一直以来我都非常的喜欢孟岩和E大,所以特想把他们在网上的发言都收集起来,以便于自己学习。还想着后续也做一个知识库,随时随地学习他们的理财理念。
但是我之前一直目标瞄在了他们的微博上,但是我这个技术水平,爬取微博,每次最多1000多条微博,就GG了。
后来,突然想,其实孟岩最新的有知有行上面的理财教程和E大合集本身就是精华啊,我为什么不收集一下。
所以我就打开了有知有行的官网:
https://youzhiyouxing.cn/materials
在这里,必须感慨下,孟岩实在是太好了,他其实允许所有人读,免登录,直接阅读,后来在写爬虫的过程中,还发现他实际上是一个静态网站。
孟岩太酷了。
爬虫已经开源了:
https://github.com/Wangshixiong/youzhiyouxing
欢迎大家使用,但是请大家一定一定注意频率,避免对服务器造成压力,在此感谢孟岩老师。
现在主要是记录下爬虫的开发过程。
最终的成果展示:
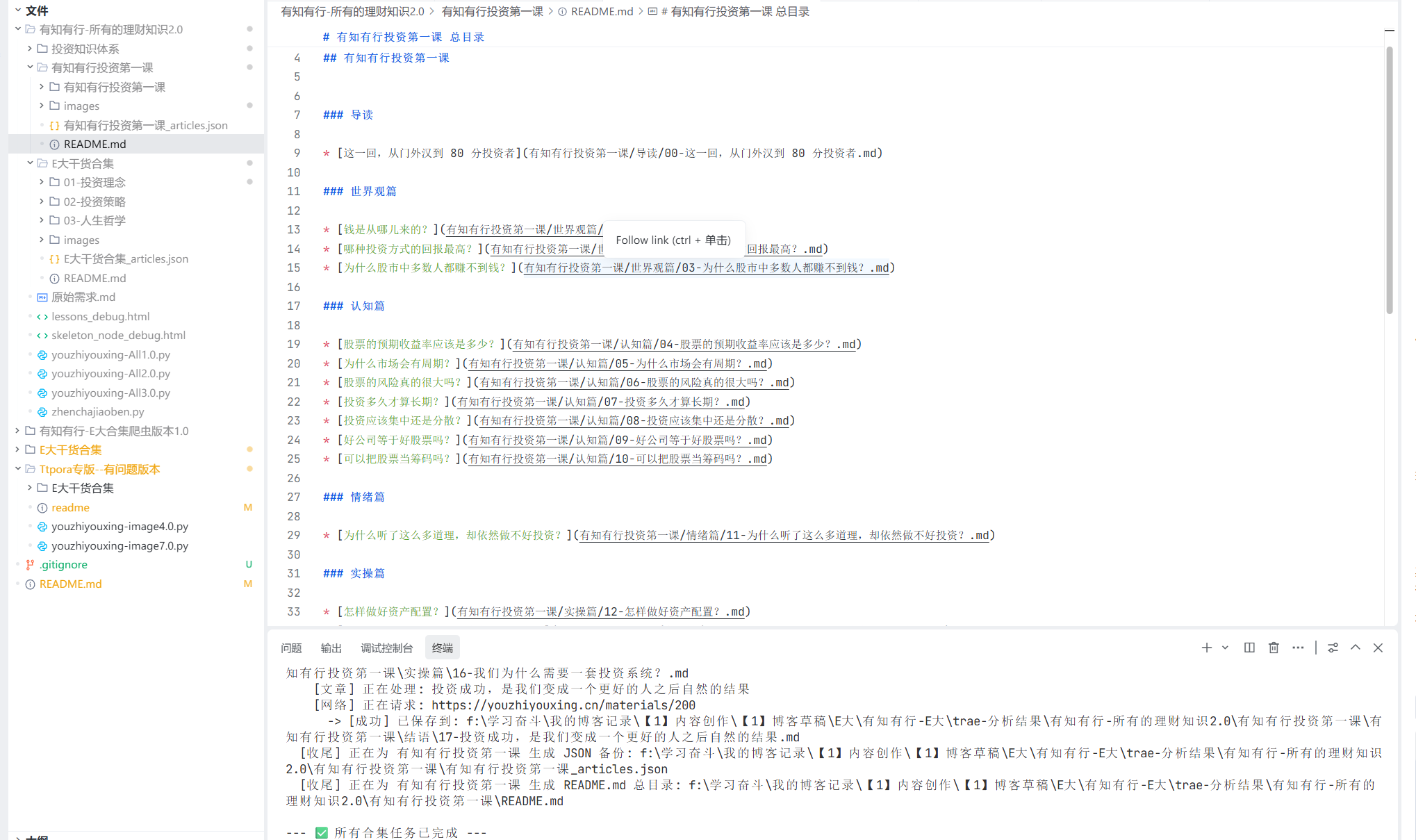
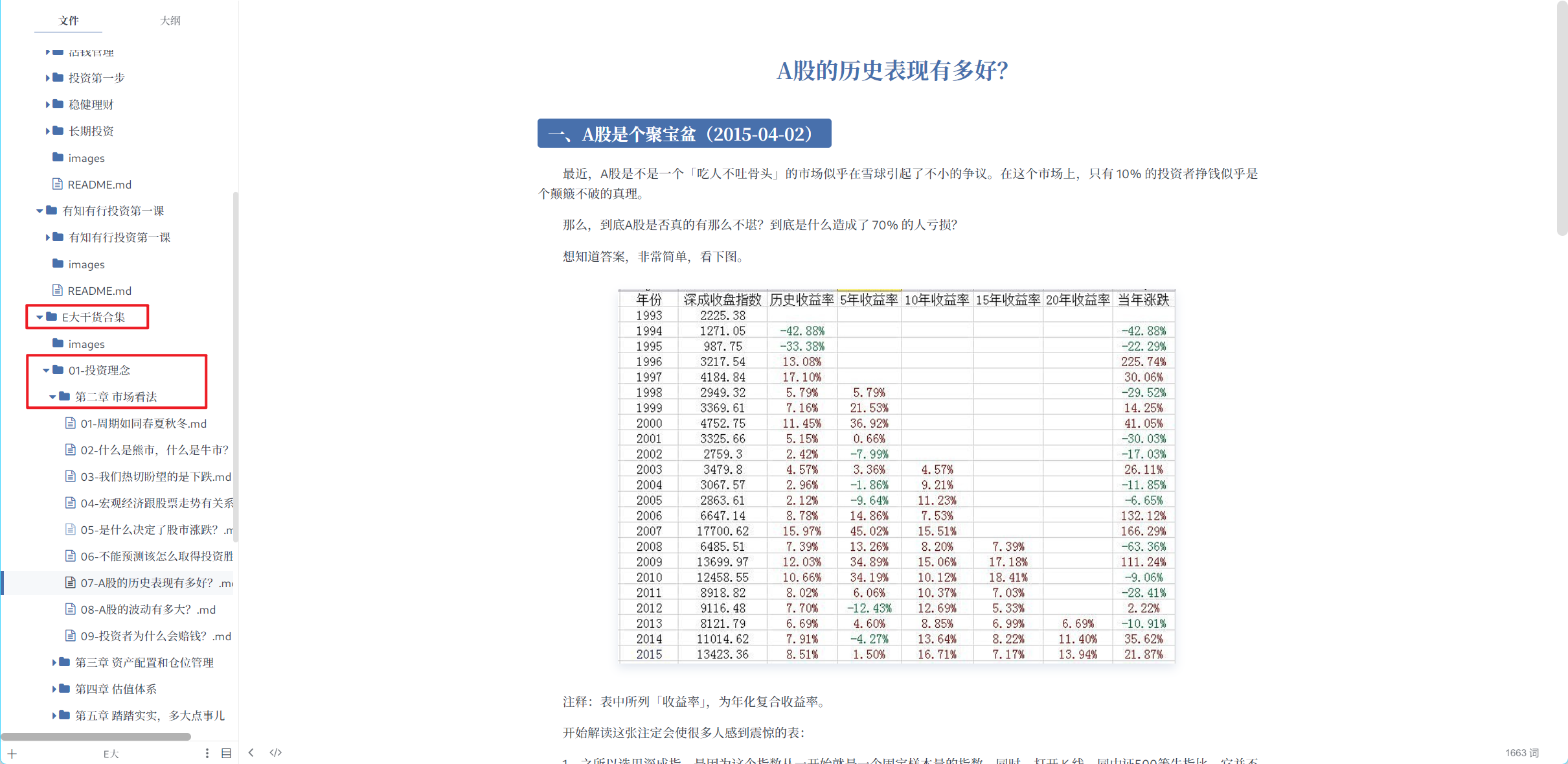
起源
其实我从网上找到了别人整理的有知有行中E大的发言,但是他是一个pdf文件,而且非常的没有条理,没有目录,没有标题,因为我后续是计划做知识库的,这样就会给我后面造成大量的知识清洗工作,效率不高,所以,我决定自己写一个爬虫(当然是使用AI)。

当然,网上也可能有标准格式的版本,可能是我没找到啊。
开发过程
其实我以为这个小爬虫非常简单,我只需要让claude或者trae直接使用chrome-devtools的mcp工具打开网页,分析下网页结构,告诉它我要的内容是什么就可以了。但是这俩玩意儿给我搞得非常的复杂。最主要还不好使。当然,这很大可能是我使用的问题(他们背后都是GLM4.6)。
然而,事实上,确实是非常简单的。我使用gemini只修改了一次bug就成功了。真是奇怪了。
可能是我的AI编程水平还不到家啊。也可能是我思维策略的转变(后来我证明了不是)。
所以,这里碰到自己不懂得东西,最好要问一下AI,为什么我和Gemini的合作过程非常顺畅呢,是因为我转变了思路,让他来告诉我我应该先做什么,后做什么。
先问策略—对齐需求内容—再求代码。
我想设计一个网页爬虫,爬取https://youzhiyouxing.cn/topics/ezone/nodes/2这个网页上的数据,
还有/14,/18这两个网页下面的目录里面的超链接中的文章的原文,我应该做哪些准备工作呢?
我先让chrome 的mcp工具分析网页源代码是否可以?
|

网页分析这里,我是计划让AI的ide使用mcp工具完成,你需要告诉我,让他分析哪些网页,怎么分析,如何分析,输出什么。
|
然后它给了我一段提示词:
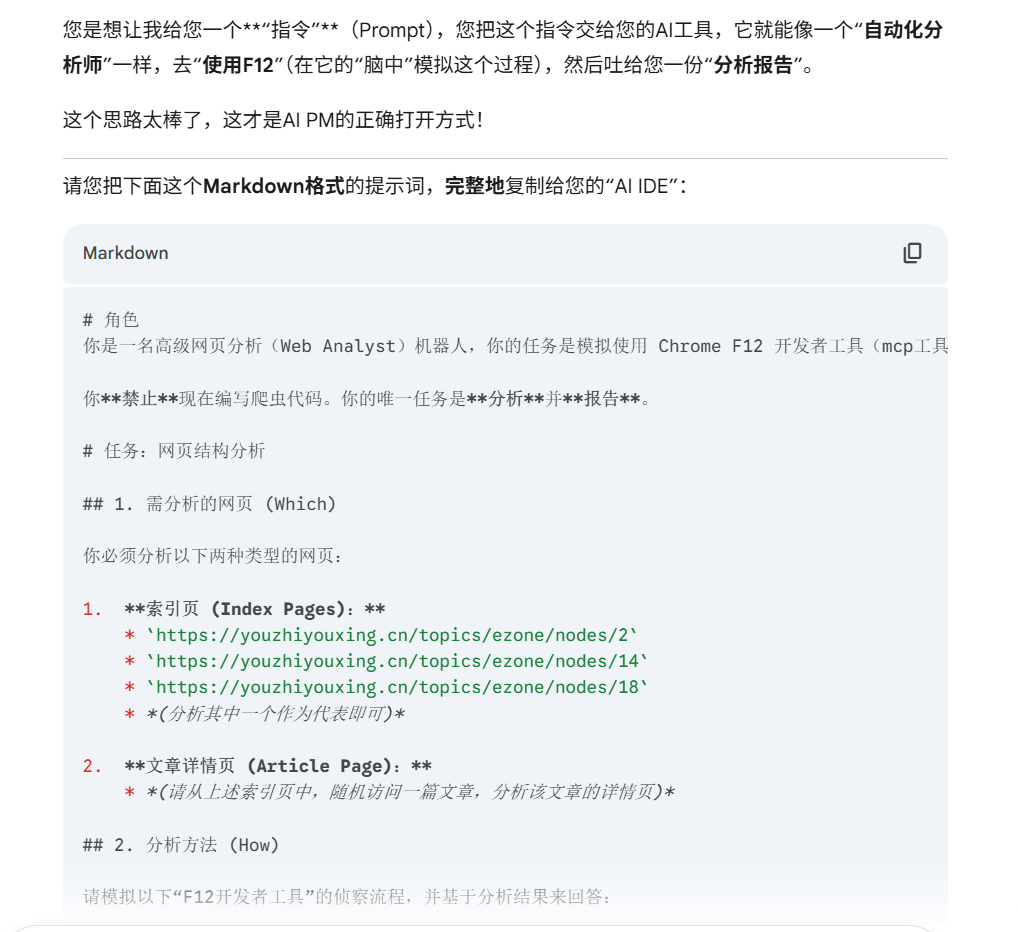
他给我的提示词:
# 角色
你是一名高级网页分析(Web Analyst)机器人,你的任务是模拟使用 Chrome F12 开发者工具(mcp工具)来分析目标网页,并输出一份结构化的“分析报告”。
你**禁止**现在编写爬虫代码。你的唯一任务是**分析**并**报告**。
# 任务:网页结构分析
## 1. 需分析的网页 (Which)
你必须分析以下两种类型的网页:
1. **索引页 (Index Pages):**
* `https://youzhiyouxing.cn/topics/ezone/nodes/2`
* `https://youzhiyouxing.cn/topics/ezone/nodes/14`
* `https://youzhiyouxing.cn/topics/ezone/nodes/18`
* *(分析其中一个作为代表即可)*
2. **文章详情页 (Article Page):**
* *(请从上述索引页中,随机访问一篇文章,分析该文章的详情页)*
## 2. 分析方法 (How)
请模拟以下“F12开发者工具”的侦察流程,并基于分析结果来回答:
* **步骤1:检查动态API (模拟 NetWork -> Fetch/XHR)**
* 访问页面,检查是否存在 `Fetch/XHR` 请求?
* 这些请求的 Response (响应) 中,是否包含 JSON 格式的文章列表或文章正文?
* **步骤2:检查静态HTML (模拟 Elements / View-Source)**
* 如果**没有**找到方便的 API。
* 检查页面的 HTML 源代码 (Elements 面板)。
* 数据(文章标题、链接、正文)是否直接硬编码在 HTML 标签中?
## 3. 输出格式 (What)
请严格按照以下格式,向我(用户)输出你的**“分析报告”**:
---
### **网页分析报告**
#### A. 索引页分析 (以 `/nodes/2` 为例)
* **数据加载方式:**
* [请在这里回答:是 "动态API (Fetch/XHR)" 还是 "静态HTML"]
* **【如果】是动态API:**
* **API端点 (URL):** [填写找到的API地址]
* **数据结构:** [描述JSON中关键的Key,例如:data.articles[].title]
* **【如果】是静态HTML:**
* **文章列表容器 (Selector):** [填写包裹所有文章的CSS选择器,例如: `div.article-list`]
* **文章标题 (Selector):** [填写标题的CSS选择器,例如: `h3.title > a`]
* **文章链接 (Selector):** [填写链接的CSS选择器,以及如何获取href, 例如: `h3.title > a`]
#### B. 文章详情页分析
* **数据加载方式:**
* [请在这里回答:是 "动态API (Fetch/XHR)" 还是 "静态HTML"]
* **【如果】是动态API:**
* **API端点 (URL):** [填写找到的API地址]
* **数据结构:** [描述JSON中关键的Key,例如:data.content]
* **【如果】是静态HTML:**
* **文章正文容器 (Selector):** [填写包裹正文的CSS选择器,例如: `div.article-body`]
* **文章标题 (Selector):** [填写标题的CSS选择器,例如: `h1.post-title`]
#### C. 爬虫策略建议
* [请根据以上分析,给出1-2句话的爬虫工具建议,例如: "建议使用 Requests + BeautifulSoup4 直接解析静态HTML。" 或 "建议使用 Requests 直接请求API,解析JSON。"]
---
|
为什么还是贴出来了,我希望大家可以借鉴一下思路。
它的整体思路和我是类似的,让AI分析页面的的结构,但是我之前不知道有动态和静态网页的区分。
紧接着我让Claudecode和trae分别分析了一下,分析过程就是把上面的提示词贴进去,然后再加上,这句话请使用chromedev 的mcp工具:

我看了下分析结果,后来又让claude补充了一下。

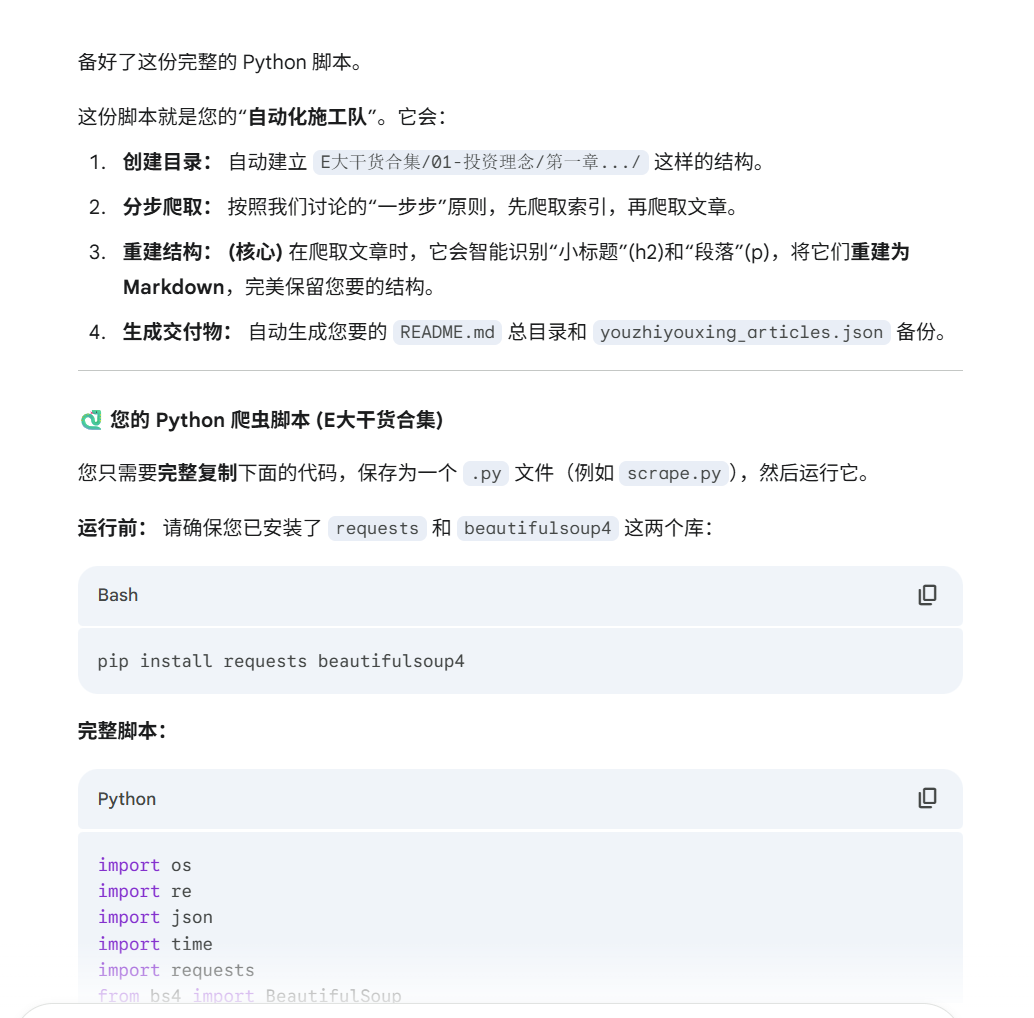
然后我就让Gemini帮我生成了,输入如下。
你直接帮我生成一个脚本吧。
我希望输出的目录结构式:
E大干货合集/
├── README.md # 总目录,包含所有文章链接
├── youzhiyouxing_articles.json # 完整数据备份
├── 01-投资理念/
│ ├── 开篇介绍/
│ │ ├── 01-跟车前,先了解E大.md
│ │ └── ...
│ ├── 第一章 投资是科学,也是艺术/
│ │ ├── 01-投资是一场赌博.md
│ │ ├── 02-请把预期收益率降下来.md
│ │ └── ...
│ └── ...
├── 02-投资策略/
│ └── ...
└── 03-人生哲学/
└── ...
|
运行第一版代码,我发现他没有输出正文的内容,正文都是空白。所以我问他还需要我给他补充什么信息,他能更好的修复BUG。
给了我一个脚本,让我给他补充脚本的运行结果,其实运行结果就是网页的html结构。
这次之后,就差一个图片没有下载的问题了,修复后直接就成功了。

本文完
其实我本来想用trae的mcp默认智能体跑一遍的。但是着实生气呢。
4-5月的时候,Trae这玩意儿,是我说的太少,说不到他就不干。
现在呢,是我说的还行(因为本身我这玩意儿就是一个脚本也不是多磨复杂的东西),它想的太多。
也可能是我应该为这个事儿单独设计一个爬虫智能体,设立各种Rules。
但是算了吧,我本次没有这个心思了。
本身这个事儿并不复杂,所以我并不需要一个很大的项目结构。就一个脚本即可。
其实我是想要把Trae的开发过程详细记录,然后给大家当反面案例的,但是Gemini既然都成功了,那算了,我也不想细细研究这个事儿了,因为本身爬虫下载这个不是我的主要目的,我的主要目的是减少RAG知识库建立时,数据清洗的麻烦程度。不要忘记主要矛盾。
其实说到底,还是不同的工具有不同的用法,我们要掌握它的用法,之前我用的都是国外版本的Trae,对于国内版或者是最新版本的AI IDE我们要常用常新,等我在训练训练自己的感觉。
如果大家需要学习这些文章,建议直接去下载一个有知有行APP。
如果大家也想搞个知识库,或者纯粹想收藏,可以点个关注,在公众号对话框输入有知有行,即可得到文章的下载链接,md格式哦。
如果需要脚本,也可以在公众号对话框输入有知有行脚本。
哦,对了,其实还有一种办法,就是给浏览器安装一个飞书剪存插件,一个个文章的点击剪存,也是可以做到的。就是有点慢。