你的 RAG 还在“垃圾进,垃圾出”?我用这套流程,把“废料”文档变成了黄金知识库

最近大家关注Dify的进展的话,应该知道它的版本更新直接从1.8.0—>2.0.1了。跨越了一个大的版本。它本次的主要更新就在于知识库构建的知识流水线。
我认为Dify2.0以后的知识流水线会极大地降低了构建知识库的门槛,未来也许能高效处理 80% 的相对标准的文档。
但是,仍然会有20%,还是要依赖于我们人来手动处理。
我们都知道,现阶段来说,对于知识库,仍然是一个垃圾进垃圾出的状态,因此,在构建知识库之前我们需要对知识文档做很多的预处理。
今天这篇文章的分享,其实也是想给大家分享下我们自己手工处理文档的数据清洗思路。
1. RAG知识库的瓶颈
知识库的质量不取决于模型,而取决于“垃圾进,垃圾出”的铁律。真正的瓶颈是ETL(抽取、转换、加载)过程,尤其是从非结构化源文档到结构化知识块(Chunks)的转换过程。
我们每个公司其实私有的数据量,私有的文档是非常庞大的,而它的内容又是千奇百怪的。针对一个合同,就可能有几十几百种格式,所以指望一套流程来完成这个非结构化源文档到RAG知识库的转变基本是不可能的。
我们如果想偷懒直接将某个文档上传到RAG知识库,就希望他回答的100%准确,那是不可能的。因为用户的问题是多种多样的,而所谓的知识库检索过程,说到底就是一个取一个数据库里面,找与问题最相似的文本内容。但是,你要知道,这极有可能是找不到的。
就像原来的bert,为什么当时一个标准问后面要跟着那么多的相似问,就是因为怕只根据一个相似问,找不到对应的标准问。因为相似问和标准问在文字上可能其实没什么关系。
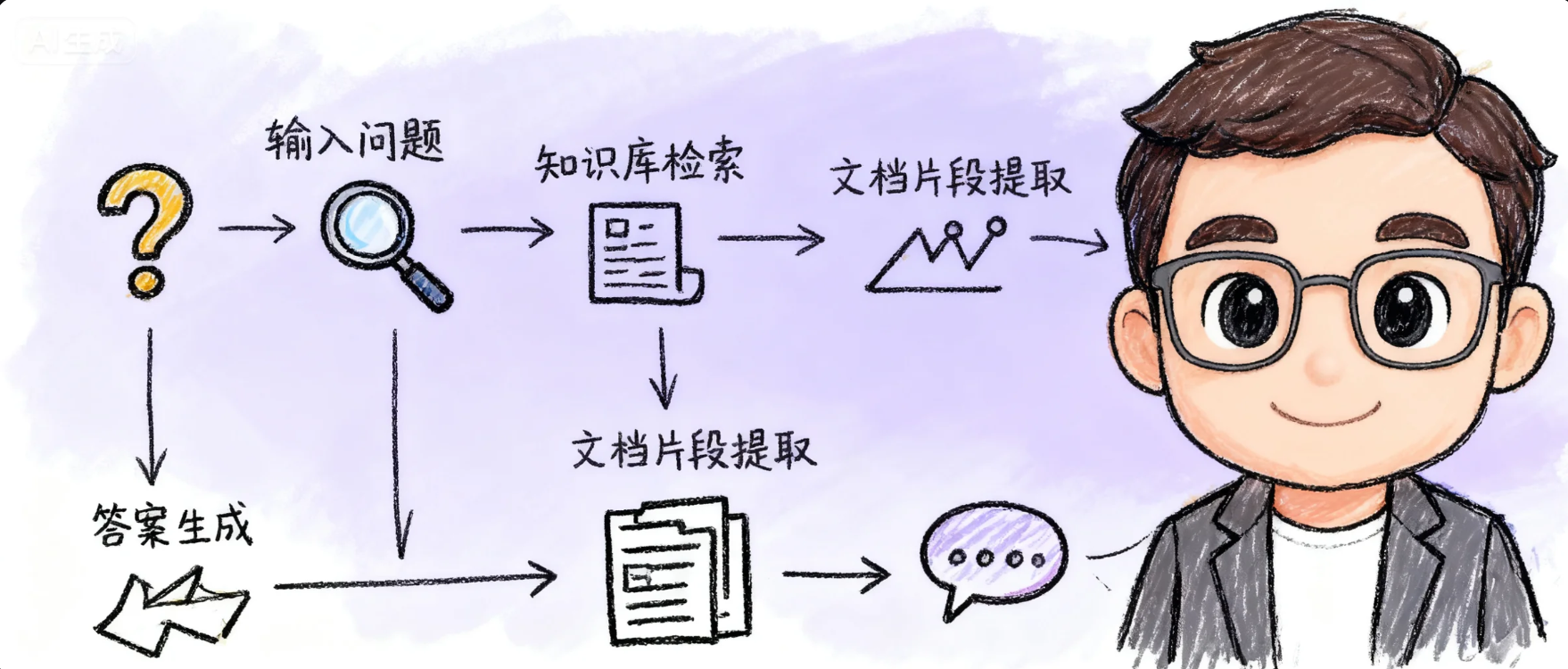
2.我的RAG清洗和构建思路
在Dify2.0的知识流水线出来以前,其实我自己已经构建了一套初版的RAG知识库构建流程。整体的思路,大概是下图中的流程。

下面我想重点和大家聊聊我这套流程的整体思路。这套流程,本质上其实也是为了避免垃圾进垃圾出。
文档格式转换
这里为什么要将类似于pdf文件或者docx格式的文件转换为markdown格式呢。主要的原因就是大模型对于md格式或者json等相关的格式,在识别上有天然的优势。而且md格式,本身对于图表,图片的处理也相对比较优雅(一般对话聊天窗口的前端都是支持对markdown格式进行渲染的,所以图文混排会比较好实现。)。

在这里,其实我面临的问题是有大量的docx文档,其实他们的格式相对比较统一,所以我就和AI去讨论,我应该怎么将他们转换为md文档。
AI其实推荐了4种工具:pandoc,python-docx库,unstructured,MinerU。
最后我选择了瑞士军刀pandoc,因为它相对来说没有那么麻烦,而且已经可以解决我的问题。
Pandoc :https://pandoc.org/
大家有兴趣的话可以去官网看下它的介绍,他还是非常强大的。
当然,因为我这里是批量转换,所以使用它的时候,需要写一个脚本,也是需要一点点的代码基础的,不过我不会,但是我们可以让AI来搞。
我的需求就是让AI帮我写一个win的shell脚本,可以将同步路中的docx文件输出到一个指定的文件夹。很快AI就可以写完这个代码。
我们使用国内的Trae可以很轻松的完成这个任务。
脚本相对比较长,我就不全都贴出来了。大家有兴趣的话可以联系我交流一下。
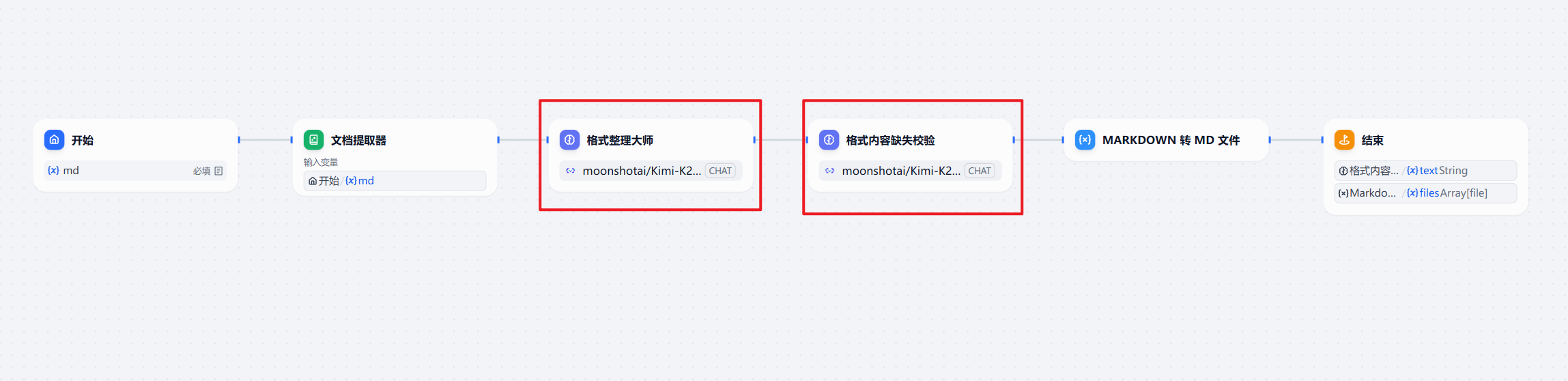
文档格式深度整理

因为本身我的文档每个内容不是特别多,基本不会超过5000字,但是数量又特别多,而原始文档,其实很多人都没有很好的用word的样式对标题等进行格式化。且有的语义相对比较乱,所以我在这里使用大模型帮我对文档的格式进行了进一步的整理。
这一步,本身的目的是为了为后续构建RAG知识库的父子分块做准备。
我统一去掉了一级目录,计划使用二级目录##和三级目录###,分别作为知识库的父块和子块。
大模型对md格式理解相对是比较深的,所以我们这一步使用大模型来做这件事,其实是ok的。
这里我用了一个格式整理节点,和一个内容缺失校验的节点。来保证它整理结果的正确性。当然,我们在他整理完成以后,抽查一下,更加稳妥。
毕竟模型存在幻觉。
问答对生成

无论是什么样类型的文档,只要是计划做类似于智能客服类型的服务,QA问答对,是保证回复正确性的一个神器。
尤其是对于保险公司内部的核保助理、合规咨询助理、人力行政助理等等相关场景的落地。
这里我们可以继续使用大模型来帮我们做这件事。和上面的工作流类似:
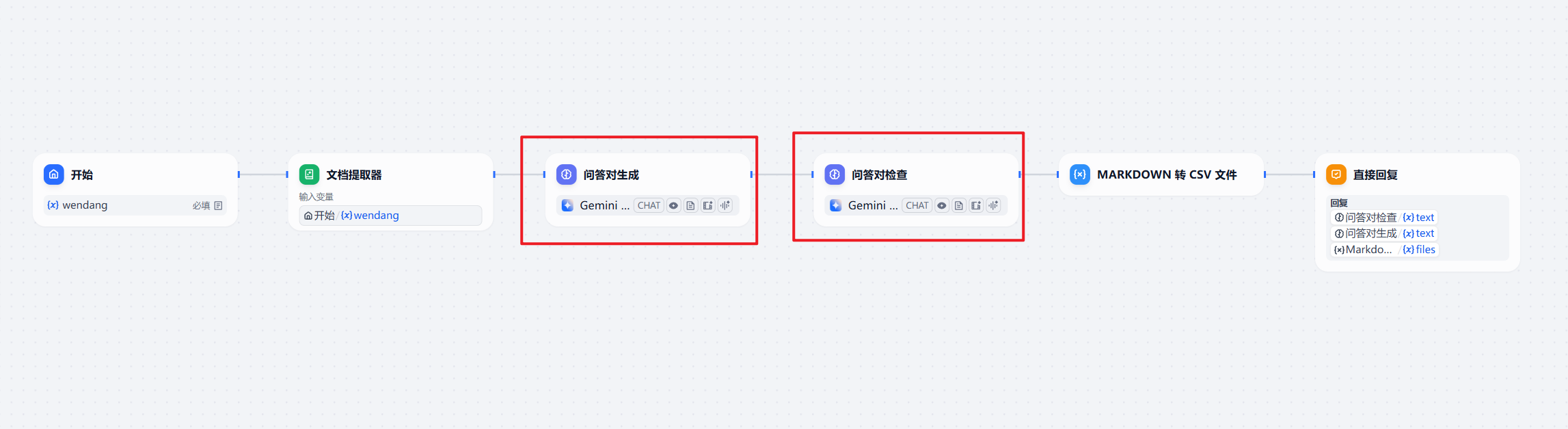
我们还是使用一个大模型节点来生成问答对,另外一个节点来进行检查,这样可以尽可能的降低错误概率。
当然,这一步和上一步,相对来说是比较重要的,每次完成以后,最好是可以人工来进行一下审核。
自动化测试

当然,上面的准备工作完成以后,这一步,应该是做知识库的导入及构建。
这块就没有什么特别特殊的内容了,我就不详细说了。因为本文主要讲的还是思路。
对于我们构建的咨询助手来说,即便知识库非常强大了,也是难免会有遗漏的地方,所以我们还需要进行充分的测试。
在2022年以前,我们的测试工作,相对来说还是以人为主,冷启动的时候,一般都是找公司内部人员,抽时间让他们大量使用,然后进行人工标注,优化,训练,来完成内部智能助理或客服的系统升级,提高他们回复问题的正确率。
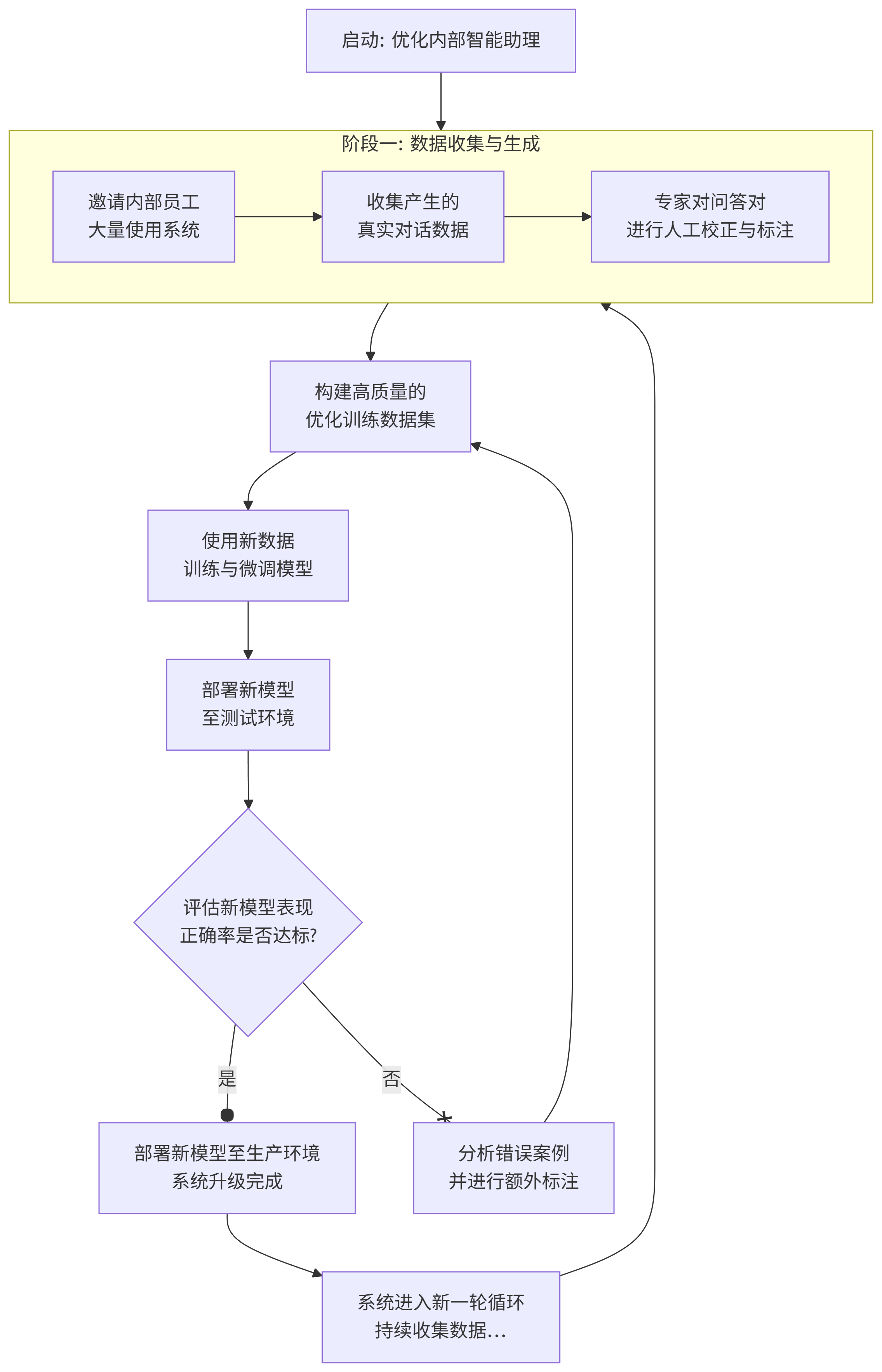
但是现在其实,我们可以让大模型帮我们完成80%的工作。
所以这里,我使用Trae又写了一个批量的chatflow测试脚本。这个脚本已经被我开源在了Github,目前的话,流式模式是好使的,Block模式还是需要继续优化。
它的主要功能如下:
批量测试执行: 从 Excel 文件读取测试用例,批量执行测试 |
有需要的话,大家自取,如果不会访问github,也可以联系我。
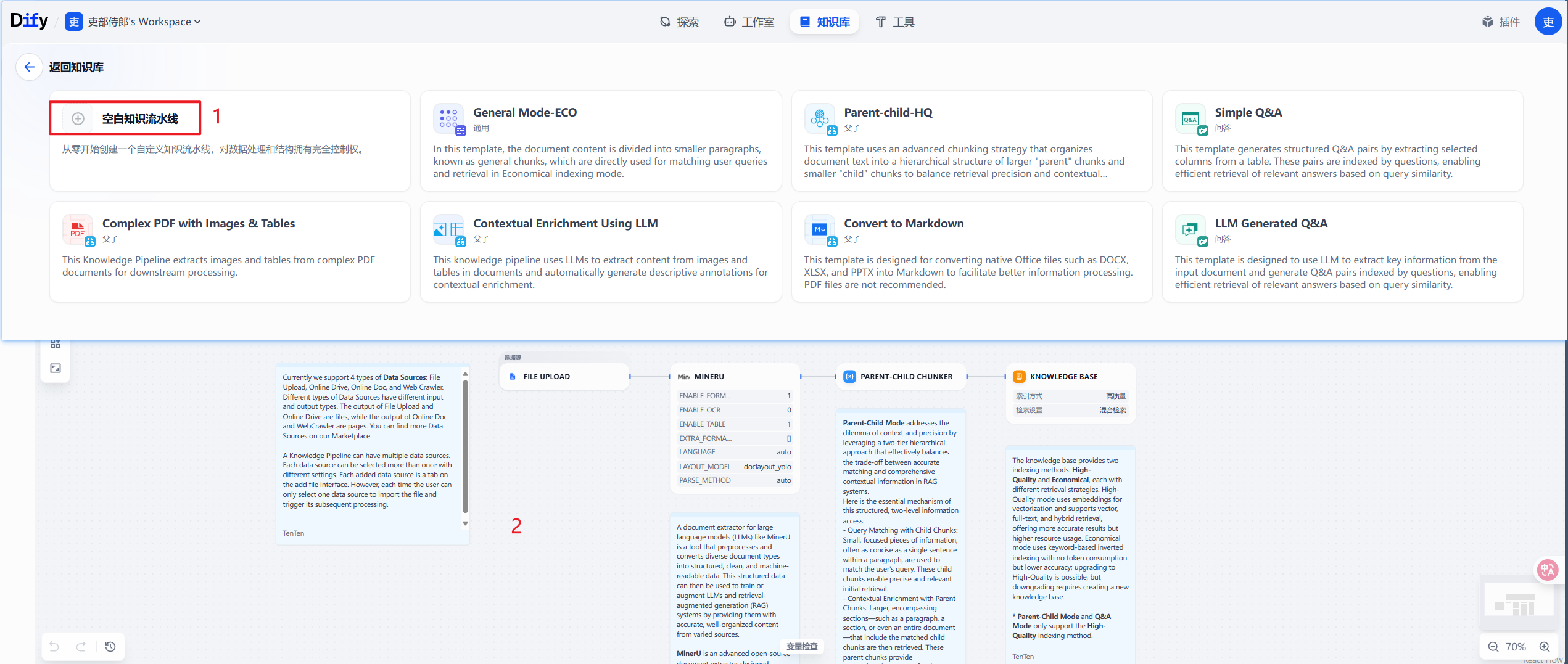
3. Dify2.0知识流水线

我们以dify知识流水线的QA生成为例,可以看到基本整体思路与我们前面所说的是一样的。但是它还只是一个样例,不具备生产落地性,我们还要在这个基础上做一些其他校验。

如果大家,掌握了我之前讲的RAG清洗和构思的思路的话,相信可以很快的理解Dify2.0版本中知识流水线的设计理念。
相信随着Dify的进一步迭代,知识库这里会越来越好用。这个版本,大家仔细看的话,就会发现官方其实发布了很多新的专门设计的插件,来为知识库的构建服务。包括但不限于:

目前2.0版本还处于beta阶段。
关于如何升级的内容,大家可以自行去网上搜索,或者阅读dify的github内容。
4. 小结
随着Dify的发展,也许未来不需要我们自己在线下这么折腾知识库的准备工作,完全可以把这个工作交给业务人员。
但是目前而言,还是需要的。
其实即便是我们自己折腾,最终目标也是让业务人员维护,因为IT维护,懂业务的人太少,时间成本太高。
但是万变不离其宗,产品的发展是为了更好用、易用。从头到尾,设计的整体思路,永远围绕着这个核心进行的。
谢谢你看完我的文章。