我如何将一个Dify周报助手,从Demo迭代到生产可用(附踩坑经验)
整理十几个人的周报,是不是特烦人? 我也烦,所以我用Dify搞了个自动化助手,从一个时不时抽风的玩具,迭代成了能在生产环境稳定跑的周报助理。
这篇文章主要就是记录下这个周报助理达到生产可用的过程和 几个问题的解决方法:
- 当模型输出不稳定时,别死磕Prompt,用“代码节点”这种确定性的方法才是王道。
- 不会写代码?没关系,现在AI就是你最好的程序员,我教你怎么让它给你打工。
- 工作流里那些意想不到的“小坑”(比如超时、渲染失败),怎么提前规避掉。
如果你也想把手里的 Agent 从 Demo 搞成真能用的东西,这篇文章的经验,你绝对能直接拿去用。下面,咱们就从头盘一盘这个“打怪升级”的过程。
1. 从0-1,先让Agent跑起来再说
第一版,搭个简版
大家可以看到第一个版本相对比较简单,就是一个判断节点+两个LLM节点。
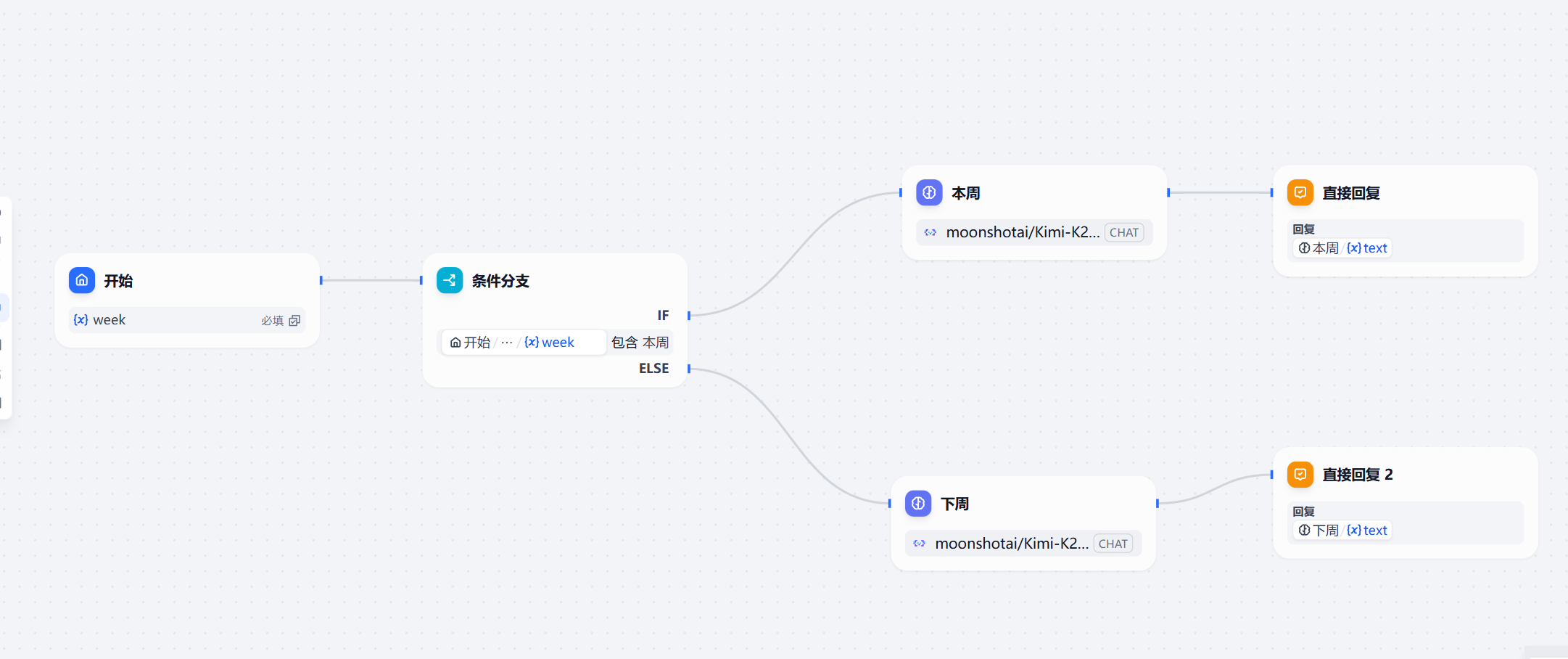
因为初始版本只是想快速验证是否可行。
当然,一定是可行的,因为我自己拿着历史大家提交的原始版本和整理后的版本,反复迭代了一版提示词,
这个提示词有两个,本周的提示词和下周的提示词,并且将提示词在最好的模型上验证过(记得脱敏的,大家可千万别随便拿自己的数据去外面瞎搞。),所以一定可行,哈哈。可行只不过被我提前验证过了,现在是想让大家用起来。
然而,放到dify总不能每次让大家记录下来提示词,每次都手输入。所以就高了一个这样的MVP版本。
然后将周报内容输入即可,但是周报内容又是非常多的,这样搞,大家非常容易遗漏内容。
所以验证结果就是,能跑,但是有点蠢。
优化下输入和输出
这就有了第二个版本:支持上传Excel文档和最终将输出结果转换为Excel并支持下载。
在搞第二版的时候,因为第一版,已经在内部跑过了,所以和大家规范了下周报的格式,无论本周和下周都进行了统一。
当然,肯定有不会严格执行的、或者不小心写错的,这很正常,所以提示词要多做一些错误冗余。
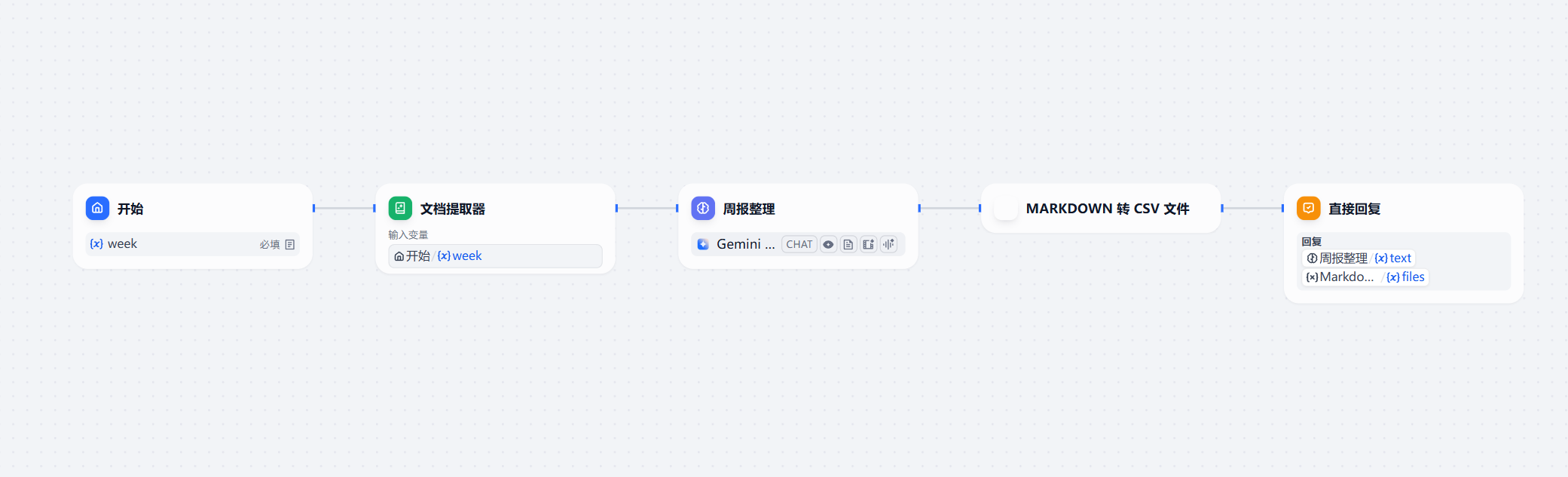
这个版本最大的进化是以下几点:
- 直接上传周报的文档。
- 支持输出位csv文件。
- 本周和下周内容的统一。
这里有几个小坑,给大家分享下:
- 大家使用这个markdown转换器转为csv的时候,要注意提示词设定的输出的markdown表格格式。绝对不要包含**```markdown** 这个代码块的标记。
- 在markdown的表格被dify的前端渲染的时候,
\n这种换行标记是无法正常渲染的,**最好是使用html的标记<br>**。
这两个东西都可以反复调试提示词来避免。但是很快我遇到了大Boss。
2. LLM不靠谱,应该怎么优化呢
为什么会有第三版呢?因为我在自己测试的过程中,会发现一种情况,就是受限于内部模型的实力(其实外部也不行,也会出现),总是会出现本周内容跑到下周,下周内容跑到本周。
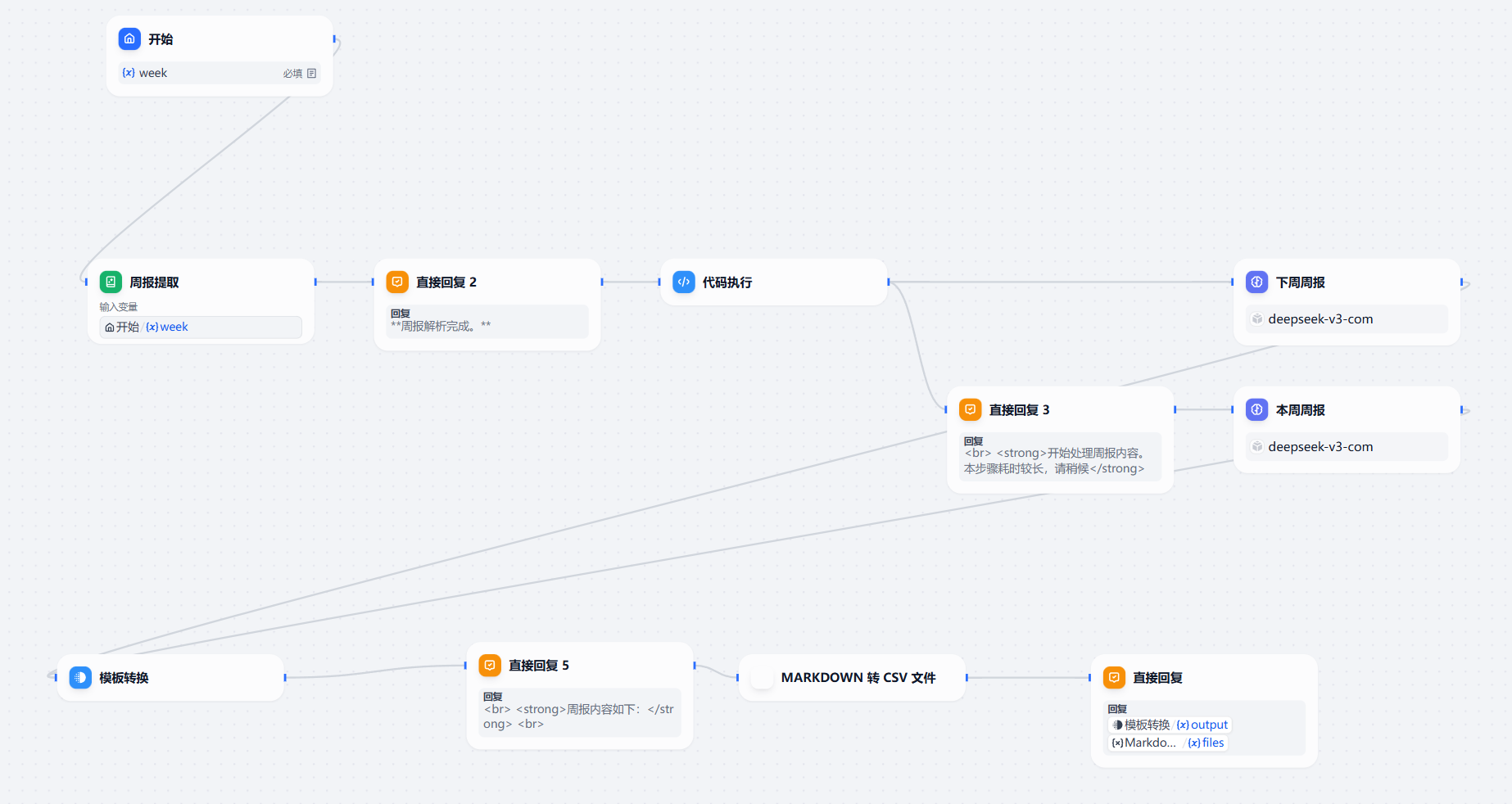
当时琢磨了三种方案:
- 选项A:死磕Prompt。 我寻思了一下,这玩意儿太玄学了,你调得再好,它总有0.1%的概率犯傻,治标不治本。
- 选项B:砸钱换更强的模型。 别想了,不可能的,没资源,还不能用外部模型。
- 选项C:用工程化的手段,在喂给模型前就把数据劈开。 这个靠谱!用确定的代码逻辑来处理,100%稳定,一劳永逸。
所以三个方案其实等于只有一个方案C。
这里我插一句:
如果大家是做商业化产品,类似这种很快会被模型能力本身干掉的场景(比如文本分割),就尽量别做。但我现在只是为了解决内部问题,怎么稳定、成本低怎么来。目的不同,手段就不一样。
所以第三版,我们最大的改变是以下升级:
- 新增了代码执行节点来处理原始数据。
- 新增了模板转换节点,来处理模型生成的数据。
- 在工作流中新增了直接回复节点。
让AI给我写Python代码
dify的代码节点,非常的有意思。可以使用python或者js来解决很多问题。
写到这里,大家可能会想,啊,我不会写代码啊,没关系,我也不会,不要着急,请大家继续跟着我走。
我这里主要用的python,dify的代码节点中的python内置了很多python包,所以可以直接引用导入包。
这里我使用zread.ai,了解了下:

所以我们在这里可以使用python代码,来解决很多问题。
回到最开头,我碰到的问题是,大模型执行的时候,会将上下两周的内容混合,所以我们很容易就可以想到,我把他分开不就行了。
看来看去,好像只能使用代码节点,使用python来解决。
我也不会写代码啊。那怎么办呢。
找AI啊!
- 首先,借鉴以前我们文章的思路,使用AI编程的时候,最好写一写开发规范。ok,我让
chatgpt帮我整理了一下:
# 1. 函数签名要求 |
也可以用这个简单版本:
1. **入口函数必须为 `main()`**,且只接受 `**kwargs` 作为参数,不允许使用 `args` 或其他形式。 |
我是把两个一起用了。
然后就简单了:
- 把规范扔给AI:“请遵循以下开发规范。”
- 把我们的期望输出告诉AI:“帮我开发一个dify中代码节点可使用的脚本,把它精确地分割成两个独立的字符串变量:this_week_content 和 next_week_content。”
- 把我们的输入告诉AI:“我的输入是:包含‘本周工作’和‘下周计划’的长文本。”
当然可能要将测试结果反复给AI几次,让它帮忙修改代码。
实测,国内的kimi的k2我试着也可以,其他没有太尝试,大家可以再Trae CN(国内版本)来写,成功率会比较高。
具体的代码我就不写了,不具备通用性。
最后这个节点的配置大概是这样:
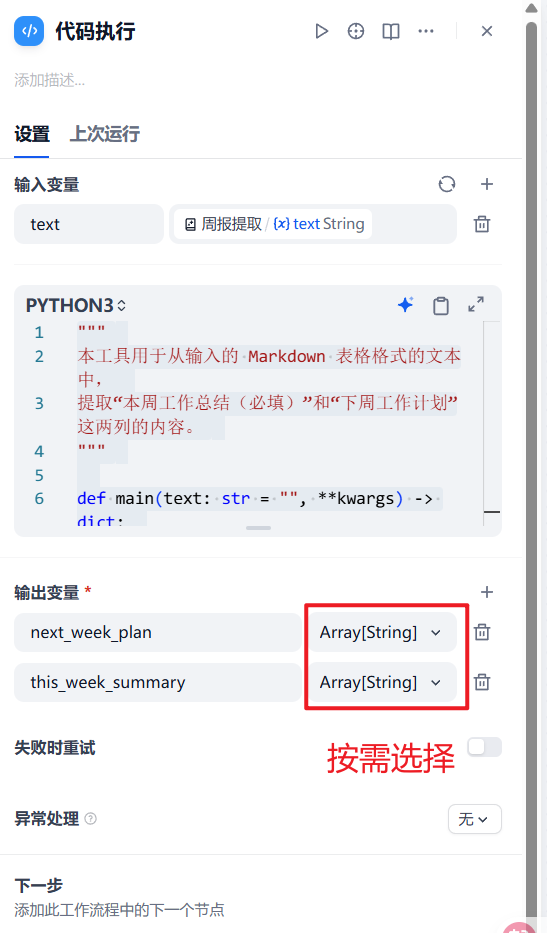
让AI给我些Jinja2代码
搞定了数据分割,下一步就是把两个LLM分别处理完的结果,合并成一个漂亮的Markdown表格。这里要用到模板转换节点。
这个节点的配置非常简单,这个要用的jinja2语法。你问我这是啥?我也不知道,但是AI知道啊。
我简单说下我的理解,这就是个模板设计器,我们可以预置模板,模板里面可以填写变量。
当然,我们不会写啊。
老办法,把输入和期望输出告诉AI:
- 输入:我有两个变量,text1(本周总结)和 text2(下周计划),里面的换行是
\n。 - 输出:我想要一个两列的Markdown表格,并且换行要变成
<br>。 - 要求:请用Jinja2语法实现。
ok,这就是jinja代码了,一次性成功:
| 本周工作总结 | 下周工作计划 | |
text1和text2就是我输入的参数了。
你看,我们根本不需要懂这些语法,只要能把问题描述清楚,AI就是我们最好的程序员。
直接回复
为什么加直接回复呢,因为我发现,模型的输出速度实在是太慢了,即便是我用的非推理模型。
为了避免我服务的用户们不知道进行到哪里了,所以我加了几个输出,告诉大家,我正在干什么,请稍候哈。
3. 优化细节体验
其实第4版,在第三版基础上,大的升级几乎没有,主要原因是在第三版的基础上,发现几个小问题。
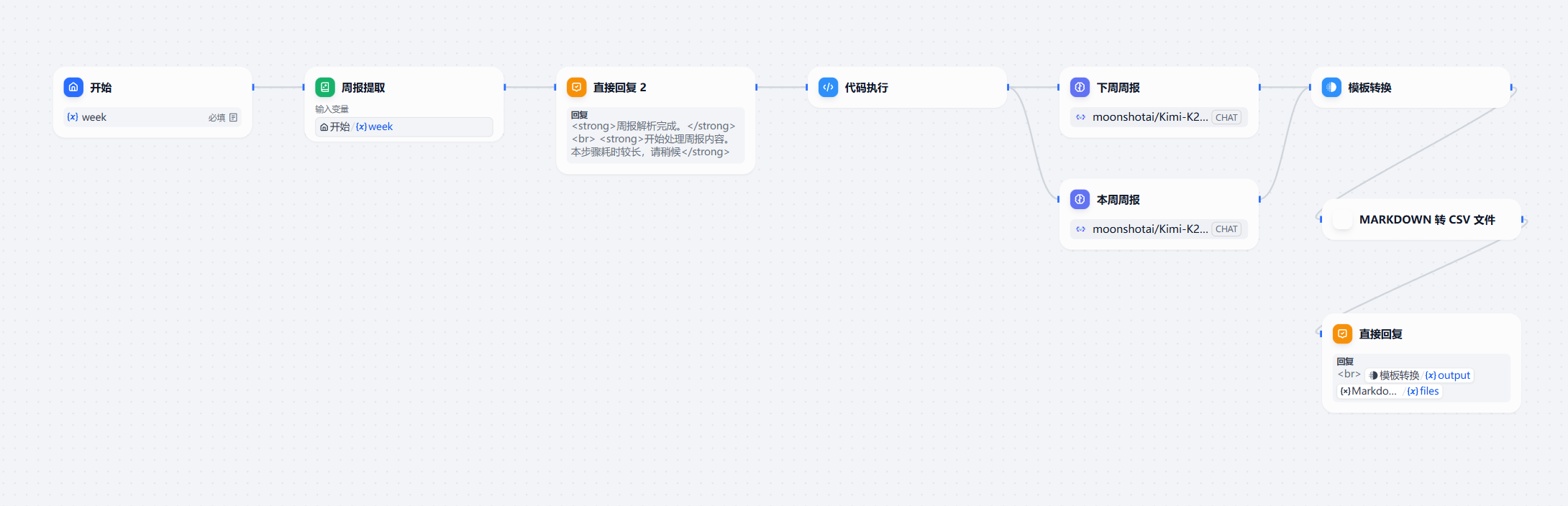
- 问题1:在直接回复节点,markdown语法不能和html语法混用。会出现不能正确渲染的问题。所以在一个节点,最好采用一种语法。
- 问题2:直接回复节点最好不要在大模型前面出现,因为会耽误模型的运行时间,导致模板转换节点(需要2个参数输入)超时,最终导致得不到正确的输出。
4. 最后
初步搞定这个周报助手后,有一些思考,分享给大家:
- 用确定性对抗不确定性。 能用代码(比如文本分割、格式转换)100%搞定的事,就别扔给LLM去玩“概率游戏”。这是让你的Agent从“玩具”变成“工具”的关键一步。
- 把AI当成你的“外包程序员”。 别被“我不会写代码”劝退。现在最牛的技能,不是你会不会写代码,而是你能不能把你的需求,清晰地扔给AI,让它给你干活。
- 成本意识是基本功。 代码节点运行几乎零成本,而LLM节点可都是按Token烧钱的。一个好的AI产品经理,得时刻把账算明白。
当然,我这个第四版也不是最终版,比如两个大模型节点是不是可以换成一个,用循环来完成呢?
大家还有哪些邪修法门,评论区聊聊?
谢谢你看完我的文章。