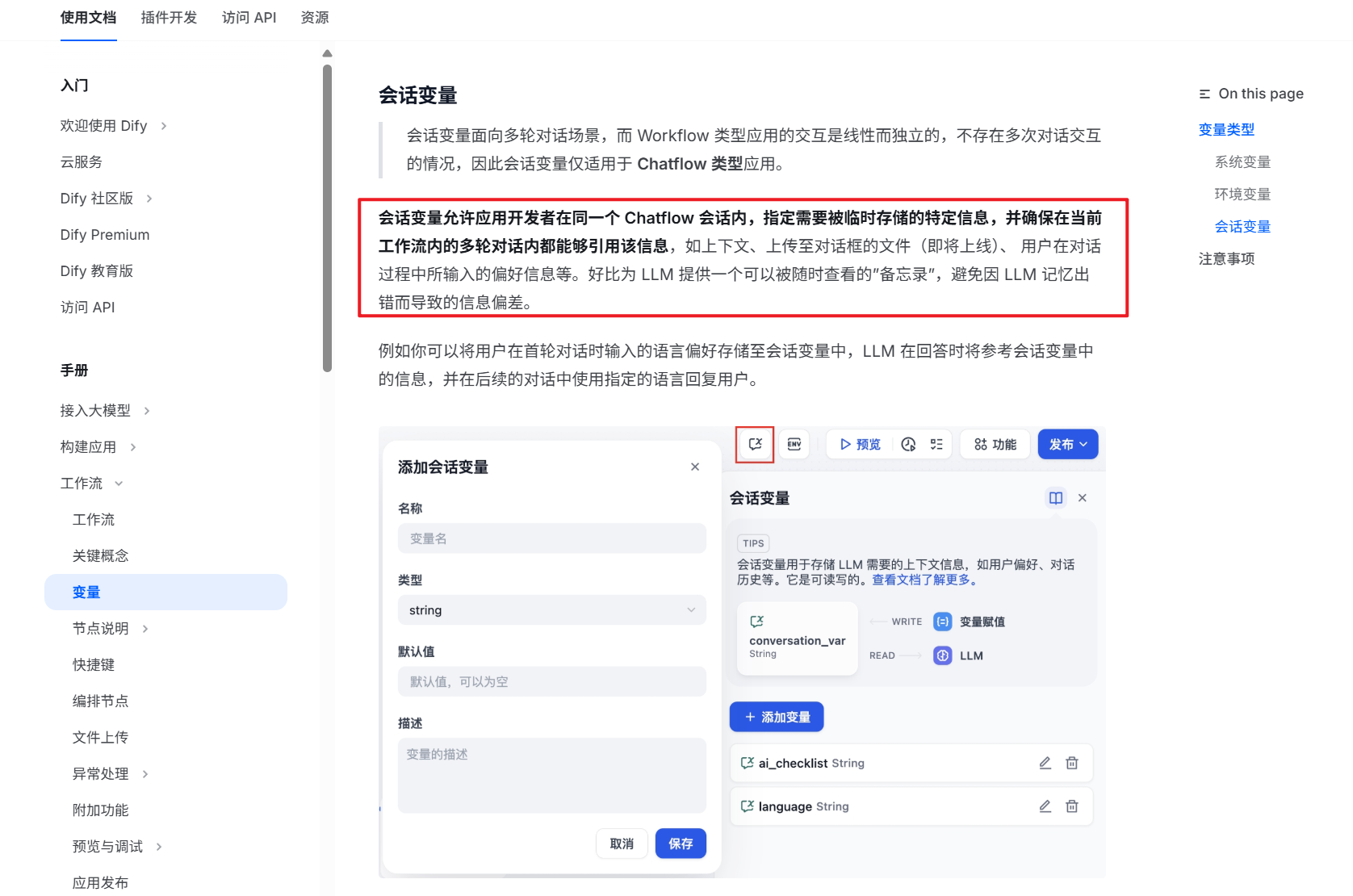
所以,我先增加了一个会话变量 chat_history 用于保存用户的问题。
然后在节点中增加了一个变量赋值。因为我们需要使用用户问题,所以在这里选择了追加。
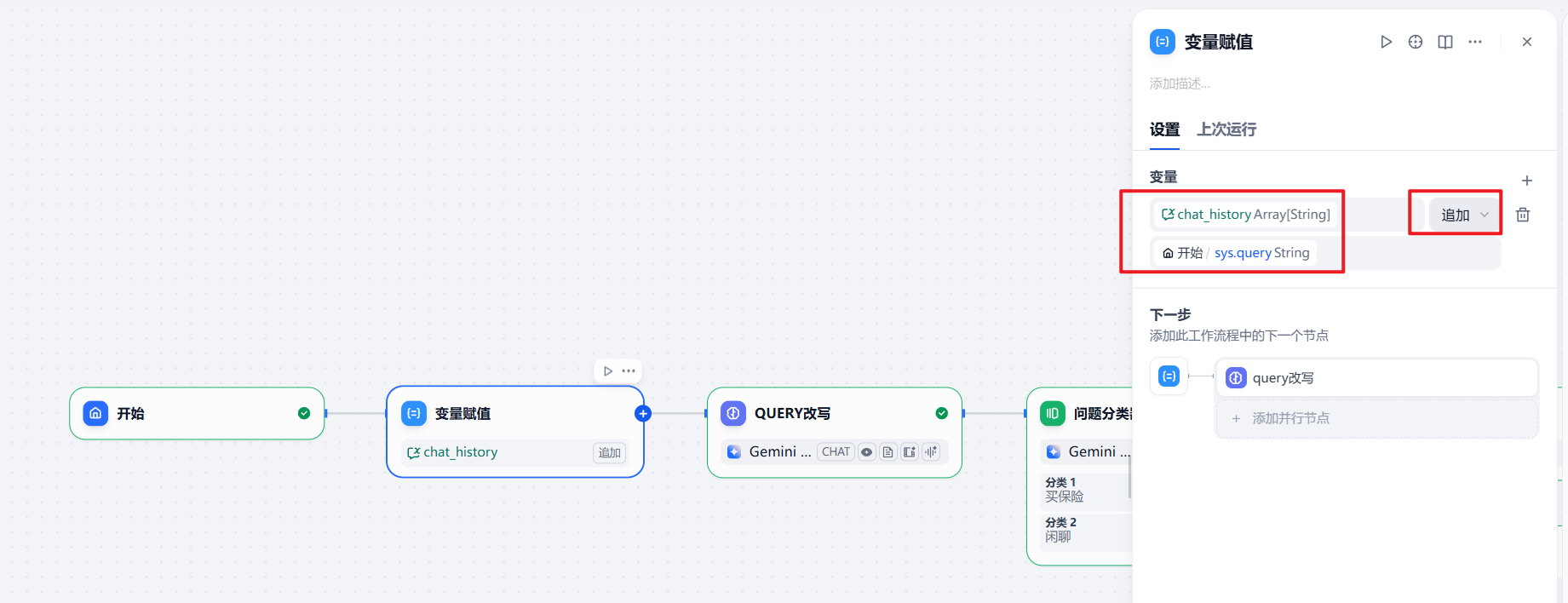
所以,最终我们的 chatflow 就变成了下面的样子:
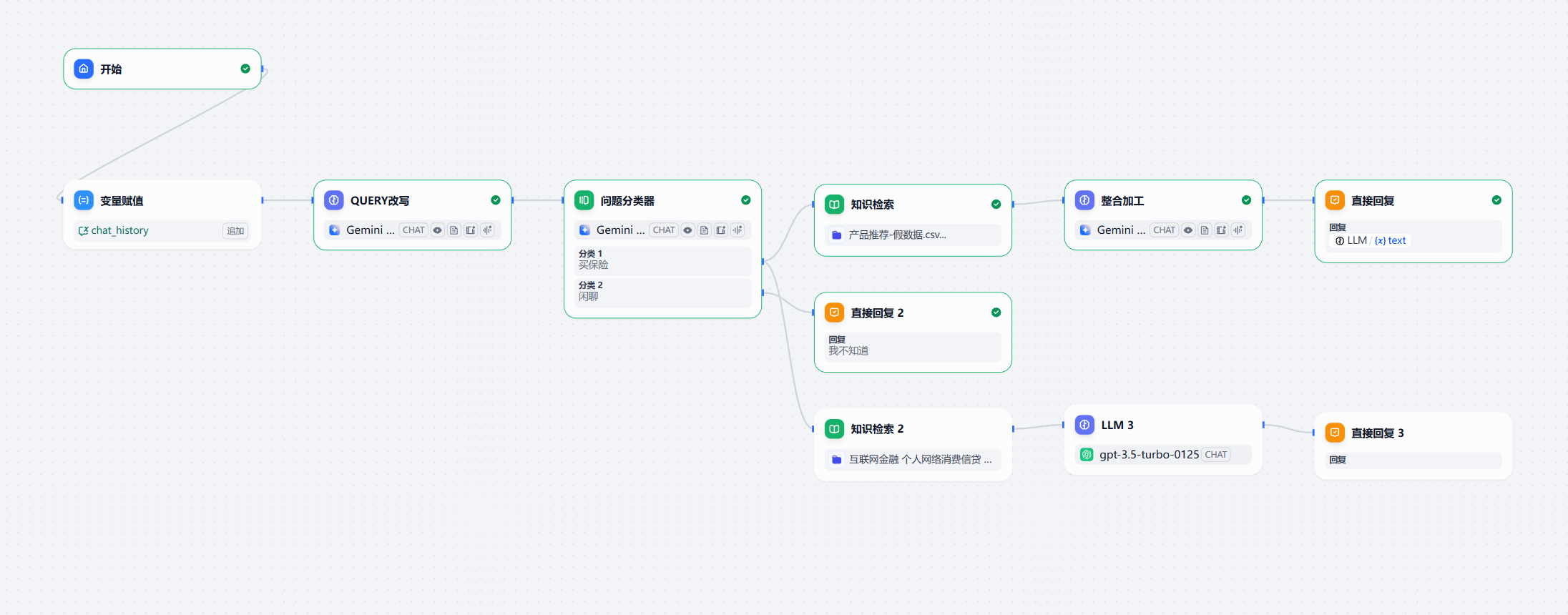
当然那,现在还不够健壮,因为用户可能重复性的输入同一个问题,或者让模型重新回答。
我们开始测试,大家可以看到,用户问题被很好的保留了。
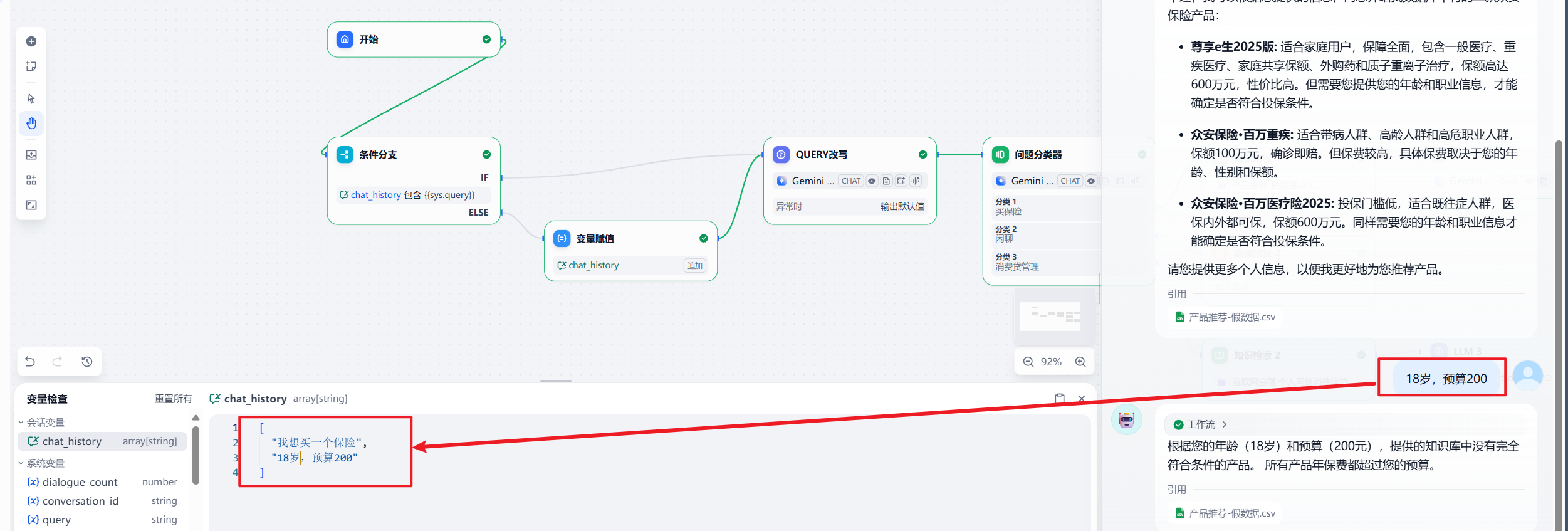
最终方案
为了增加健壮性,我们还需要增加一个代码判断节点,用于判断用户的问题是不是和上一次一样,如果一样,就没必要在 chat_history 中新增了。
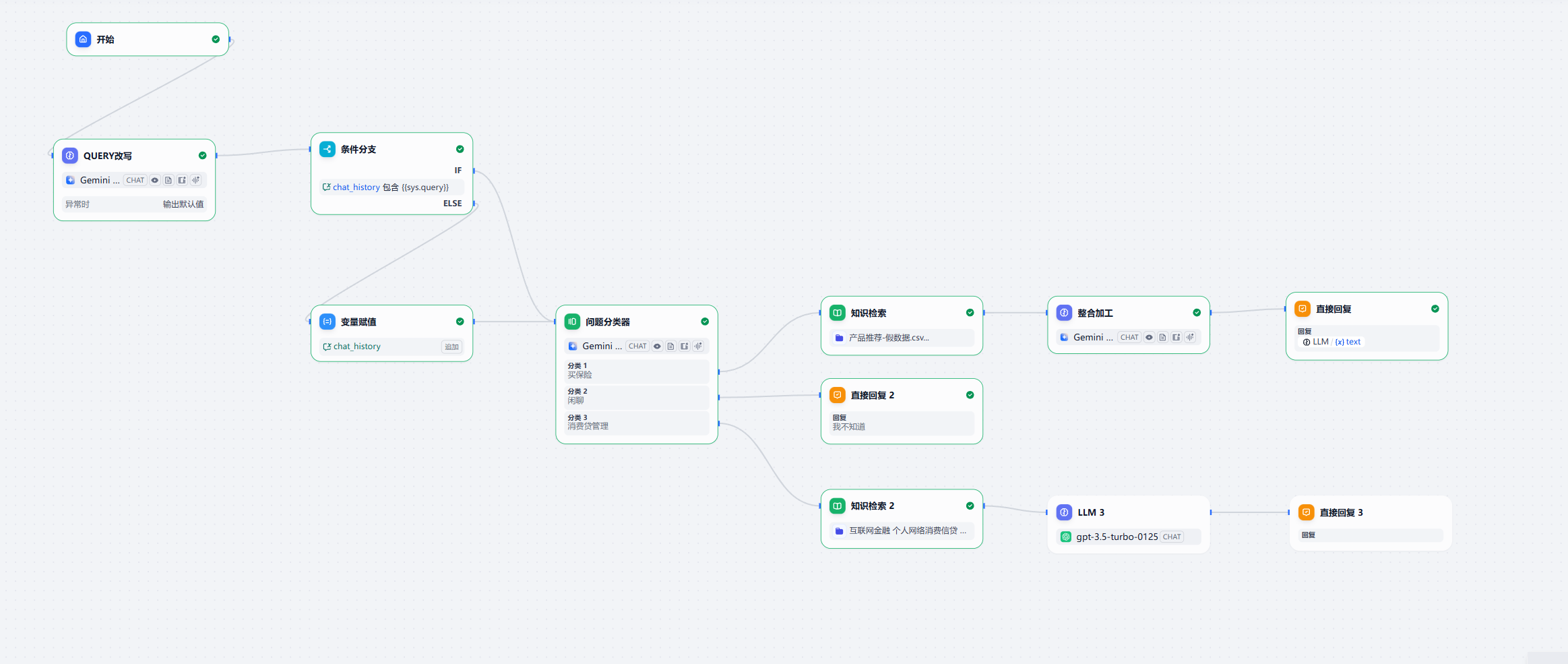
最终的 query 改写提示词:
# 核心任务
你是一个“用户问题改写”模型。你的任务是参考用户历史提问,将用户当前问题改写成一个无需上下文、可独立理解的标准问题。
# 工作流程与规则
输入分析:
用户历史提问:用户在此之前所有说过的话。
用户当前问题:用户最新一句的提问。
改写规则:
补全信息:利用“用户历史提问”作为上下文,补全“当前问题”中省略或指代不明的信息(如主语、宾语、“它”、“那个”等)。
忠于原意:严格遵循用户的字面意图,仅做信息补全,不改变或猜测用户的提问焦点。(例如:问“一般情况”,就不能改写为“我的情况”)。
无需改写则照搬:若“当前问题”本身已是标准问题,直接输出原文,不做任何修改。
输出要求:
唯一格式:输出内容只能是最终的标准问题文本。
严禁额外内容:禁止输出任何形式的解释、注释、理由或对话。
# 示例
示例 1: (补全指代)
用户历史提问: "你好,我想了解一下你们的‘长乐安康’重疾险。"
用户当前问题: "它的等待期是多久?"
你的输出:
“长乐安康”重疾险的等待期是多久?
示例 2: (补全主体)
用户历史提问: "给孩子投保补充医疗保险,理赔时需要哪些申请资料?"
用户当前问题: "如果是我自己呢?"
你的输出:
我给自己投保的补充医疗保险,理赔时需要哪些申请资料?
示例 3: (忠于原意)
用户历史提问: "我上周五提交的理赔申请,现在什么进度了?"
用户当前问题: "一般要审核多久?"
你的输出:
理赔申请的审核一般需要多久?
待处理信息:
用户历史提问:{{#context#}}
|
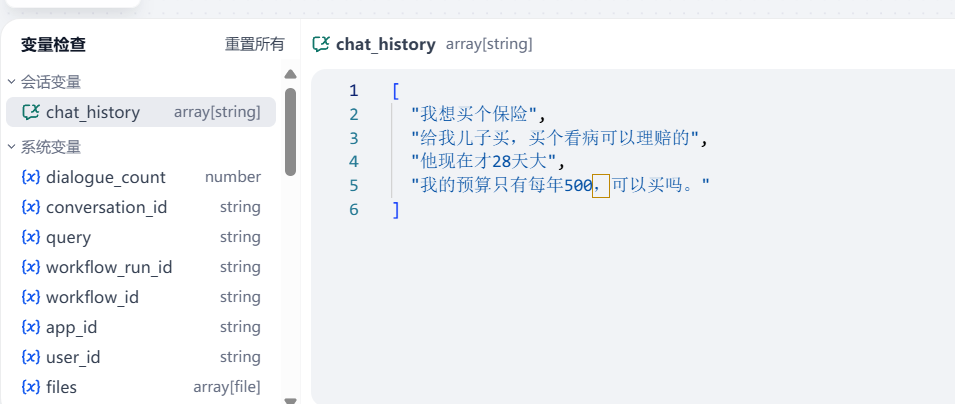
我给大家大概演示一下效果,这是我连续问了 4 个问题, chat_history 的记录:
这是 query 改写的内容:
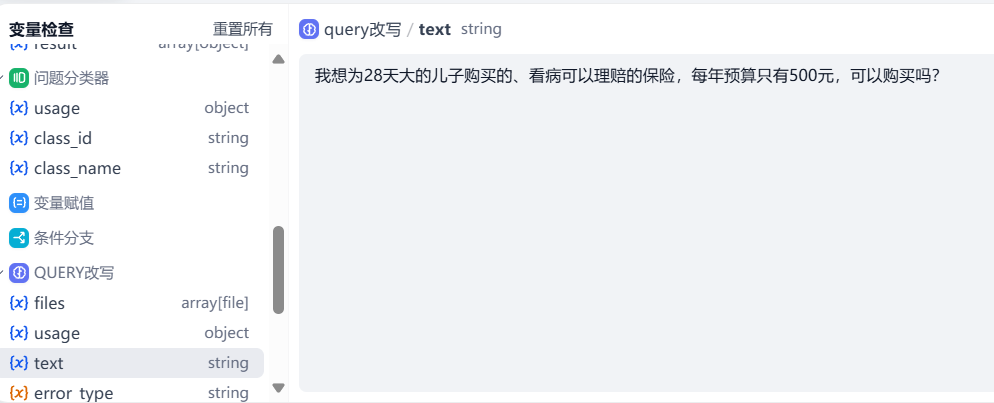
看起来效果还不错。
然后我们再验证下,用户问题的保存:
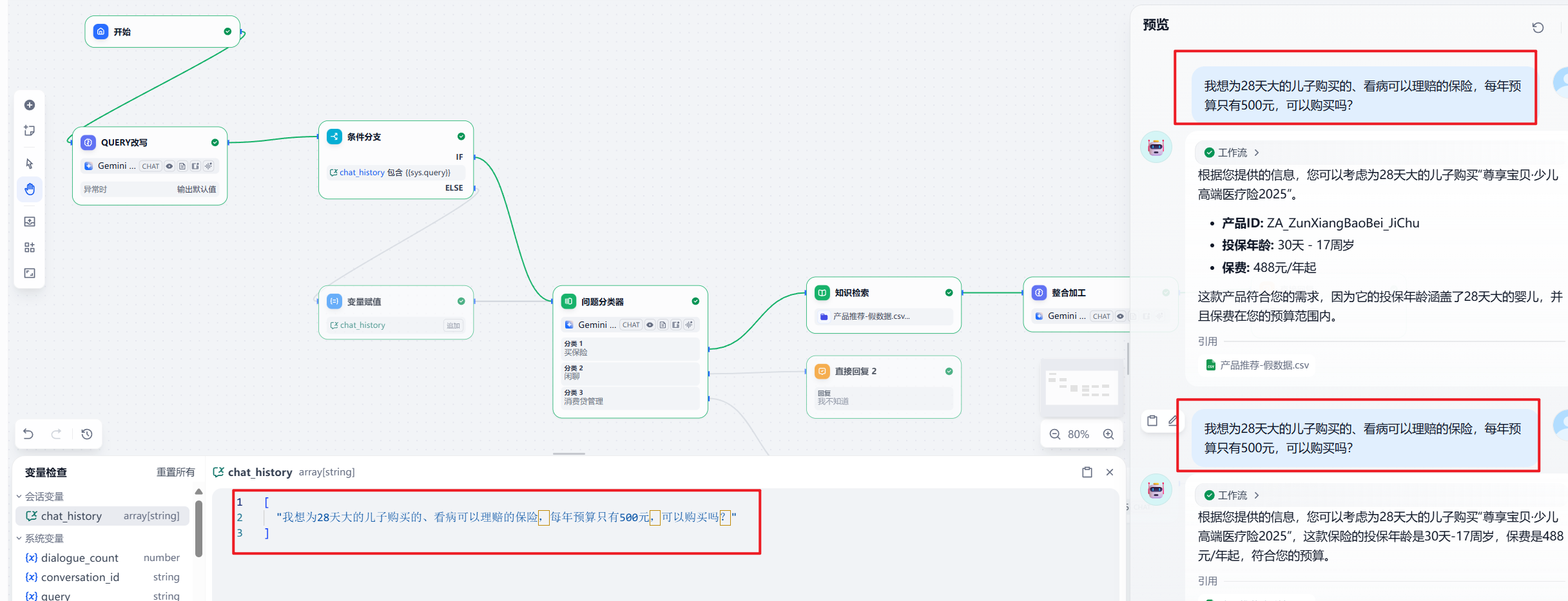
我连续问了两遍相同的问题,但是 chat_history 只保留了一遍,还可以哈。
其实沿着这个思路,继续往下,我们就可以做到在工作流中,实现 context 的保存。
保留完整的 context,模型获取到完整的信息,才能更好的为我们服务。
这块后面继续研究。