进阶教程:给AI装上"逻辑大脑",打造金融级稳定的多轮对话Agent(Dify实战)
之前,我们讨论过一次怎么样使用dify来构建多轮对话。
保姆级教程:手把手教你用Dify实现完美多轮对话(附Chatflow和提示词)
这个名字取得还可以,哈哈。但是实际生产使用会存在一些问题,评论区也有说到。
问题一:多轮对话时, 有些代词在回答的答案中, 只将的用户的问题当作上下文, 有时拼写不出完整的问题.
问题二:query改写节点不能开记忆,把之前对话合并成文本放进user prompt,再把温度降低,增加额外规则限制。会好一点。
问题三:用户输入和前文不相干,比如问完保险问其他话题(闲聊),这种情况如何分开做query改写防止污染?还想问下这样改写耗时会不会很久?小模型效果好吗?
这些老师提到的问题其实都是同一个,如何确保问题改写节点,准确理解用户的问题,不要改写错误。此外还有:
多轮对话时,如果A任务没有成,但是词槽或者说参数收集了一半,用户问多轮任务B,接这问C,这样大概率会造成信息丢失。
FAQ/转人工等相关场景没有处理。
如何实现长期记忆。
这些问题,我们依次来尝试解决一下,下面的整体思路,是结合了bert时代的状态机管理(或者说对话状态跟踪)和大模型的语义理解、分类、信息提取等相关能力。
为什么要用状态机呢?
我认为,对于私有化模型来说,一般都是开源的,不是最好的模型。二是,大模型是基于概率的,上下文、任务状态很容易丢失,一旦对话过程,即便是Gemini。另外一点就是,我在金融行业,金融行业对合规性更加重视,需要可靠可控的输出结果。
使用状态机,是为了显示的标识当前任务的状态。
我认为在提示词里面标识一下,肯定要比单纯使用LLM本身的记忆,能更好的提升任务完成率。
比如提示:#当前状态是查询天气信息收集中。
我们现在进入正题,一步步开始解决。当然,仍然是用dify演示,但是其他的工作流工具也是类似的。
1. 优化问题改写节点
解决丢失系统回答,无法准确理解用户问题的情况。我的方法是,使用了代码节点,在所有的直接回复节点后面新增代码节点,然后赋值给会话变量。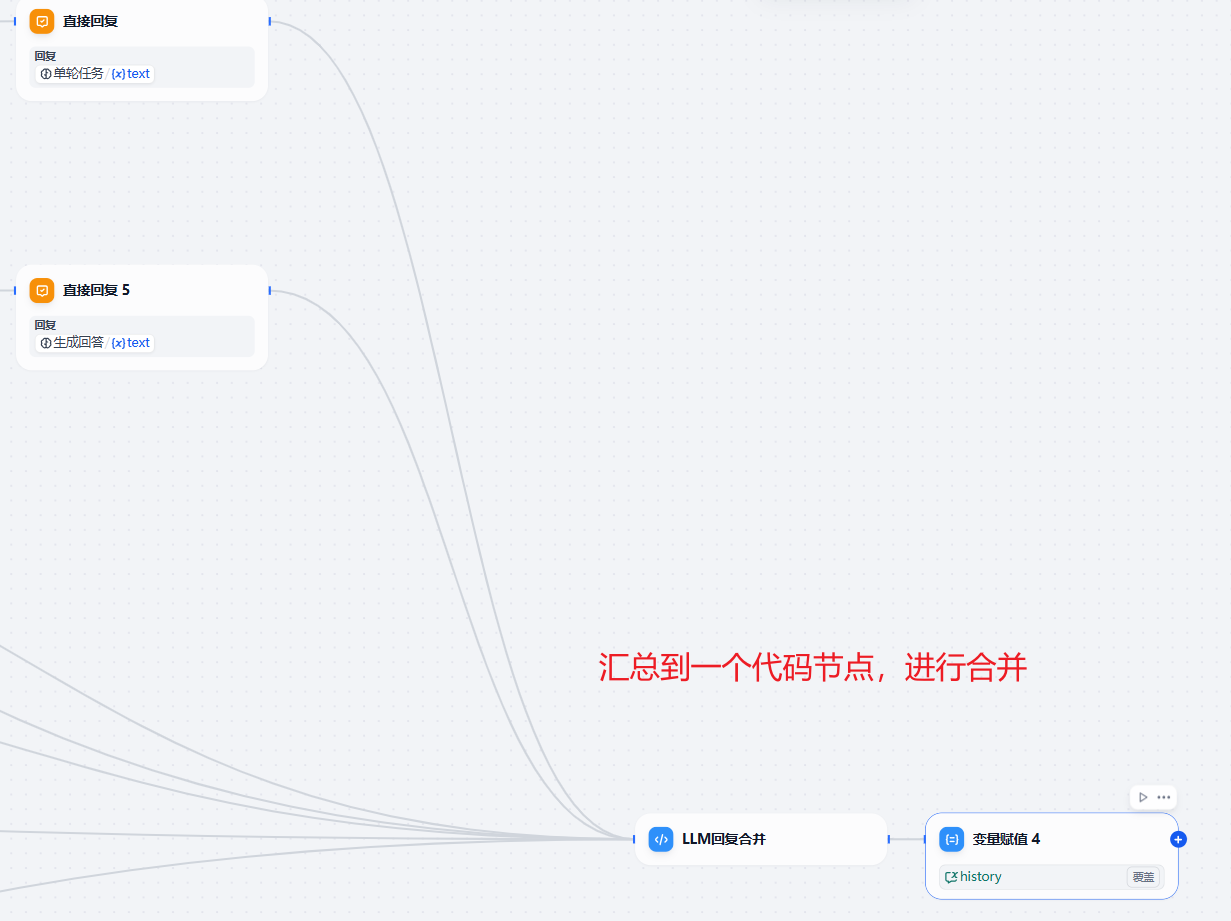
最终的效果是这个样子的:
user: 天气咋样啊 |
上面的内容是会话变量history,我们创建的时候,记得创建为str类型。变量赋值时,选择覆盖。
这是代码节点的代码:
def main(old_history: str, user_query: str, **kwargs) -> dict: |
关于对话内容这里,我们简单粗暴的采取了类似记忆节点的丢失策略,就是大于10的话,我们就会把原来的丢弃。主要是考虑到响应时间的问题。
在正式生产环境中,这个位置,我认为,应该搞一个记忆节点,采取压缩策略,而不是直接丢弃。将超过多少轮的对话,走一下记忆分支,进行压缩。
这样,我们就可以将所有的内容,都输入到query改写节点。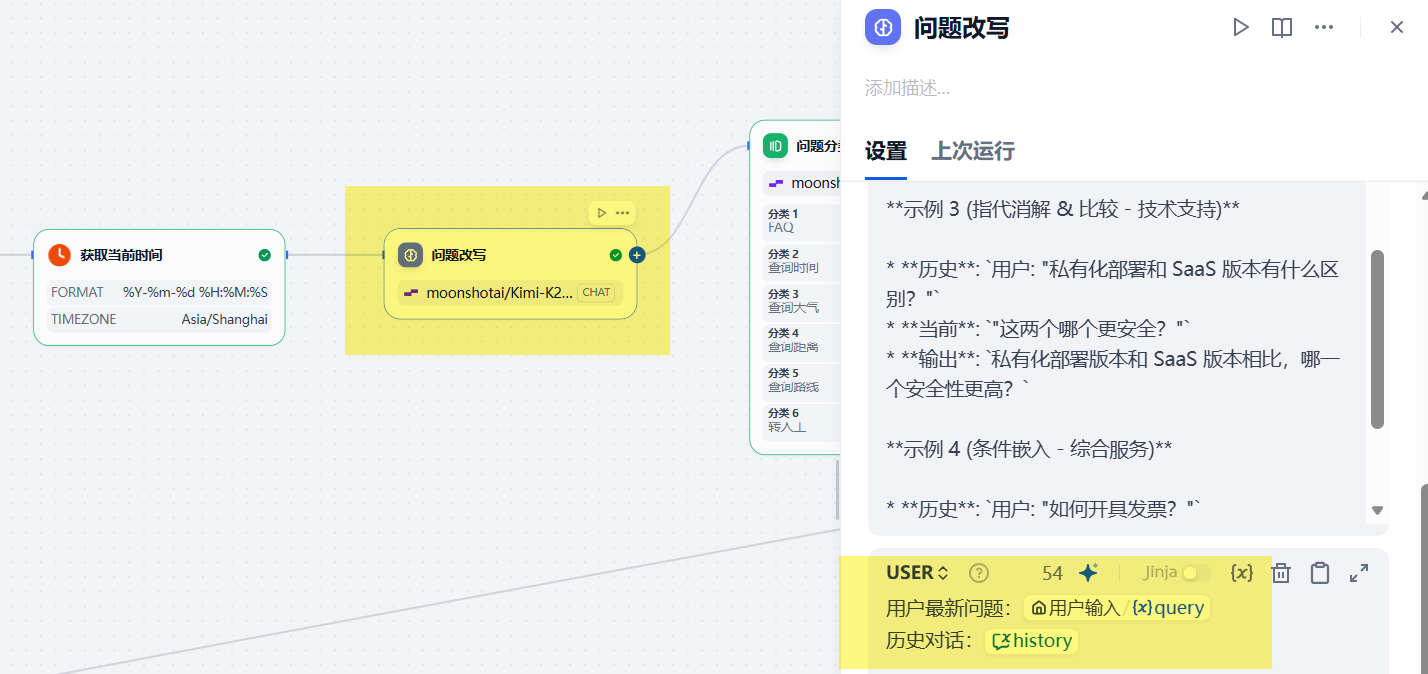
这样,我们可以解决第一个问题,如何确保准确理解用户问题,确保改写正确。
2. 引入状态机,实现多轮对话
首先,大家不要被状态机这三个字吓到哈。
其实可以理解为我们有一个笔记本,上面记着我们需要做的事情(to do list),和做成这件事情所必须的东西(参数)。
按照上一代智能客服的分类来说,通常,我们将用户的问题分为以下几类:
FAQ、转人工、单轮任务、多轮任务、闲聊等。
FAQ用大模型来做,就是结合RAG知识库进行回答。
转人工就是智能客服解决不了,或者必须由人工客服完成的需求。
单轮任务,是类似用完即走的。比如银行领域,只要客户登录了,客户问一句,我的账户余额是多少。系统其实只需要校验登录态即可。校验完成,不需要其他任何信息就可以完成任务,直接回复答案。
难度比较大的是多轮任务,因为多轮任务往往需要和客户确认很多信息。以查询天气为例,我们需要知道用户要查询哪里的天气以及时间。
在智能客服领域,大部分的客户来这里咨询基本都是1-3个主题,用完即走。但是也有部分客户,会咨询很多问题。所以就有可能出现下面的情况:
| 轮次 | 用户输入 | LLM(语义提取与意图映射) | 状态机系统(数据结构维护) |
|---|---|---|---|
| 01 | “下周三我想从成都开车去拉萨。” | 映射任务: 路径规划 提取槽位: from: 成都, to: 拉萨, date: 2026-01-28 |
初始化: 创建 task_id: 451425c2,压入 task_stack。 锁逻辑: global_intent_lock 设置为 LOCKED。 |
| 02 | “那边现在冷吗?推荐个保险吧。” | 映射任务: 投保咨询 提取槽位: type: 旅游险 识别背景: 用户提及“冷”,关联高原环境。 |
任务压栈: task_stack 顶部新增 投保 任务。当前 current_task 切换为保险。 状态记录: stage 设为 COLLECTING,此时 slots 中 high_risk_confirm(高风险确认)为 null。 |
| 03 | “会有高原反应吗?保险管这个吗?” | 解析意图: 知识问答(FAQ) 提取槽位: 无新槽位。 | 中断处理: 系统识别到这是临时提问。状态机挂起当前投保任务,允许 LLM 回答 FAQ,但不改变 current_task 的任务 ID。 |
| 04 | “行,那买一份吧。” | 解析意图: 确认投保。 LLM 局限: LLM 可能会直接跳到支付。 | 逻辑拦截: 状态机检查 current_task_slots。发现“高风险运动确认”仍为 null。 强制执行: 状态机拒绝进入 EXECUTING 阶段,强制将 stage 保持在 COLLECTING,并指令回复“请确认是否包含攀登等高风险运动”。 |
| 05 | “不去了,改去三亚,那边暖和。” | 解析意图: 全局意图变更。 提取槽位: to: 三亚 |
级联更新: 触发 __updated_variables。状态机清空栈内与“高原”相关的保险子任务。 恢复主任务: 重新定位到 路径规划,将 to 从拉萨改为三亚。 |
所以就想我开头举的例子,用户的槽位信息一直在变动,所以全靠大模型来干,相对于写到代码或者用参数值来保存,在提示词中引用最新的槽位和任务状态来说,任务完成率肯定相对来说会有很大的提升。
因此我们引入状态机: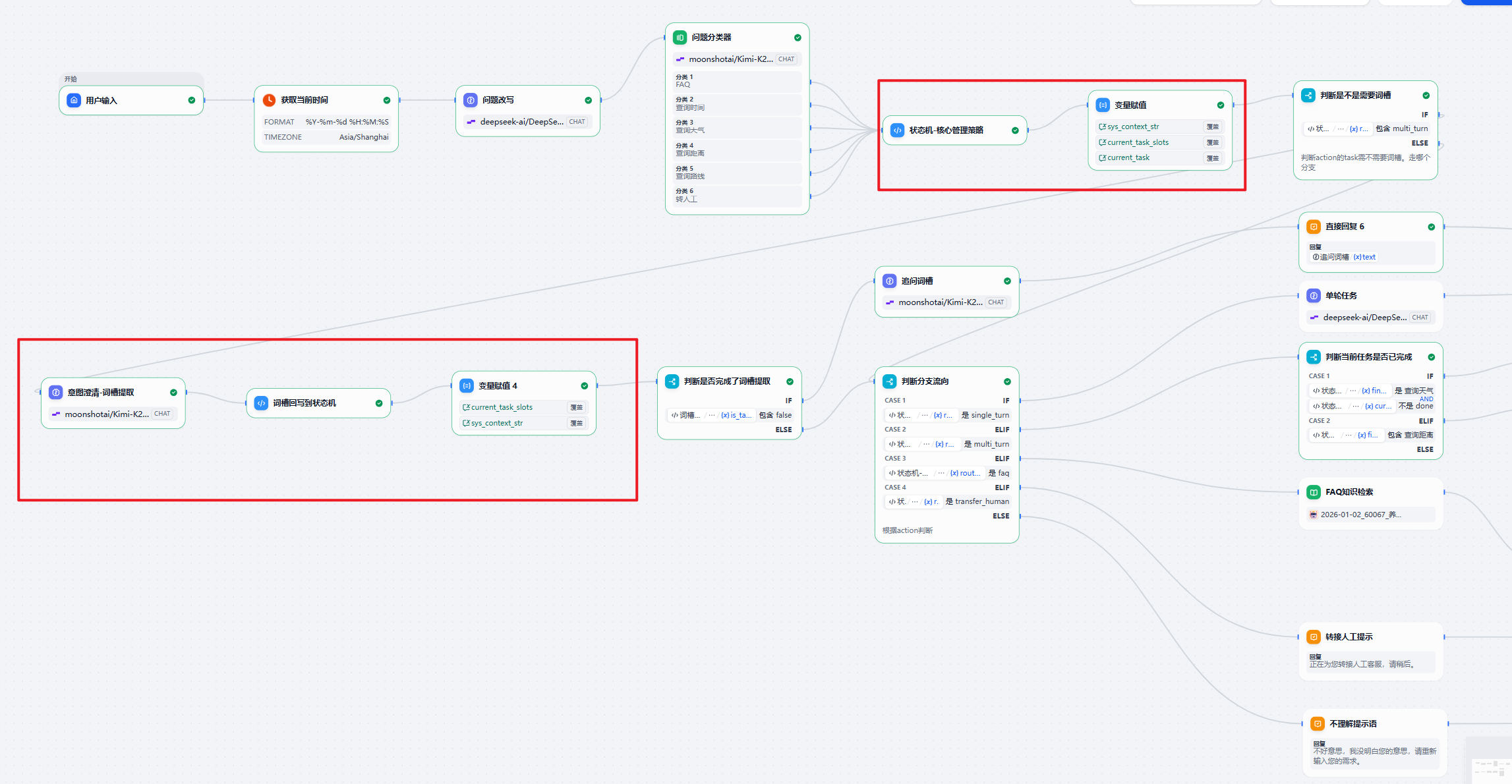
在这里,还是主要使用会话变量来进行参数及参数值的存储,使用代码节点来进行状态机的维护,使用变量赋值节点来进行会话变量的更新。
注意,我所有的变量在这里使用的都是str类型(字符串类型),本来想使用json,但是json有两个地方在dify里面不太好。一是json的属性不支持嵌套;二是json不支持直接在llm的提示词中引用。所以我统一使用了str。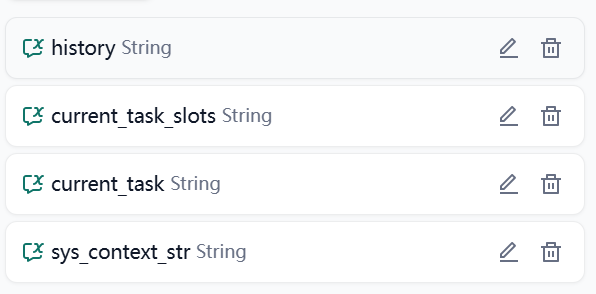
current_task_slots是当前任务的词槽信息或者说,我收集的需要信息,才能去调用工具来进行查询。current_task是当前的任务。sys_context_str里面是全量的信息,包含了
| 参数名称 | 角色 | 生活场景类比(理发店) | 专业作用与案例 |
|---|---|---|---|
global_intent_lock |
状态锁 / 忙碌指示灯 | 理发师工位上的“正在服务/空闲”指示牌 | 作用: 这是一个全局标记,用来告诉系统当前是否“被占用”。 防止在处理复杂任务时,被用户的随意插话打断核心流程。 案例: 值是 LOCKED(红灯),表示Tony老师正在剪发,暂时不接新客;值是 UNLOCKED(绿灯),表示随时可以接单。 |
current_task_id |
当前任务ID / 流水号 | 理发师手里拿着的那张“排队号小票” | 作用: 唯一标识当前正在处理的那一个任务,用于系统追踪和日志记录。 不管你在任务栈里压了多少事,系统只认这一串ID作为当前焦点。 案例: 比如 a1b2c3d4。如果系统报错,工程师可以通过这个ID在后台查到这笔“订单”的所有操作记录。 |
task_stack |
记忆栈 / 待办事项清单 | 前台板夹上夹着的一叠“服务单” | 作用: 这是多轮对话的灵魂。它是一个列表(List),按顺序记录了用户未完成的所有需求。采用“后进先出”原则,最后进来的需求最先处理。 案例: 1. 底层单子:查天气(暂挂起) 2. 顶层单子:查路线(正在做) 当查路线做完后,这张单子被撕掉,理发师就会看到下面那张“查天气”的单子,继续服务。 |
slots(位于 task_stack 内部) |
槽位信息 / 需求填空表 | 服务单上具体的勾选栏: “洗剪吹?染发?什么颜色?” |
作用: 具体的业务数据容器。机器人多轮追问的过程,本质上就是为了把这些空填满。 案例: 在“查天气”的任务里, slots 就是一张表:{ city: "北京", date: null }。因为 date 是空,机器人下一句就会问:“请问您要查哪一天的?” |
stage(位于 task_stack 内部) |
任务阶段 / 进度条 | 服务单上的印章状态: “待服务”、“进行中”、“已完结” |
作用: 控制任务的生命周期。只有标记为 DONE 的任务才会被系统清理掉。案例: COLLECTING:还在问用户要信息(剪发中)。DONE:信息收齐了,可以给结果了(剪完洗头送客)。 |
| 看起来还是很复杂哈,不知道有没有把大家给劝退了。我们一步步拆解一下。 | |||
 |
|||
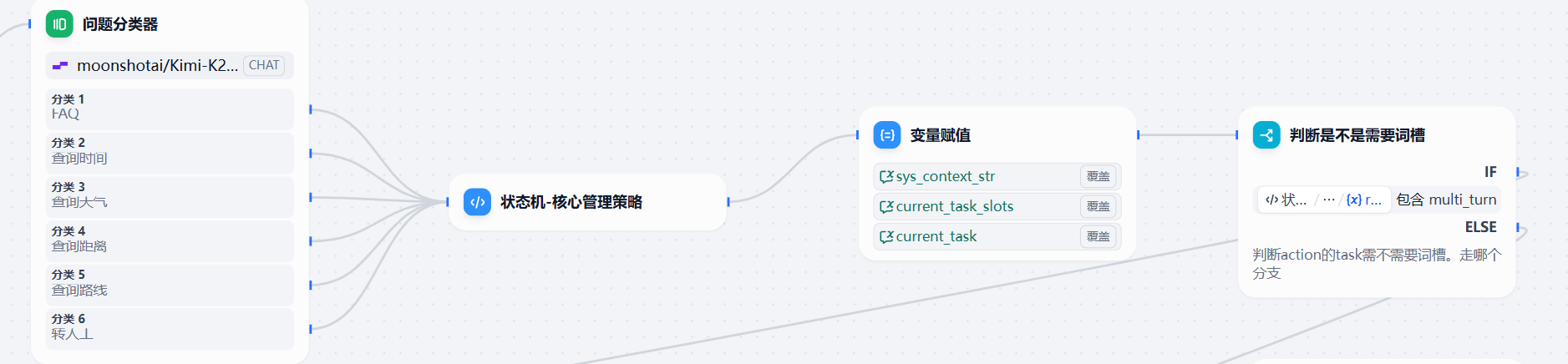
| 用户输入一个问题,我需要结合历史的对话信息对这个问题进行改写,这样呢,就变相的实现了llm的记忆。接下来,按照思路,我们肯定需要一个路由,来区分用户的问题到底是分给谁来处理,用户的问题是一个FAQ?一个单轮任务?还是要求转人工呢? |
所以我们就有了这样的工作流的开头: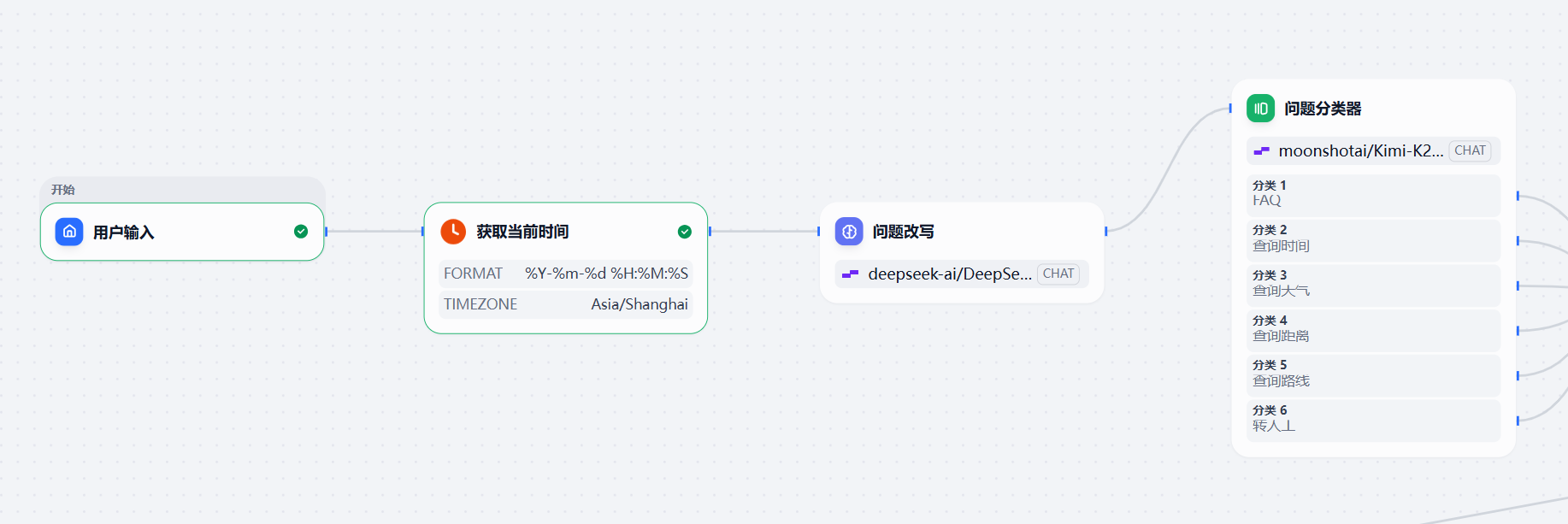
很好,现在我们知道用户这次想要做什么了,知道该给谁了,但是我们刚刚搞了一个笔记本,所以这里就要抓紧去维护一下笔记本的状态。但是大家也看到了刚刚的笔记本结构比较复杂,我们不能用简单的变量追加、覆盖处理。所以我们需要使用一个代码节点来做这个事情。代码节点,更新完笔记的内容,我们要写下来,所以需要变量赋值节点赋值给会话变量。
ok,至此,其实本次多轮对话的核心升级就完成了。下面都是为了逻辑更加流畅。
因为代码节点的代码比较长,所以这里我就不贴出来了。大家如有兴趣,请在评论区留言,我会提供代码或者DSL。
接下来,我们判断是不是多轮对话,如果不是,就直接进入最终的判断分支进行了路由,如果是,那就需要进行信息提取节点。
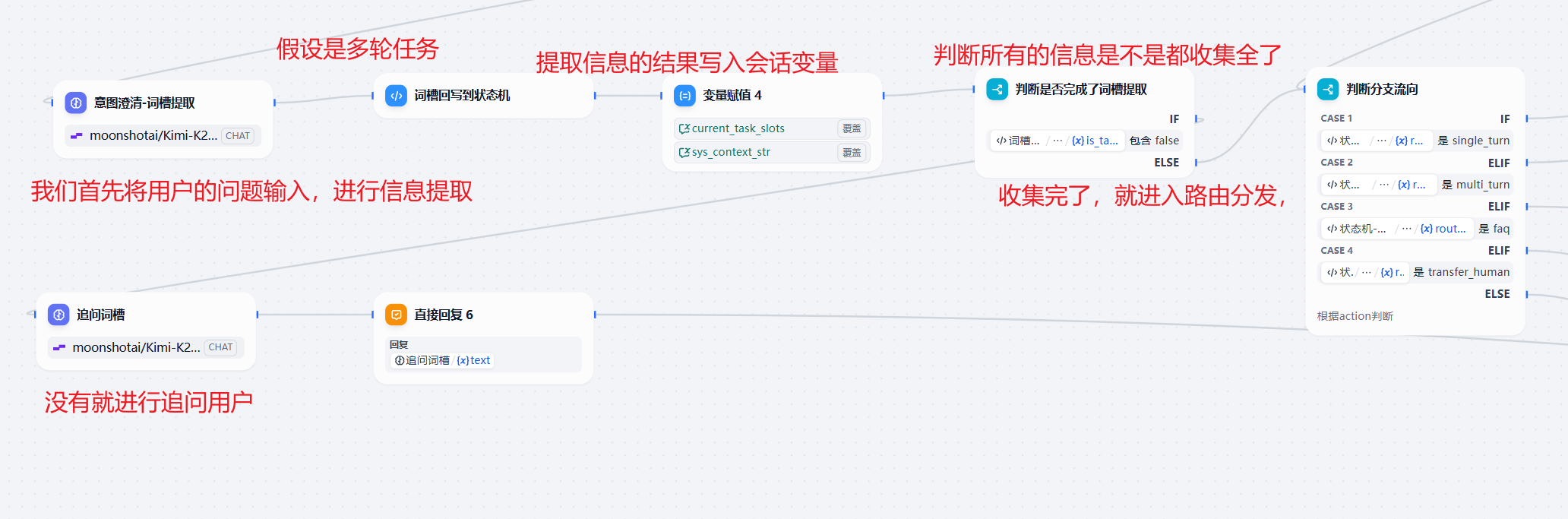
词槽不全就追问客户。
追问节点的提示词写的也比较简单,主要是想要验证想法,供大家参考:
# Role |
如果路由到FAQ,那我们就检索知识库;路由到单轮任务,我们就直接调用api回答用户。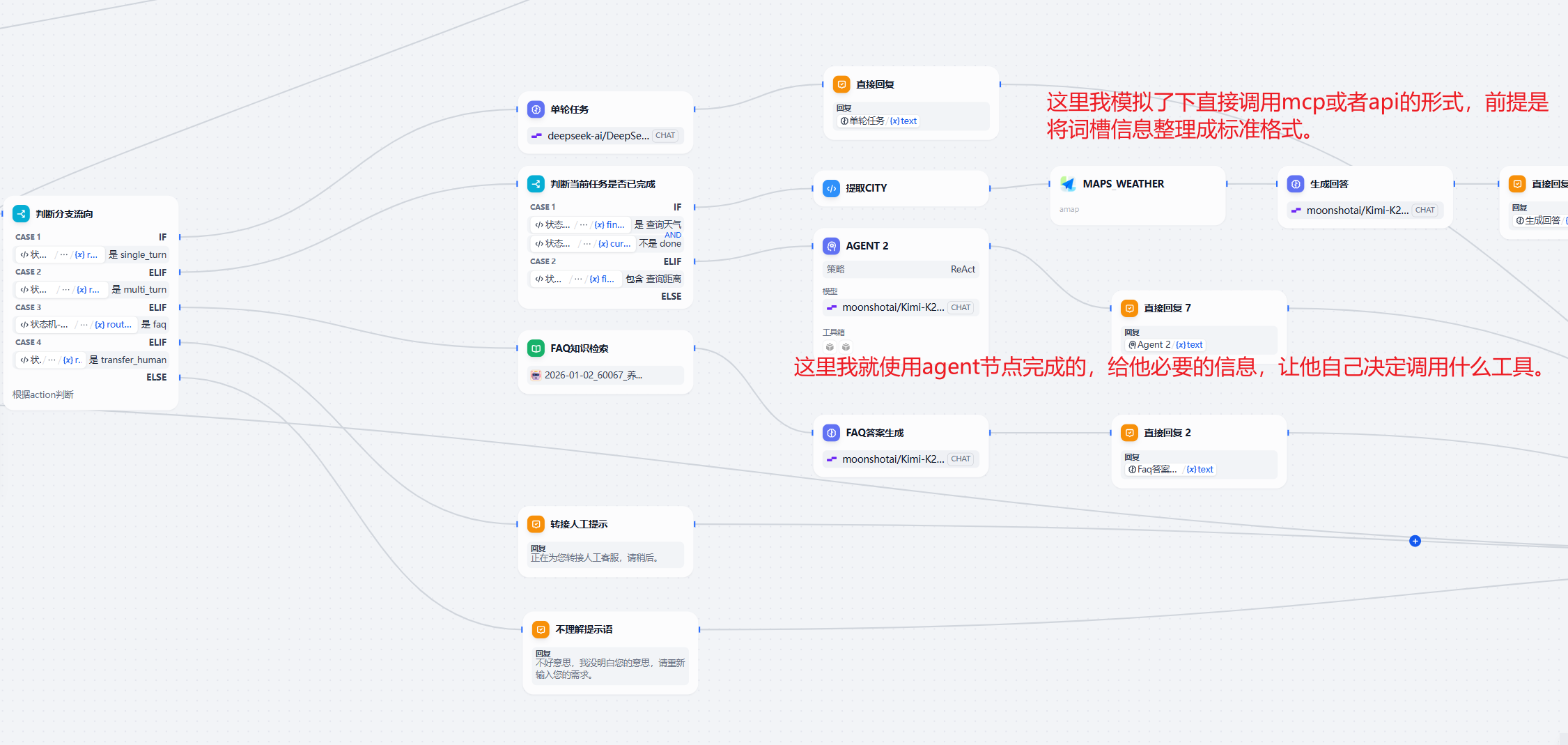
因为主要是为了模拟,所以agent节点的配置就特别简单,我没有设置很复杂的提示词。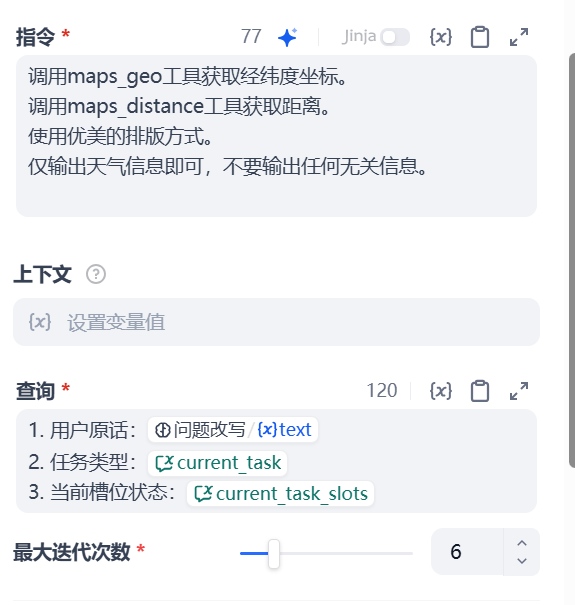
最终实现的效果: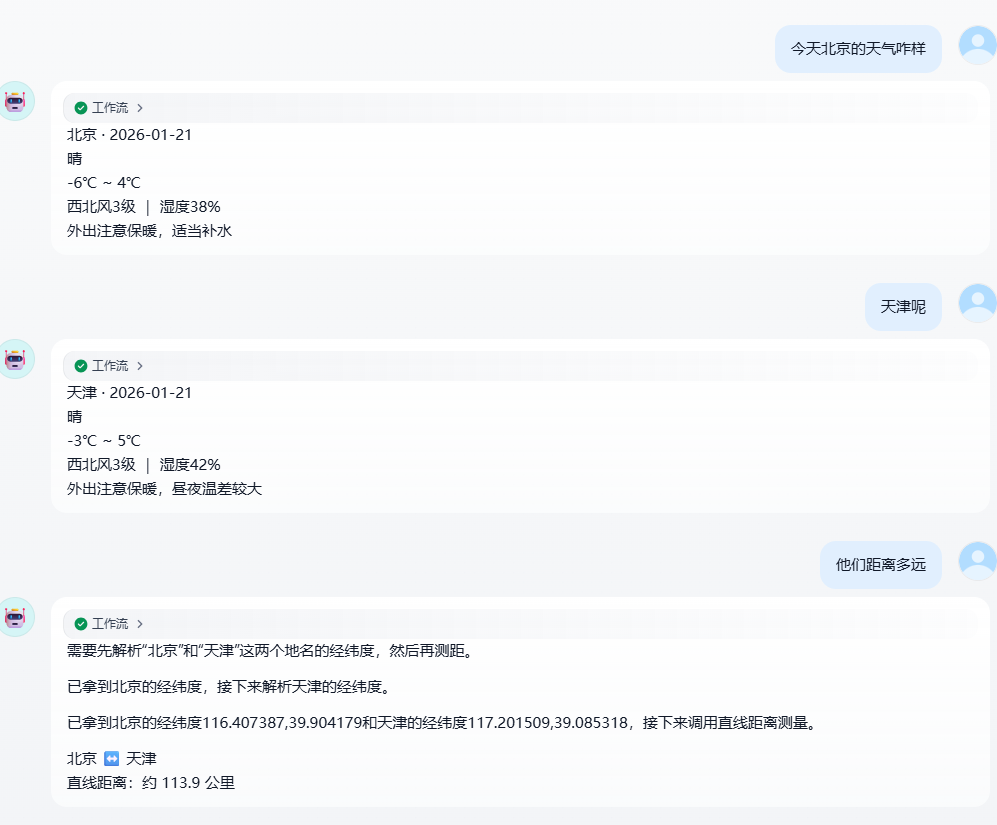
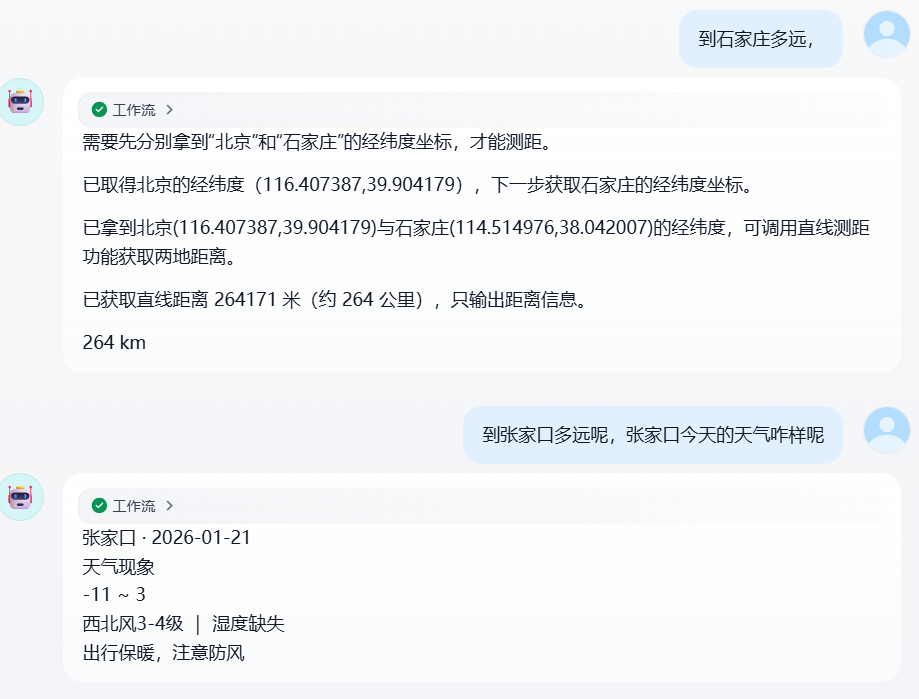
综合下来,我们的这个新的工作流的整体思路其实就是这个样子:
3. 小结
上面说的内容,可能没有第一次那么细,但是主体思路应该是讲明白了。
使用状态机,对会话状态进行管理。
使用了多个LLM节点,完成不同的任务,让他们专注于自己的任务,从而提高成功率。
这个版本仍然有很多的问题,但是主体结构已经完成了。还需要解决的问题如下:
- 响应时间比较长(LLM节点太多了)
- 每个节点没有做异常分支处理。例如什么时候转人工。
- 对最终的回答,没有进行内容审核,确保不生成不合规内容。
- 没有对多意图进行处理,比如一句话有两个多轮任务。
- 没有做详细的测试,设置任务成功率、拒识率、转人工率、一次性完成率、准确率等指标的相关统计及测试优化。