GLM-4.6 + Claude Code实战:从入门配置,到一个差点翻车的项目
最近苦于在dify上去做一些MVP验证时,相对来说非常麻烦的问题,比如数据分析报告的生成。
因为在我的理解看来,对于数据表这种结构化数据,现阶段大模型其实并不擅长处理,他擅长处理的反而是非结构化的数据。所以现阶段来说,生成数据分析报告,肯定是需要提前加工好数据的,就是对原始数据做好数据透视,这样才能在一定程度上确保分析报告生成的准确性。
但是类似这汇总分析场景,使用dify的做MVP验证的话,就相对来说比较麻烦一些。因为这涉及到提前设计一些数据分析的脚本,来进行数据透视。相对来说,类似Claude code这种本地的AI Agent或者Trae这种AI IDE,做这件事情就非常擅长了。
不同的工具,有自己擅长的事情,而我们,要找到对自己最有利的工具,并且要用好它。
今天想给大家介绍下我最近经常用的claude code。当然今天主要就是简单地介绍下他的使用方式,深入使用,还是得在具体的业务场景。
1. Claude Code安装及配置
Claude Code 安装
这里我默认大家都已经安装了nodejs,如果没有安装的话,请大家去下面的网址下载安装下。
Node.js — Run JavaScript Everywhere:https://nodejs.org/zh-cn
claude code的安装非常简单,只需要运行一行命令即可,下面这个命令,可以实现全局安装Claude code:
npm install -g @anthropic-ai/claude-code |
安装完成以后,我们可以使用下面的命令验证是否安装成功了:
claude --version |
如果出现,2.0.11 (Claude Code),就代表,我们安装成功了。
由于在国内,使用Claude Code极其容易被封号,所以我们这次使用,我们国内最新的GLM 4.6版本的模型。因为众多大佬测试,说它和claude 4.0水平差不多。所以我们也来试试。
GLM 4.6配置
其实智普目前是只要注册就有2000w tokens。
轻度使用,够用几天了。可是被我一个小时就烧完了。所以我花了20块钱进行了订阅。
如果你是新用户,可以直接跳过下面的2和3,直接第一步登录注册以后,就会收到赠送的tokens。
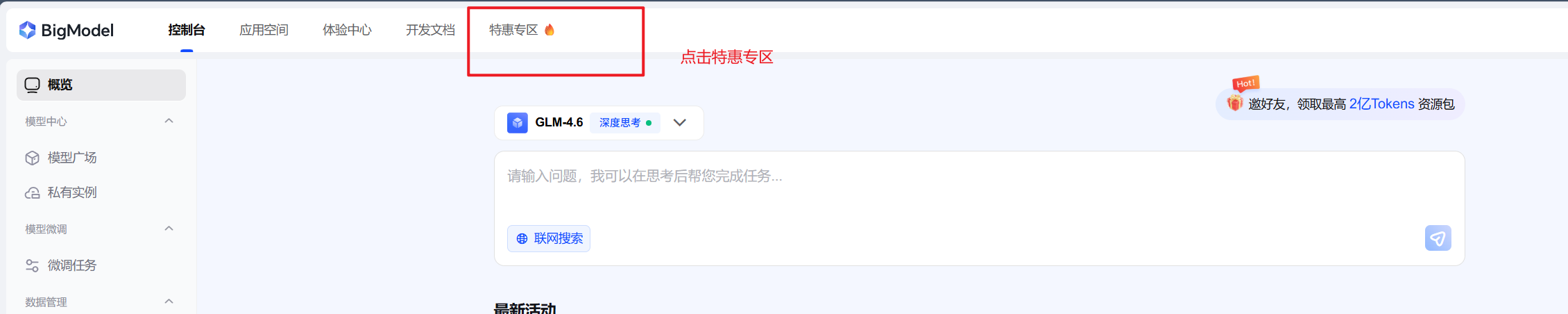
- 首先,我们打开智普开放平台:
点击特惠专区:
选择特惠套餐,在选择连续包月,一杯奶茶钱,就可以使用一个月。
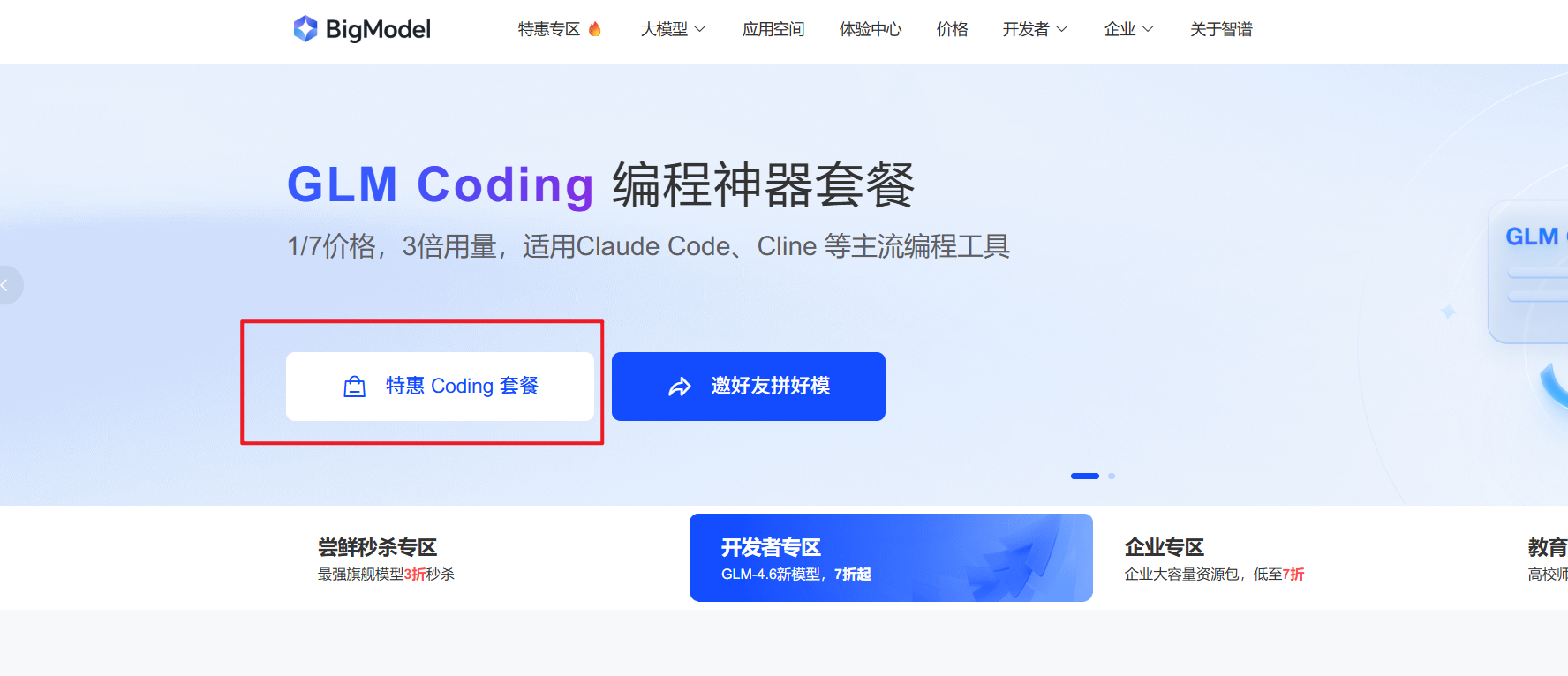
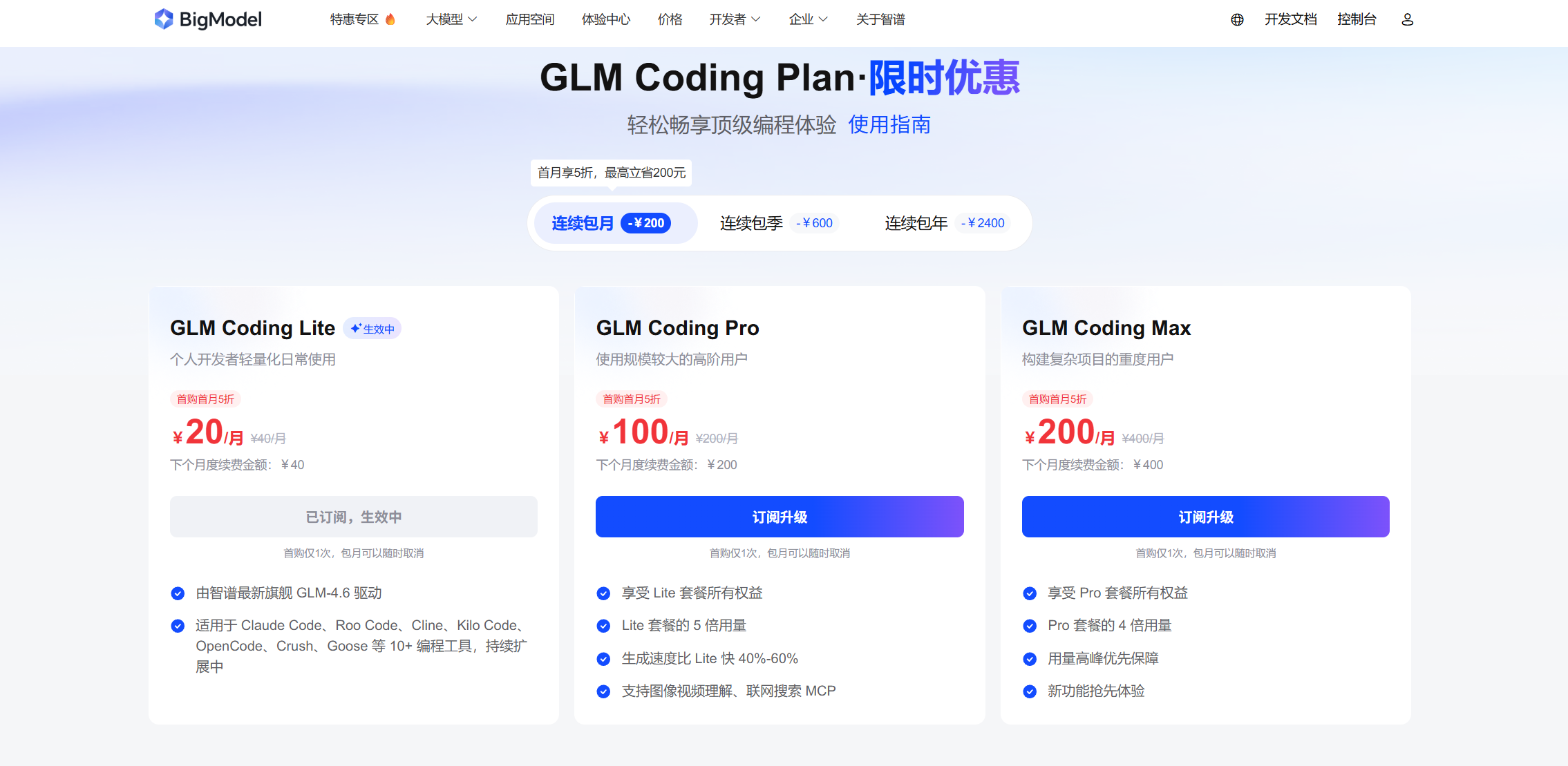
只是这个20的套餐稍微慢一点,不支持图像理解和联网搜索。
接下来,我们按照官网的指南进行
Claude code的配置。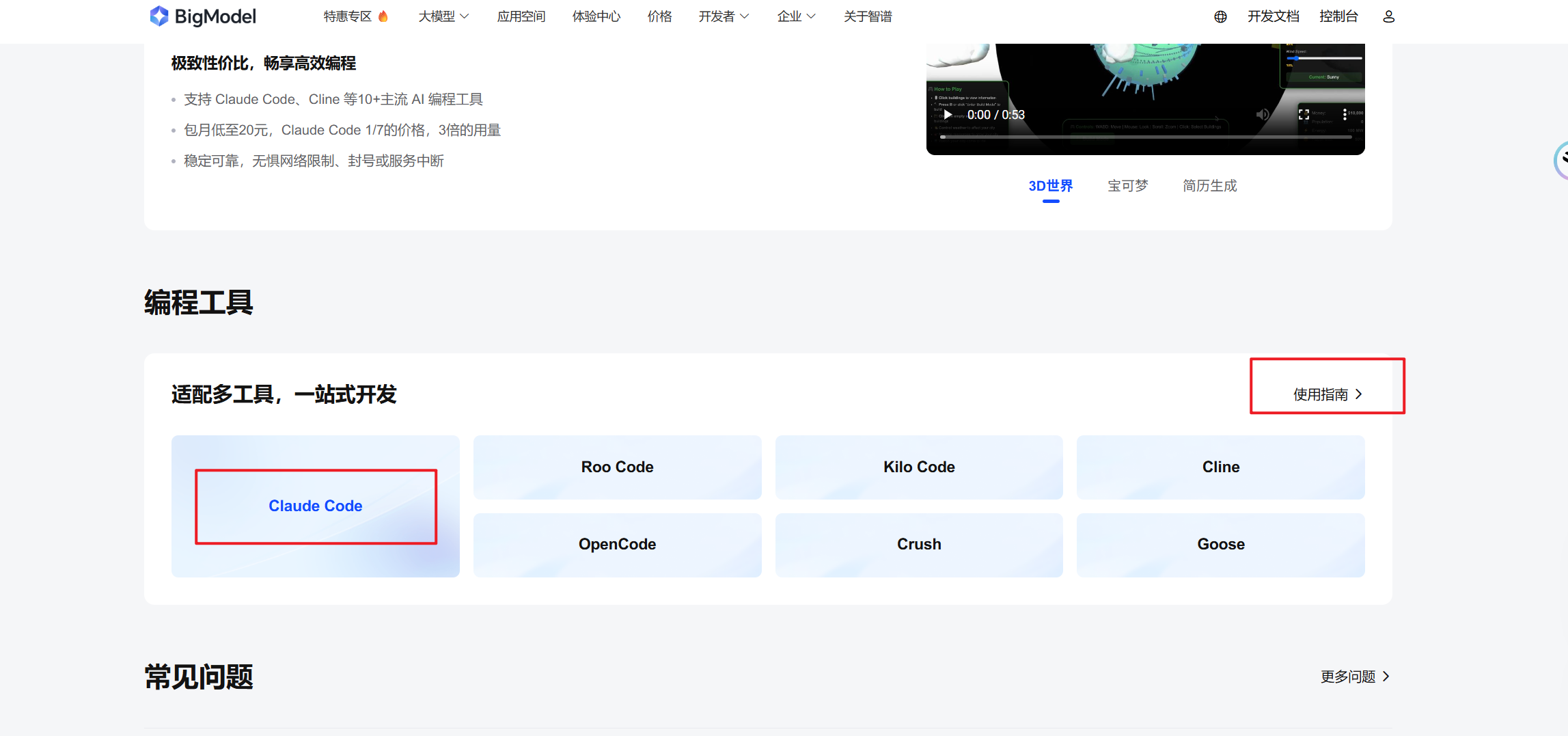
这里有3种配置方式,第1种是手动配置,修改环境变量即可:
Env:ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
Env:ANTHROPIC_AUTH_TOKEN="your_zhipu_api_key"第二种,在claude的目录手动创建一个
settings.json文件: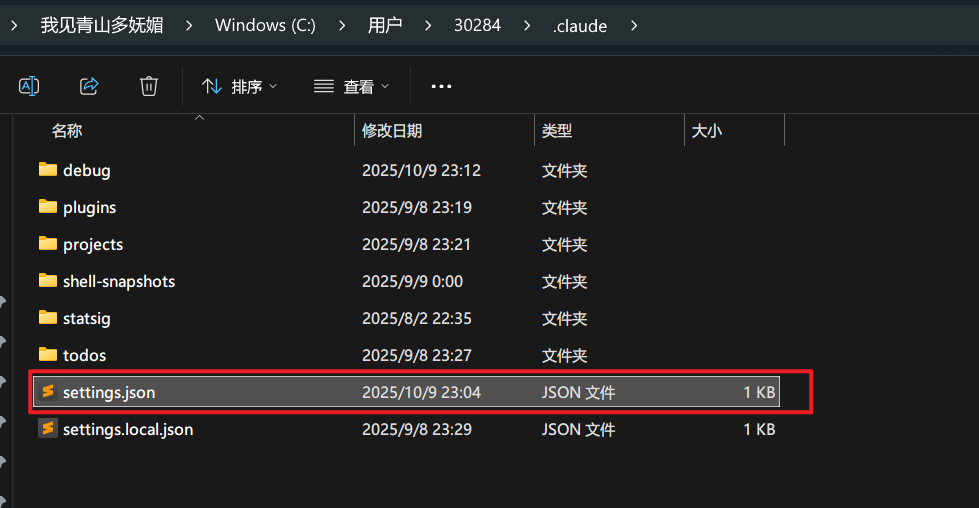
然后打开这个文件,将我下面的配置输入进去,修改为你的apikey:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你的apikey",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.6",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.6"
}
}上面借鉴了官方的配置,可以切换模型。
第三种,就是像我下面一样折腾:
我是win11,所以我需要打开cmd,直接在搜索输入cmd,或者输入win+R,再输入cmd,打开cmd,注意是cmd不是powershell。
然后复制下面的命令,点击右键:
curl -O "http://bigmodel-us3-prod-marketplace.cn-wlcb.ufileos.com/1753683727739-0b3a4f6e84284f1b9afa951ab7873c29.sh?ufileattname=claude_code_prod.sh" |
显示下面的内容就成功了:
C:\Users\30284>curl -O "http://bigmodel-us3-prod-marketplace.cn-wlcb.ufileos.com/1753683727739-0b3a4f6e84284f1b9afa951ab7873c29.sh?ufileattname=claude_code_prod.sh" |
这时候,你进入C:用户/你的用户名就可以看到这个bash文件。比如我是这个目录:C:\Users\30284

然后我们执行这个文件,这个吧,就比较有意思,还得用git bash执行,或者使用安装了linux子系统的win。因为我只装了docker,所以搞起来比较费劲,我就直接使用git了。
我们直接在这个目录空白的地方,shift+右键,选择open bash here,然后输入bash 1753(tab键补全即可),然后就会开始运行脚本,提示让输入秘钥:
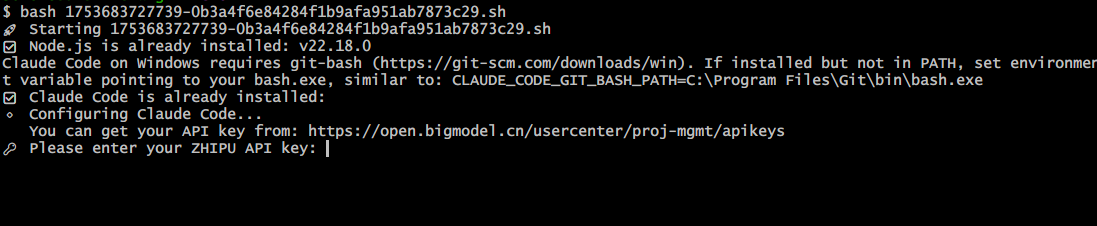
我们去创建一个秘钥,并且复制:
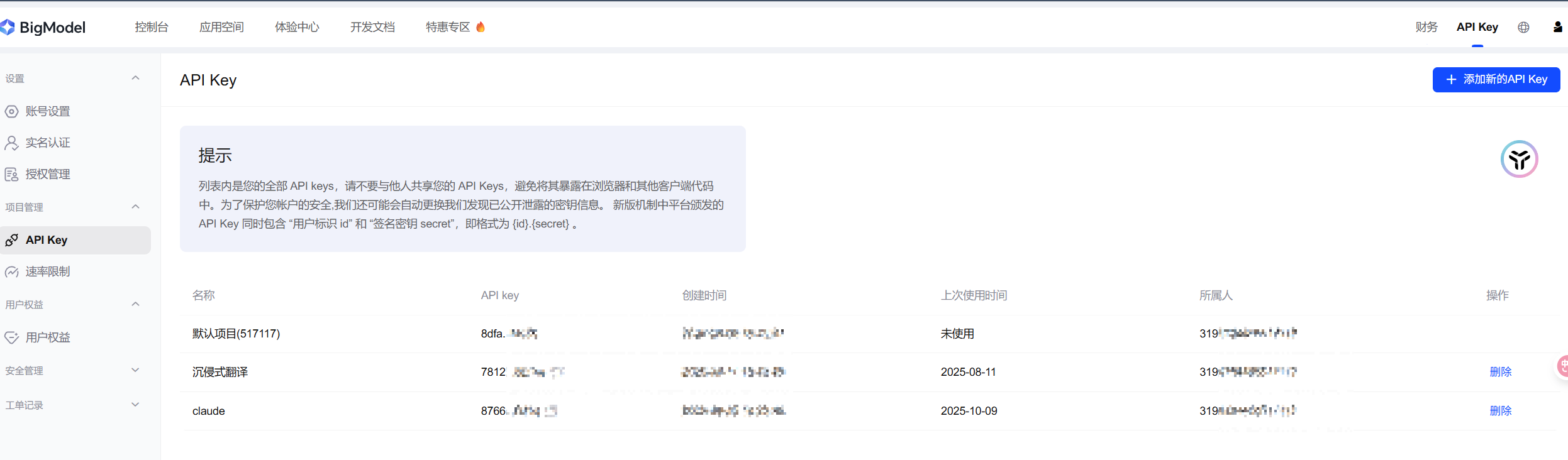
然后回到bash,右键,回车,即可。右键点击不会显示输入的秘钥,但是实际已经输入了。我们回车后,就会成功的。
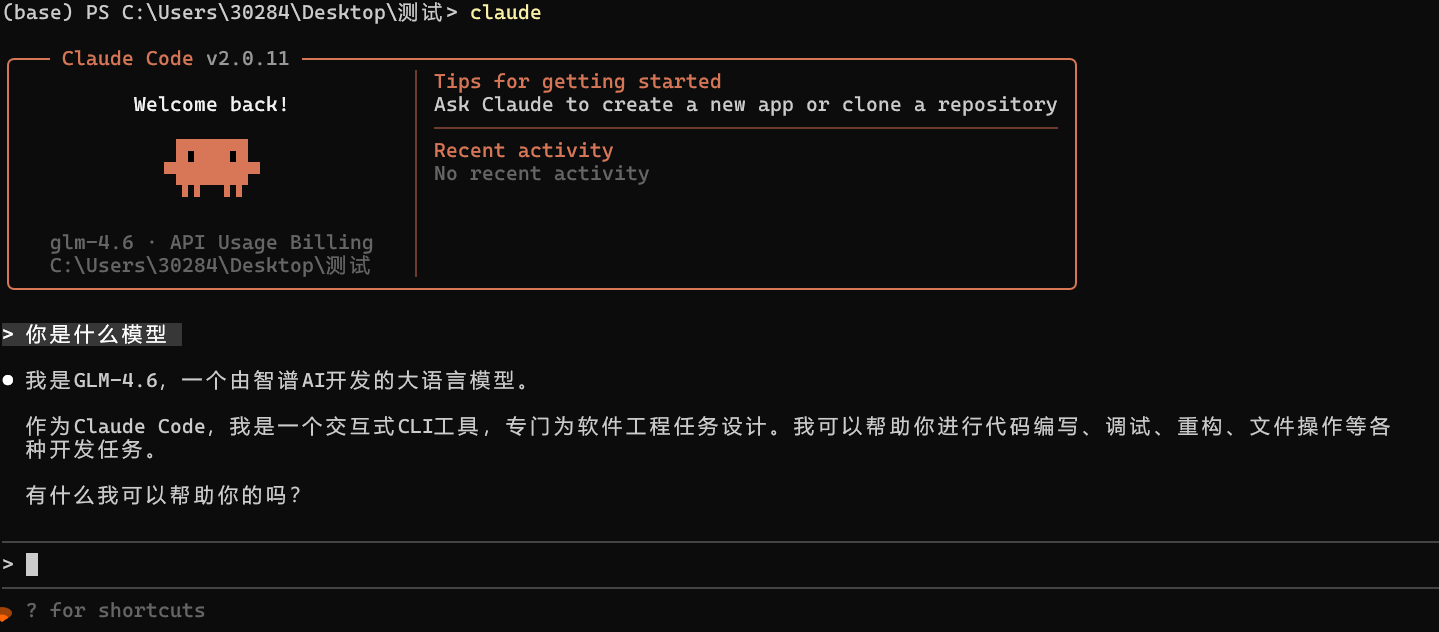
到了这里,claude code的基本配置已经完成了,大家已经可以开始使用了,但是为了用的更好,我们还可以继续以下步骤。
MCP配置
在这里,我给大家推荐我常用的几个mcp服务,配置命令分别如下:
claude mcp add playwright -s user -- npx @playwright/mcp@latest # playwright浏览器自动化测试工具 |
chrome-devtools这个mcp服务,绝对有必要单开一个,从我的使用感受上来说,要比playwright工具要好用。。
我们可以使用claude mcp list命令,来看差安装的mcp服务是否正常运行。
(base) PS C:\Users\30284> claude mcp list |
我强烈建议大家去阅读官方文档,多学习claude code的高阶技巧。
Claude Code overview - Claude Docs:https://docs.claude.com/en/docs/claude-code/overview
Agent配置
claude code还有一个非常强大的地方,他可以使用不同的agent来完成对应的专门任务,这里,我们安装一个github上的高分agent合集。
打开claude code,输入:
等待安装完成即可。
我们可以在命令行输入/agent,来查看已经有的agent。
至此我们已经基本完成了所有的配置,我们可以开始做事情了,什么工具都是要多用才能熟悉。
小福利200美金-claude4.5使用
这里再给大家推荐个小福利,下面的网站,只要注册,就有200美金的claude4.5使用额度。
关于配置方式,大家可以查看官网接口文档:
2. 做一个wallpaper壁纸吧
大家要是放心的话,可以使用yolo模式启动claude:
claude --dangerously-skip-permissions #跳过所有权限认证,运行中就不用会在要授权了 |
需求文档生成
首先我们使用kimi或者其他AI生成一个需求文档。
我的输入相当随意:
我想设计一个番茄时钟的壁纸,计划在Wallpaper Engine中运行,请给我一个需求文档。我理解需要学习时长设置、休息时长设置,然后可以在桌面上显示。毕竟是番茄时钟,桌面是不是还是一干净为主比较好。还有界面的logo什么的,我寻思可以使用svg绘制。另外是不是应该有几百条的随机鼓励的语录,可以选择不同的风格,这样就会显示不同的语录,比如正经的,邪修的,等等,或者自定义。但是我还是希望有一些鼠标交互的动画,不然就白瞎了Wallpaper Engine的强大能力了,还有通知选项,例如音乐通知什么的。 |
然后他就给了我一个需求文档,我看了看没有什么大问题,基本符合初版要求。

番茄时钟壁纸开发
新建一个项目文件夹,我们就叫番茄时钟-20251011。
首先我们,让claude code使用context7的MCP服务,查询并生成wallpaper web壁纸的开发规范。
使用context7工具,查询wallpaper engine 的web壁纸的开发要求,并生成web壁纸的开发规范。 |
紧接着,他就开始查询并生成了开发规范:
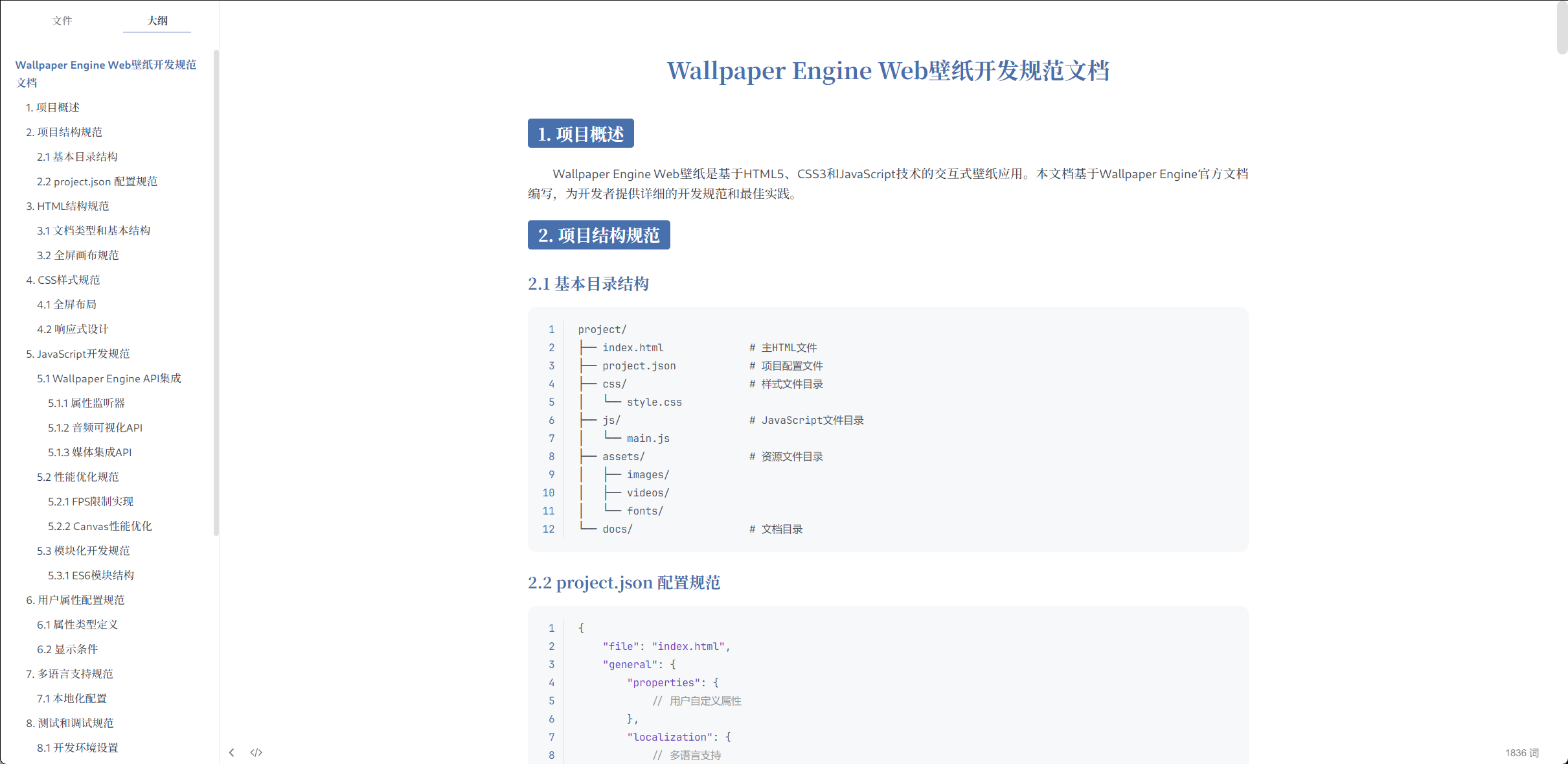
这里其实有一个点,我最后发现我被glm4.6坑惨了。就是项目的结构问题。
接下来,我们让它根据需求文档和开发规范,制定详细的开发任务:
请仔细阅读中的具体需求内容,并严格遵循中规定的技术标准与设计规范以及UI设计文档的要求,启动项目开发工作。首先需明确技 |
然后,我们可以依次让他按照开发任务开始开发。
谨记,我们使用AI开发,要小步快走,不要奢望一口气吃撑一个胖子,即便是我们这么简单的一个项目,步骤拆得越细越好。
即便是claude code已经足够厉害。
我们也要开发一个模块,就进行一次测试。
另外,我们还可以让claude code在本地建立git,使用git进行版本保存,每次开发在开发分支,测试完成再合并到主分支。
在测试阶段,我导入wallpaper中测试的时候,怎么都不出现配置项。
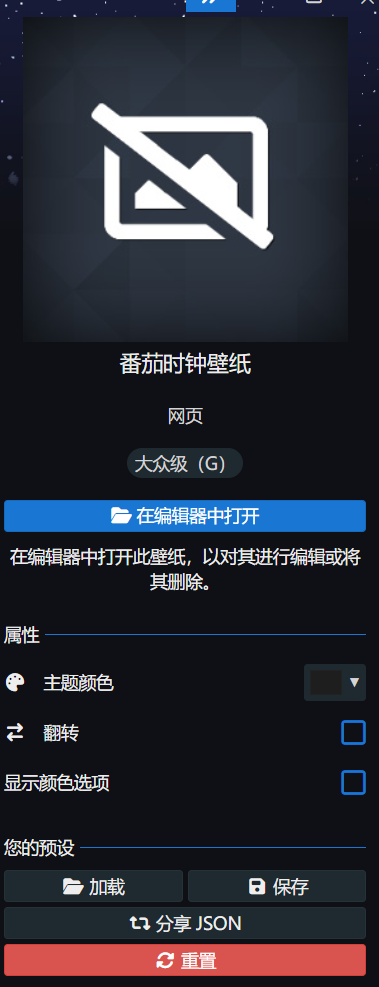
最后没招了,我找了gemini,自己又去阅读了官方文档,才发现,官方要求的项目结构是:
项目根目录/ |
这可真给我坑惨了。让我浪费了1个多小时的时间,无语。
后来我又用其他IDE使用了context7,生成开发文档,发现都是正确的,那就证明context7是没错的。
GLM4.6 坑惨了我。
最重要,开发文档里面的示例代码都和官方的不一样。我是真不明白啊。这里我用它生成了两次开发文档,竟然是一样的结构。。。
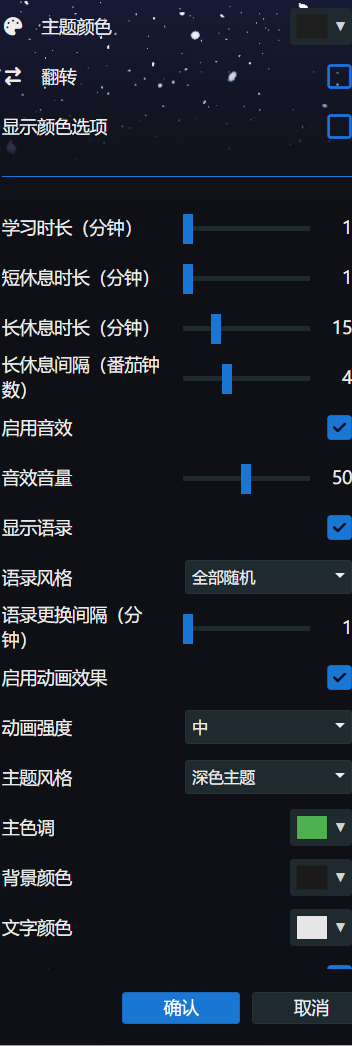
所以说,如果最开始错了,那我们的结果只能是错的。我又从头全部重干了一遍,一个特简单的事儿,愣是搞了小一天时间。
我们还是得保持我们的习惯,把这个AI生成的内容,让另一个AI审核一遍。
效果展示
这个项目很简单,要不是上面的坑,我估计2个小时最多了………..
主要实现了下面的功能:
### 核心功能 |
效果展示:
- 体验小结
总体体验下来,claude code确实是厉害的,我就是用你。对于模型而言,感觉GLM4.6还是有不小的进步空间,但是对于我们处理日常工作,写几个脚本,这种简单性的操作是绝对没有任何问题了,而且它的工具调用几乎没有出过错。。大家可以扫我这个二维码进行注册,让我也薅点羊毛,哈哈。